在之前的内容中我们曾介绍过 Reindex API,但只是一笔带过,今天我们同样不想去讨论 Reindex API 的具体使用,如果你对 Reindex API 使用方法有疑问的话,可以参考官方文档。我们今天的内容主要有:
- 了解 Reindex 的实现。
- 如何优化 Reindex 的执行速度。
- Reindex 优化实践。
一、Reindex 的简介
Reindex 可以将一个索引的数据复制到另一个已经存在的索引中,所以当索引的 Mapping 无法满足需求的时候,可以新建一个新的索引,然后将旧索引的数据迁移过去。例如增加索引的主分片、更改字段的分词器等需要重建索引的操作就可以利用 Reindex 进行处理。下面是一个简单的 Reindex 实例:
POST _reindex{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}}
如上实例,将索引 my-index-000001 的数据 Reindex 到新的 my-new-index-000001 索引中。
用于 Reindex 的源除了可以是索引外,还可以是已经存在的 alisa(别名)、data stream,并且 Reindex 的目标索引必须与源索引不相同,例如你不能 Reindex 索引 A 到它自己:
POST _reindex{"source": {"index": "Index-A"},"dest": {"index": "Index-A"}}
需要注意的是,Reindex API 不会帮我们设置新索引的 Mappings、主分片数量、副本数量等设置,所以索引进行 Reindex 前需要自己对新索引进行设置。并且 Reindex API 需要源索引的 _source 设置被打开:
PUT my-index-000001{"mappings": {"_source": {"enabled": true}}}
当然,默认的情况下 _source 是被打开的。简单了解了 Reindex 后,下面我们来看看 Reindex 的实现。
二、Reindex 的本质
如果你用过 Reidnex API 来重建数据量较大的索引的话,你会发现 Reindex 的速度其实慢得挺感人的。即使是在同集群上进行 Reindex,其速度也只有几 M 每秒,更别说是跨集群 Renidex 了。在我们进行 Reindex 调优前,我们先来看看 Reindex 的实现,正所谓知己知彼,百战不殆。
Reindex 会将一个索引的数据复制到另一个已经存在的索引中,那说白了就是对数据进行一读一写,而这里的读、写就是性能调优的关键!
1、Reindex 读操作的实现
对于数据的读取,其实最快的是将文件直接复制到对应的索引中,但细想一下这个其实不现实,例如,目标索引与源索引的主分片数量不一样那可怎么办?Reindex 操作是需要数据全量读取的,而数据读取操作用的是 Scroll。Reindex 具体实现的源码并不在 server.src.main.java.org.elasticsearch 目录中,而是作为一个 module 引入进来的:
