随着业务的发展,对系统日志的管理变得愈发重要,面对日志的管理我们会面临以下几个问题:
- 系统服务日志不够详细,一条日志只记录部分关键信息或者流水账太多。
- 服务出问题,只能 grep、awk 获取,多实例下简直是灾难。
- 日志太大,无法归档或者文本过滤太慢。
- 日志没有集中管理,一段时间后可能就被清理了。
- 多维度查询难以实现,时间节点不明确。
- 业务类型的日志多种多样。
上述的各种问题都很清晰,但我遇到过最奇葩的是,由于默认分配的虚拟机磁盘比较少,一个服务系统的日志几十个 G, 直接占满了磁盘,导致系统无法对外提供服务。
所以日志系统需要帮助我们解决以下的问题:
- 日志收集、传输、存储、归档,统一管理。
- 日志分析、问题定位、多维度查询等,支持 UI 操作。
- 日志分类、过滤。
今天我们就来使用 ELK 搭建一个简单的日志系统,ELK 是三个开源软件的缩写,分别表示:Elasticsearch、Logstash、Kibana,其中还没有提到轻量级的日志收集工具 Filebeat。以下是这几个组件的简介:
- Filebeat,轻量级的日志收集处理工具
- Logstash,主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上(这里用 Filebeat 代替),server 端负责将收到的各节点日志进行过滤、修改等操作存储到 ES 或者其他存储系统上。
- Elasticsearch,是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。
- Kibana,提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
所以,今天我们的内容有:
- 介绍 ELK 常见的架构与其优缺点。
- 各个组件的工作原理介绍和安装配置。
本章的内容实操性比较强,建议多动手多折腾,并且由于篇幅的限制,本章对于 Filebeat、Logstash 相关的插件的介绍和配置提及得非常有限,如果你已经自己搭建过 ELK 了就请跳过或者快速浏览吧!
一、ELK 常见的架构与其优缺点
下面将介绍几种常见的 ELK 架构,并且讨论其优缺点和适合的使用场景。
ELK 架构一
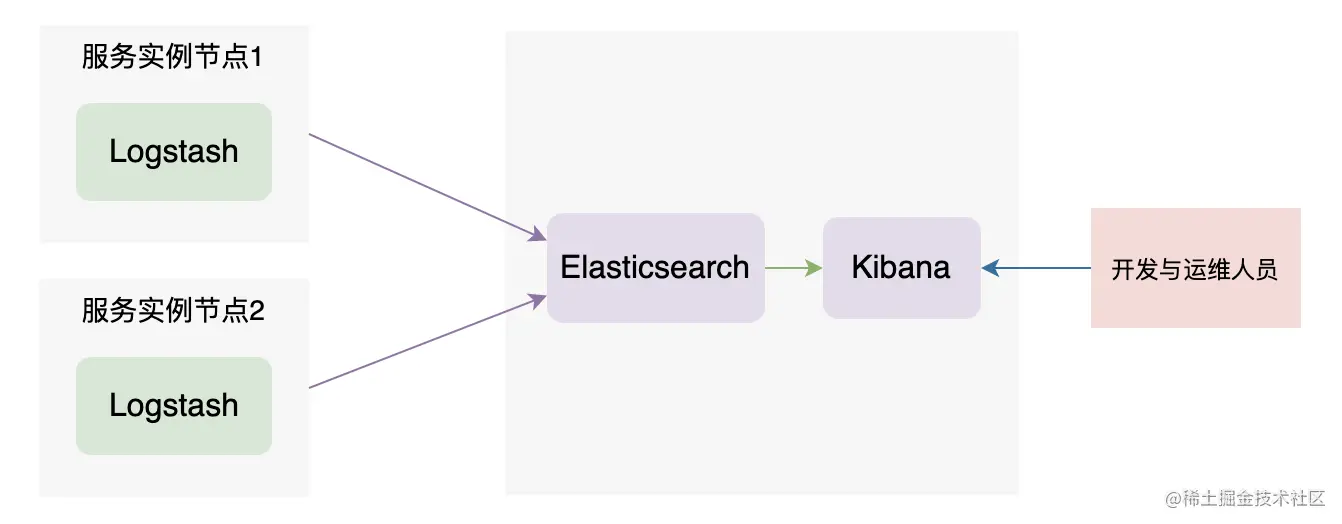