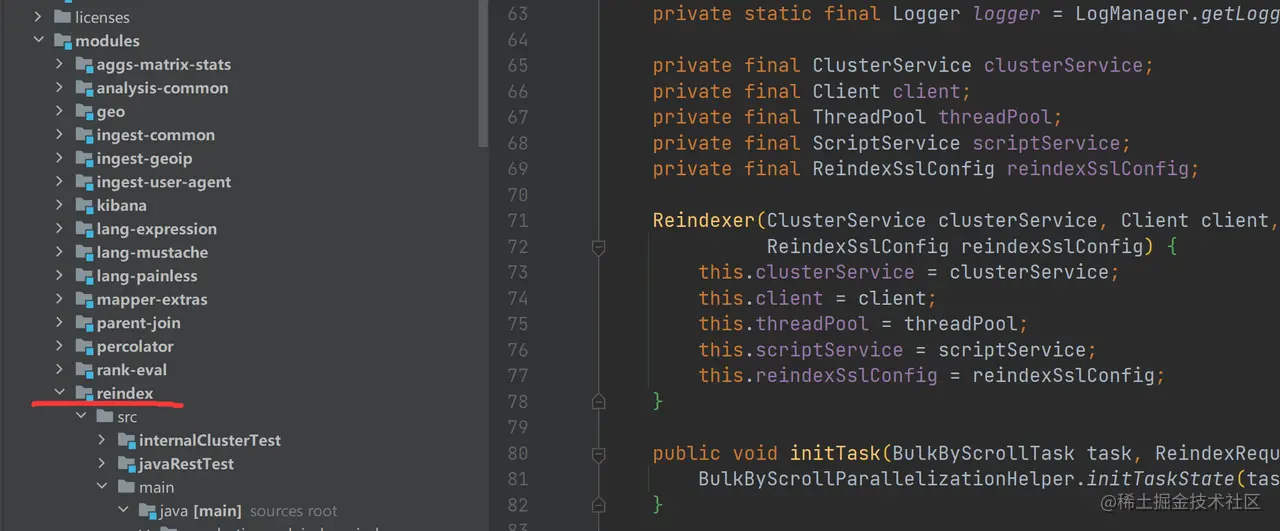
Reindex 具体实现的入口在 TransportReindexAction 的 doExecute 方法中:

如上代码,在 doExecute 中将 task 强制转换到 BulkByScrollTask,并且最后调用 Reindexer 的 execute 方法:
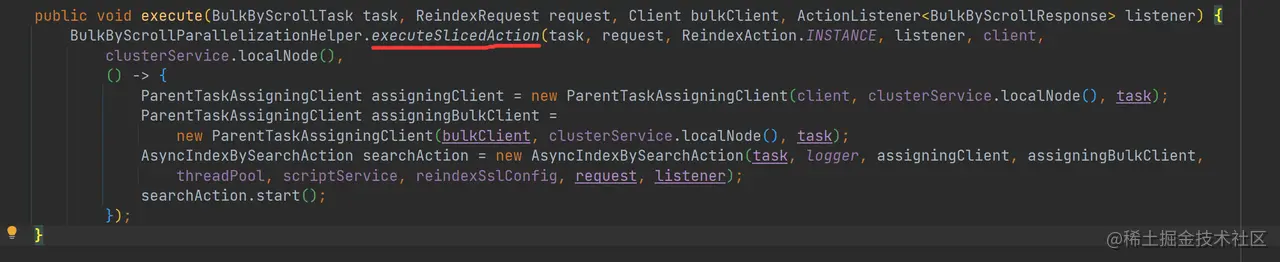
如上代码,executeSlicedAction 可以将任务切分,然后并行化获取数据。在每个并行化的操作中,启动一个异步的 searchAction 进行数据获取。对于任务的切分可以使用 slice 参数(slice 的详细用法本文后续会详细介绍):
POST _reindex{"source": {"index": "my-index-000001","slice": {"id": 0, // 切分 id"max": 2 // 切分的数量}},"dest": {"index": "my-new-index-000001"}}
至此,我们知道了 Reindex 读操作的底层实现是 Scroll,并且读任务是可以进行并行操作的。下面来看看写操作的实现。
2、Reindex 写操作的实现
对于写操作的原理我们在 《数据持久化:分布式文档的存储流程》和《源码阅读:写入流程》中已经有非常详细的介绍了,这里简单复习一下:
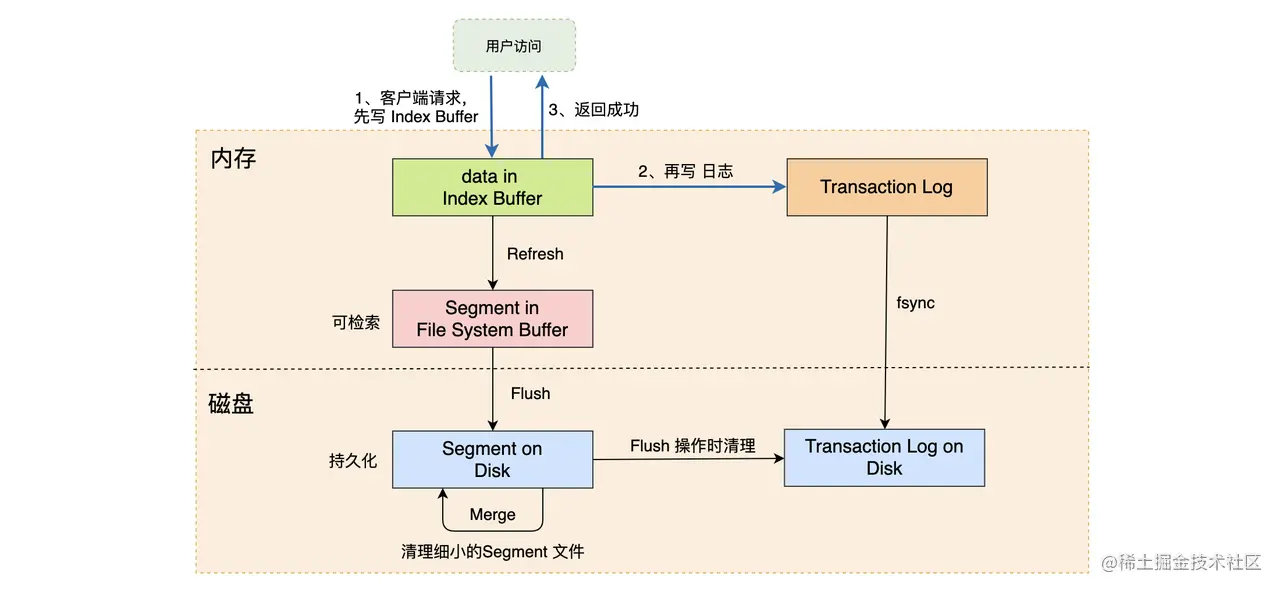
如上图,数据写入的时候先路由到对应的节点,然后将数据写入到 Index Buffer,再写入相关记录到 Transaction Log,并且返回成功。默认的情况下,Refresh 会每秒执行一次,将 Index Buffer 中的数据写入到文件系统中,并生成 Segment 文件。当达到触发条件时,系统还会进行 Flush 和 Merge 操作。
那读取出来的数据是如何发送到目标索引的呢?从 Reindexer.AsyncIndexBySearchAction 静态类的注释中可以看出是使用了 Bulk 请求:

如上代码,在 AbstractAsyncBulkByScrollAction.buildBulk 方法中会调用 AsyncIndexBySearchAction.buildRequest 构建 BulkRequest,然后发送请求到对应的节点中进行处理。
通过阅读 Reindex 的源码,可以发现,Reindex 读操作的底层实现是 Scroll,并且读任务是可以进行并行操作的,而写入操作是通过 Bulk 请求进行的。有了这些信息,下面我们就可以对 Reindex 进行优化,提高其执行效率了。
三、提高 Reindex 的效率