如上图,这是一种非常简单的架构,需要维护的组件少,安装搭建都比较简单,用 Logstash 直接采集服务的日志,然后储存到 ES 中即可。但缺点也是比较明显的,每个服务实例的节点上都需要安装 Logstash,需要消耗的资源比较大,有种用牛刀杀鸡的感觉。这种架构比较简单,是不足以支撑企业级业务运行的。
ELK 架构二
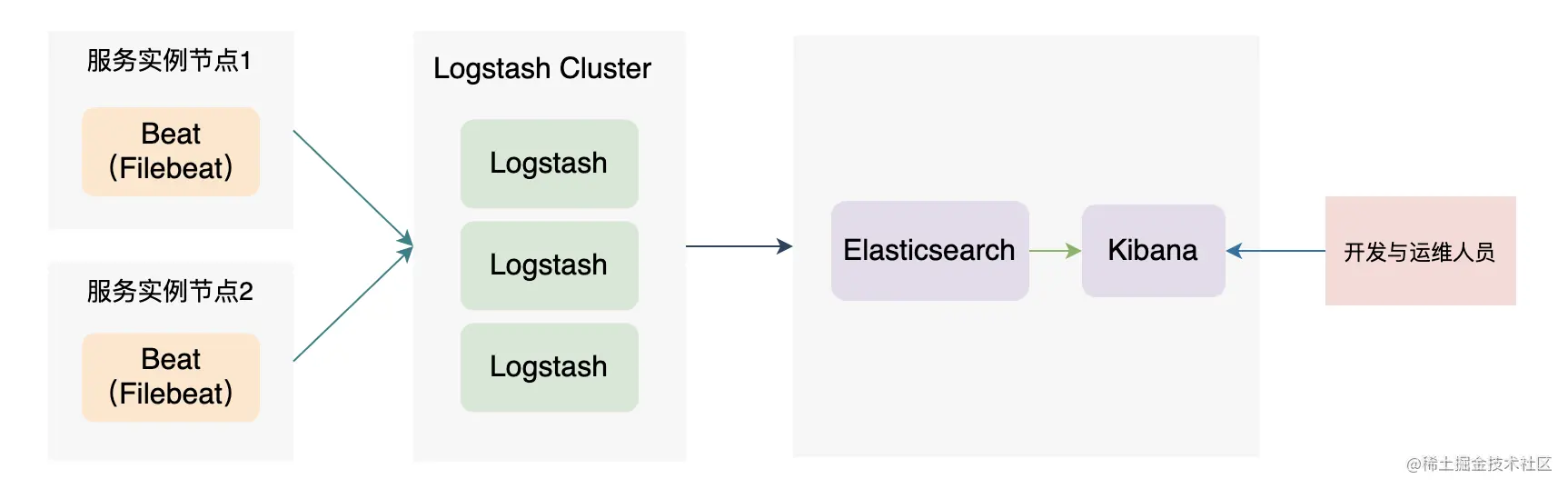
如上图,我们把采集日志的组件替换成了轻量级的 Filebeat,而日志处理的 Logstash 也以集群的方式组建。此时的架构功能上已经比较完整了,有 Filebeat 做日志采集,Logstash 做日志过滤、转换等操作、ES 做数据存储与检索、Kibana 做展示与交互。但是此架构没有消息队列,没法削峰、数据也会存储丢失的风险。
ELK 架构三
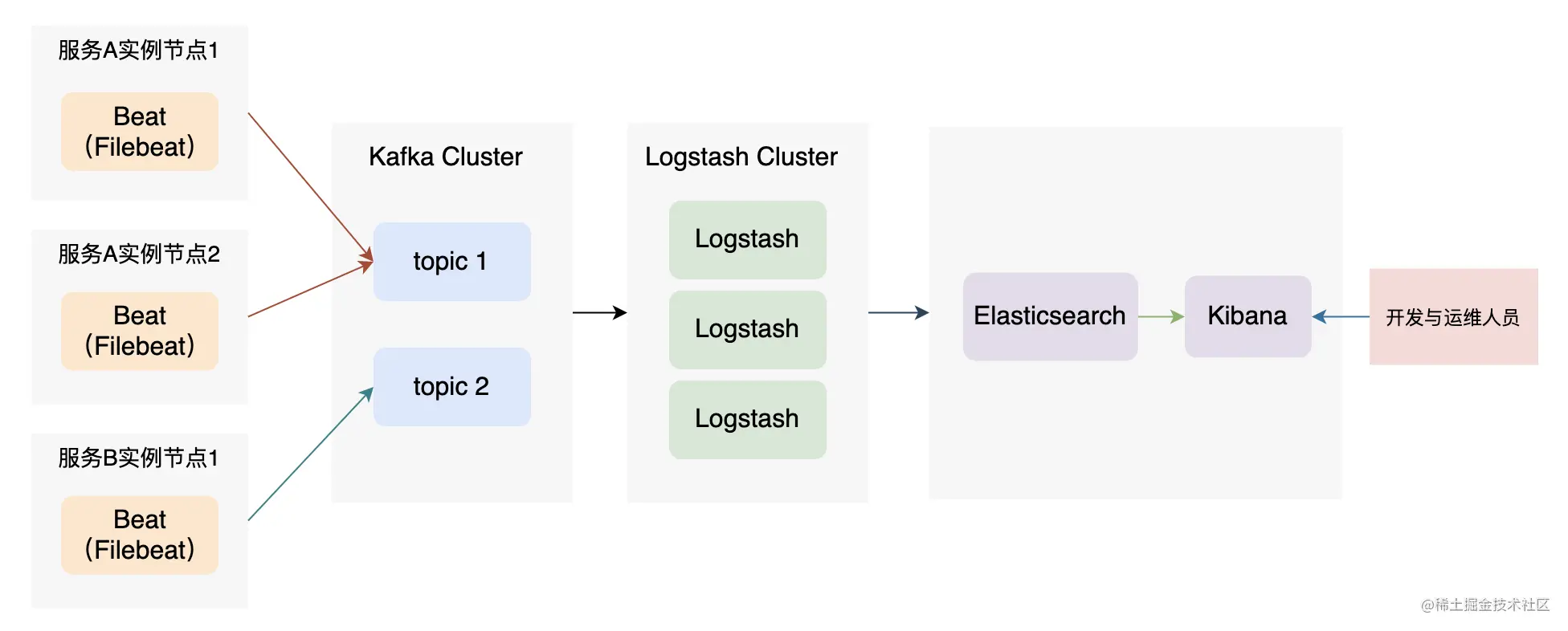
如上图,为了加强系统的稳定性,这里加入了 Kafka 组件,起到削峰、异步操作、日志重放的作用,可以避免数据丢失。可以看到,整个日志系统需要维护的组件有很多,是比较重的。但这种架构灵活、可扩展性也很强。如果需要,除了采集日志的 Beat 外,其他组件都可以以集群的方式进行部署,以支持大型系统日志数据的存储、监控、查询。而我们今天的目标也是要搭建这样一套企业级的日志分析平台,下面来看看各个组件的介绍和其安装配置。
二、Kafka 安装
Kafka在 ELK 架构三 这个架构里充当了消息队列,我们这里介绍一下单节点 Kafka 的安装,更多的信息你可以查阅 Kafka 的官方文档。
这里我们使用 wget 下载 Kafka:
# 使用 wget 下载wget --no-check-certificate https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz# 解压tar xvf kafka_2.13-3.1.0.tgz# 重命名mv kafka_2.13-3.1.0 kafka
如果下载速度很慢,你可以使用备份文件。Kafka 的配置比较简单,我们开箱即用就可以:
# 配置 config/server.properties :listeners=PLAINTEXT://localhost:9092
在 kafka/config/server.properties 中加入以上配置即可,更多 Kafka 调优配置你需要参考其官方文档了。
启动 Kafka:
function kill_all_app_by_name(){pid=`ps -ef | grep $1 | grep -v "grep" | awk -F" " '{print $2}'`for i in $pid; dokill -9 $idone}kill_all_app_by_name "kafka.Kafka"kill_all_app_by_name "QuorumPeerMain"./bin/zookeeper-server-start.sh ./config/zookeeper.properties >> ./zk.log 2>&1 &sleep 1./bin/kafka-server-start.sh ./config/server.properties >> ./kafka.log 2>&1 &
启动 Kafka 需要先启动 zookeeper,把上面的脚本写到 start.sh 里,然后使用以下指令启动 Kafka 即可:
# 启动 Kafkabash start.sh
ok,启动了 Kafka 后,我们来创建一个 topic 并且启动一个生产者生产消息,启动一个消费者消费消息。
创建 topic:
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic order_service
在一个终端中启动生产者:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic order_service
在另一个终端中启动消费者:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic order_service
启动了 生产者和消费者后,验证一下在生产者中发送消息,消费者是否能收到消息。
三、Filebeat 简介与安装
Elastic 其实提供了多个 Beat 来采集各种各样的日志、信息数据,我们把这些 Beats 称为 Beats 系列。官网上 Beats 系列现在包括以下几个:

上述这些 Beats 都有对应的中文介绍页面,已经非常详细了,我就不在赘述了。在这些 Beats 里,我们今天主要介绍 Filebeat。
Filebeat 是一个轻量级的本地日志采集程序,其可以监听和采集日志目录或者特定的日志文件,并将日志文件的增量转发给 ES、Kafka、Logstash 等外部服务。
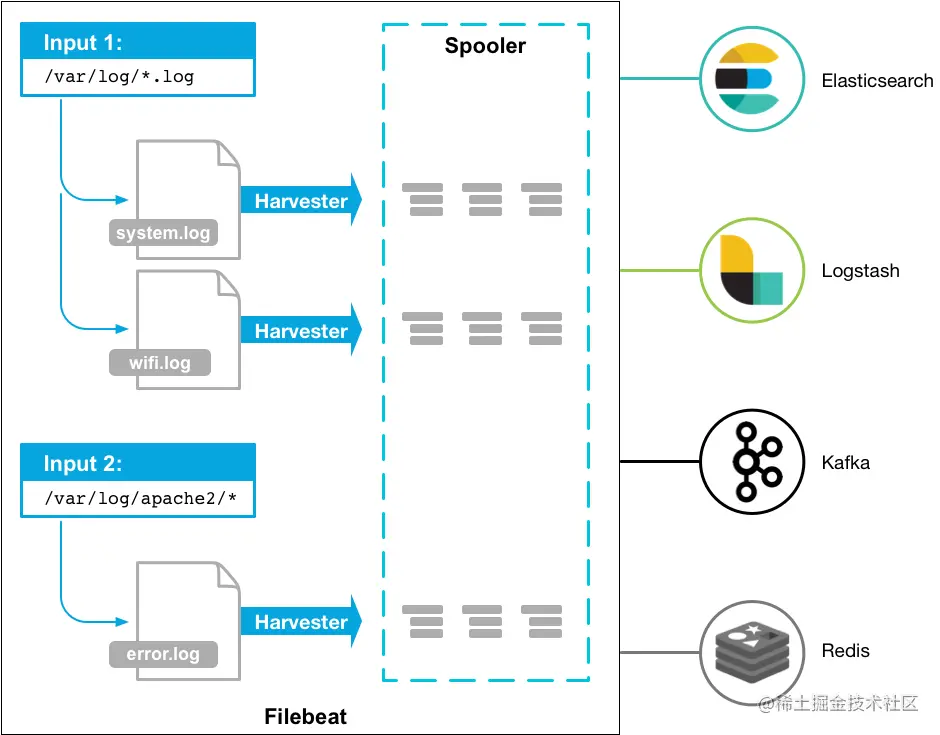