既然 Reindex 操作对数据是一读一写的过程,所以要提高 Reindex 的效率可以分别从读和写两个操作来进行优化。总结下来,Reindex 慢的原因可能有:
- 写的时候没有批量写入或者批大小有问题。
- 写入操作的参数没有优化好。
- Reindex 的读取操作是基于 Scroll 实现的,可以使用 Scroll 并行(Sliced Scroll )的方式进行优化,如果并行参数设置不对,可能会影响效率。
1、读操作优化
很显然,通过上述的总结,可以借助 Sliced Scroll 来并行读取数据。这种并行化操作可以提高 Reindex 的效率,并提供一种将请求分解为更小部分进行处理的方法。
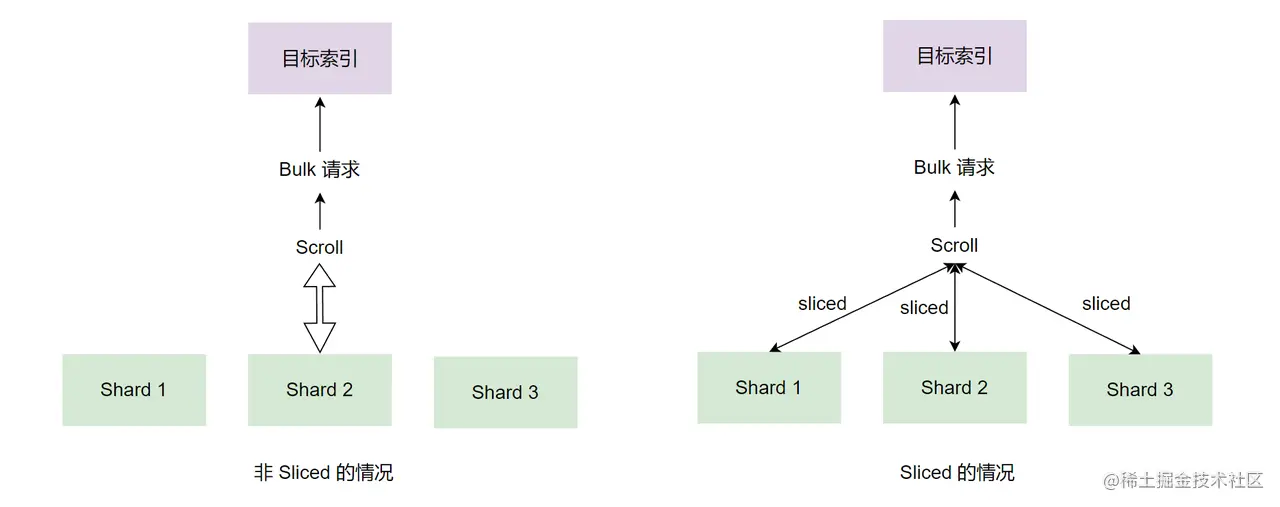
Slicing 有两种方式:手动设置(Manual Slicing)和自动设置(Automatic Slicing )。
手动设置(Manual Slicing)
// slice_id_1 的 SlicingPOST _reindex{"source": {"index": "my-index-000001","slice": {"id": 0, // slice id"max": 2 // 切分的数量}},"dest": {"index": "my-new-index-000001"}}// slice_id_2 的 SlicingPOST _reindex{"source": {"index": "my-index-000001","slice": {"id": 1, // slice id"max": 2 // 切分的数量}},"dest": {"index": "my-new-index-000001"}}
如上实例,通过在 “slice” 块中提供 slice id 和 slice 总数来手动设置 Slicing。上例中 max 为 2,所以需要手动执行两个 _reindex 请求才能把全部数据迁移到目标索引,其中一个 id 为 0,另一个 id 为 1。
自动设置(Automatic Slicing )
POST _reindex?slices=5&refresh{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}}
如上实例,通过在 URL 参数中使用 slices=5 来设置 Slicing 时的切分总数,默认的情况下 slices = 1。
虽然使用 Slicing 可以提高 Reindex 的效率,但如果使用不当,效果可能会适得其反。下面是几个 Slicing 设置的注意事项:
- slices 除了可以设定为数字外,slices 也可以设置为