如上图,Filebeat 主要由两部分组成:Input 和 Harvester,当 Filebeat 启动后会启动一个或多个 Input 来查找本地日志文件。当找到一个需要监听的日志文件时会启动一个 Harvester 来监听和读取这日志文件的内容,并且发送日志内容到 libbeat,libbeat 提供了聚合日志事件和发送聚合后的数据到指定的外部服务的功能。其实每款开源 Beat 都以 libbeat(转发数据时所用的通用库)为基石,所以如果你需要定制一款自己的 Beat,官方其实提供了可用的 libbeat 给你扩展了。更多关于 Filebeat 的实现细节可以参考官方文档。下面我们来安装和配置一个最简单的 Filebeat。
# 使用 wget 下载wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.0-linux-x86_64.tar.gz# 解压tar xzvf filebeat-7.13.4-linux-x86_64.tar.gz# 重命名mv filebeat-7.13.4-linux-x86_64 filebeat
下面是一份 Filebeat 的配置:
filebeat.inputs:- type: logenabled: truepaths:- /home/ubuntu/OrderService.log # 改变到你的日志路径#fields:# level: debug# review: 1multiline.type: patternmultiline.pattern: ^\[multiline.negate: truemultiline.match: afteroutput.kafka:# initial brokers for reading cluster metadatahosts: ["localhost:9092"]# message topic selection + partitioningtopic: 'order_service'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000
先将原 filebeat.yml 备份后,删除 filebeat.yml,并且重新创建 filebeat.yml 文件,然后将上面的内容写入到 filebeat.yml 配置文件中。需要注意的是,你要修改需要监听的日志文件的路径和 Kafka 的地址、Kafka 的 topic(如果需要的话)。