auto,设置为 auto 表示:如果源索引是单索引,则 slices = 源索引的主分片数量值;如果源索引是多索引,则 slices = 各个源索引中最小的主分片数量值。 - slices 的值并不是越大越好的,过大的 slices 会影响性能。slices 的值等于源索引主分片数量值的时候效率会最高,当 slices 大于源索引主分片数量值时,不会提高效率,反而会增加开销,
总的来说,没有特定需求的情况下,slices 设置为 auto 即可。
2、写操作优化
写操作的优化跟我们在 《唯快不破:写调优》一章中介绍的方法差不多,主要下面这些:
- 选择合适的 Bulk 大小
默认的情况下,Reindex 执行写入的 Bulk Size 为 1000,可以设置 size 来调整 Bulk Size:
POST _reindex{"source": {"index": "source","size": 4000},"dest": {"index": "dest"}}
如上实例,我们设置了 Bulk Size 为 4000。对于如何选择合适的 Bulk Size,在《唯快不破:写调优》一章中有着非常详细的介绍,这里就不再赘述了。
- 设置目标索引的副本数为 0
减少副本数量可以提高写入的效率,在数据 Reindex 完成后,再设置你需要的副本数,这样系统会自动创建出需要的副本数。下面是设置副本数量为 0 的实例:
PUT /myindex/_settings{"number_of_replicas": 0}
- 调整 index.refresh_interval
减少 Index Refresh 的次数可以减少生成 Segment 的数量,也减少了 Merge 的频率。默认的情况下,ES Refresh 操作会每秒进行一次,可以通过调整 index.refresh_interval 的值来调整 Refresh 的时间间隔。
可以将 refresh_interval 设置为 -1 来关闭 Refresh,当然在 Index Buffer 写满时还是会进行 Refresh的:
PUT /myindex/_settings{"refresh_interval": -1}
需要注意的是,在 Reindex 完成后,需要把这个设置回原来的值。
- 加大 Translog Flush 的间隔
为了防止数据丢失,保证数据的可靠性,默认的情况下是每个请求 Translog 都刷盘。如果我们是在导入数据的应用场景,那么为了提高写入的性能,可以不每个请求都对 Translog 进行刷盘。
可以使用下面的示例来改变 Translog 的设置:
PUT /myindex/_settings{"index.translog.durability":"async","index.translog.sync_interval": "240s","index.translog.flush_threshold_size": "512m"}
如上示例,async 是指异步刷屏,每隔 index.translog.sync_interval 进行刷盘。当然,当 Translog 的量达到 flush_threshold_size 的时候也会触发刷盘。
ok,Reindex 的优化基本就这些,当然还有很多关于 Mapping、操作系统、JVM 等相关的调优手段这里没有提及,如果你忘记了,可以回顾 《唯快不破:写调优》。
四、Reindex 调优实践
说了那么多,这里我们简单跑一个实例来测试一下这些参数的效果。下面先交代一下我的测试环境,机器信息如下图:
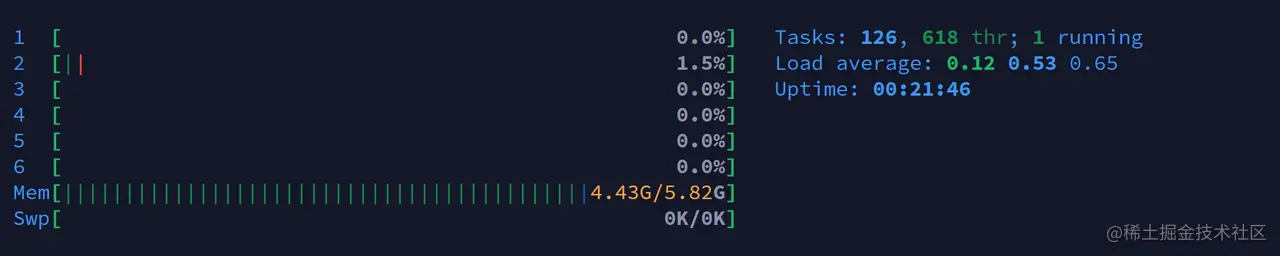
本次的实验环境的虚拟机性能比较差,用的是一台 6 线程,内存 6G 的虚拟机,磁盘为机械硬盘,系统为 Ubuntu 20.04,ES 是 3 节点的伪集群,-Xms 和 -Xmx 都是 512m。
本次测试使用的数据集为微信公众号语料库,我从这个语料库中抽取了前 4 万条,大约 160M 的数据(每条数据大约 4.2k)。
我们的测试并不是对服务进行压测,我们将会对比 Reindex 操作在优化前后的耗时情况。在开始前我们先处理数据:
- 创建源索引
// 创建源索引PUT articles{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_smart"},"account": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_smart"},"title": {"type": "text","analyzer": "ik_smart"}}},"settings": {"number_of_shards": 3,"number_of_replicas": 0}}
使用上述实例创建源索引,可以看到源索引的主分片为 3, 从副本为 0。
- 创建目标索引
// 创建目标索引PUT articles_new{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_smart"},"account": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_smart"},"title": {"type": "text","analyzer": "ik_smart"}}},"settings": {"number_of_shards": 3,"number_of_replicas": 1}}
使用上述实例创建目标索引,可以看到目标索引的主分片为 3, 从副本为 1。
- 导入源索引的数据
elasticdump --input=/home/spoofer/articles_dump_200M.json --output="http://localhost:9211" --type=data --limit=7200
其中 articles_dump_200M.json 文件是我根据微信公众号语料库前 40000 条数据创建的数据集,其内容格式如下(实际是没有换行的,这里是方便阅读进行了 json 格式化了):
{"_index": "articles","_type": "_doc","_source": {"date": "2016-04-02","content": "content......","account": "tianchengyishu001","name": ""天成"艺术品公共交流平台","title": "[天成]艺术精品公拍预展(4月2日 周六14:00)"}}
优化前的耗时:
由于此次 Reindex 操作耗时可能超过 30 秒,如果在 Kibanan 上运行可能会超时,所以我们直接在 cerebro 上运行实例,其 DSL 与对应的结果如下:
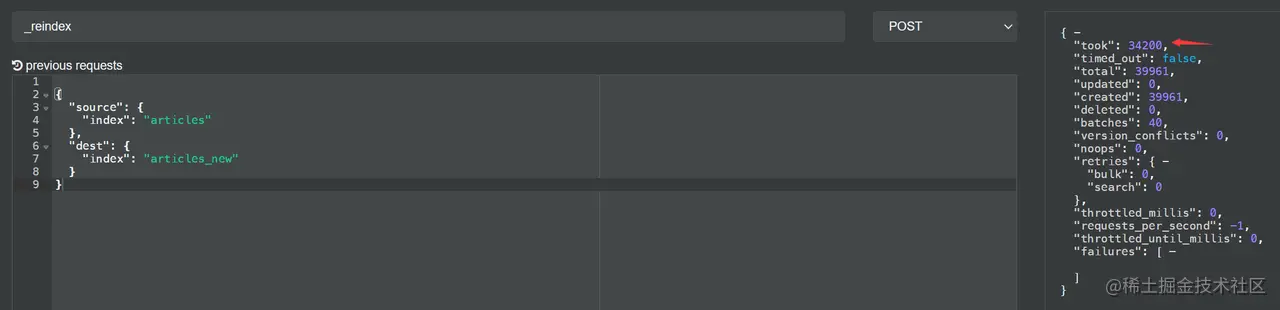
如上实例,我运行了多次,结果都在 35 秒左右。下面来看看进行调整后 Reindex 的耗时。
优化过后的耗时:
根据我们前面的介绍,我执行了以下命令,对设置进行优化:
// 删除 articles_new 索引DELETE articles_new// 重新创建 articles_new 索引// 调整设置PUT /articles_new/_settings{"number_of_replicas": 0,"refresh_interval": -1,"index.translog.durability":"async","index.translog.sync_interval": "240s","index.translog.flush_threshold_size": "512m"}
如上实例,我设置了副本数为 0,不进行 Refresh,甚至连 Translog 都不刷盘了(实际场景下要自己调整设置,我这里只是测试)。最终调整后的 Reindex 耗时如下:
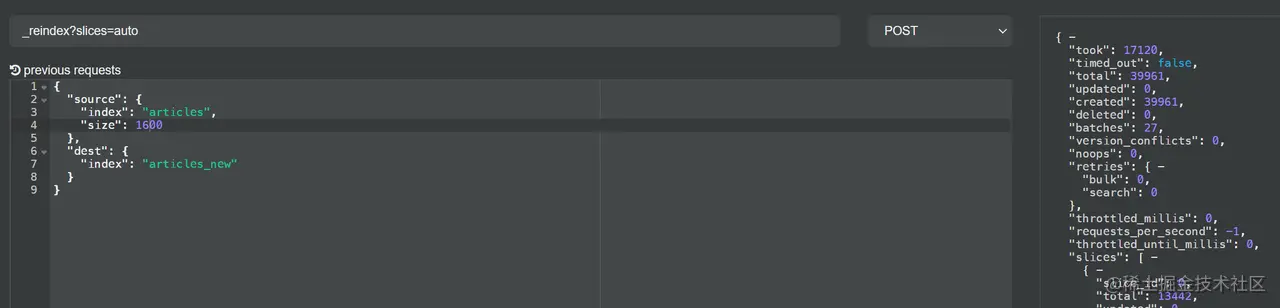
可以看到,17 秒的耗时确实比优化前的 35 秒快了不少。
在我的实验环境里,设置副本数这个参数的收益是最大的,达到 14 秒,Translog 相关参数的收益也有 4 秒。但是 slices=auto 和 Bulk Size 的收益却几乎看不出来甚至更慢了,我猜其原因可能是虚拟机性能不行,多个节点部署在同一台虚拟机上,产生了资源争用的情况,另外我测试的数据量不大,切分的批次少,收益的效果不明显也是正常的。
五、总结
今天我们简单地从源码层面查看了 Reindex 的实现,也从实际出发对 Reindex API 参数进行调优,并进行实践测试。
总的来说,Reindex 操作在读取阶段使用并行的方式可以提高效率,在没有其他特别的需求下,使用 slices=auto 时效率最高。在写入阶段,可以通过调整 Bulk Size、增加 Refresh 的时长、设置更少的副本数、调整 Translog 的刷盘策略来提高 Reindex 的写入效率。