下面是比较重要的几个 input 配置选项:
- multiline.type,默认值为 pattern,定义了使用何种方式聚合数据。pattern 是使用正则匹配,其他选项为 count,将会聚合指定行数的日志为一个事件。
- multiline.pattern,指定匹配日志的正则表达式,支持的正则策略可以参考官方文档。
- multiline.negate,定义是否否定 multiline.pattern 定义的正则,默认是 false。
- multiline.match,定义如何合并多行日志。可选项为 after 或者 before。
so,上面搞了那么多配置无非就是要识别啥才是一条真正完整的日志!!!针对这几个选项官方也总结了一个表格来描述各种组合的效果,比较清晰我就不赘述了。
而我们上面的配置的效果就是:使用正则表达式(type: pattern),如果与正则(^[)不匹配(negate: true)的行会追加到先前的一行后面(match: after)。如果与正则匹配的话,前面所有追加的内容将成为一个完整的日志事件,随后将会被发送到 output 对应的服务中,而当前匹配行将成为一个新日志事件的起始行。
那如果第一行匹配后一直没有新的匹配行进来,这一匹配行将永远无法成为一个已完成的日志事件,这个时候该怎么办?可以设置 multiline.timeout 配置项,默认值为 5 秒,即 5 秒后将无法成为日志事件的内容变为日志事件,并且发送到 output 中去。更多关于 Filebeat 多行匹配的配置可以参考官方文档。
最后我们启动 Filebeat:
# 修改权限chmod go-w filebeat.yml# 前台启动./filebeat -e# 后台启动,日志在 logs 目录下./filebeat -c filebeat.yml >> /dev/null 2>&1 &
如上示例,在运行前需要先修改 filebeat.yml 的权限,否则无法启动。
四、Logstash 简介与安装
1、Logstash 简介
Logstash 简单来说就是一个数据处理管道( pipeline) 。既然是数据处理管道,其必定有数据输入、数据处理、数据输出这个三个功能,这些在 Logstash 中对应的概念为 input、filter、output。而在整个管道中流转的数据称为 event,采集的数据在 input 阶段被转换为 event,而在 output 阶段会转换为对应的数据格式。
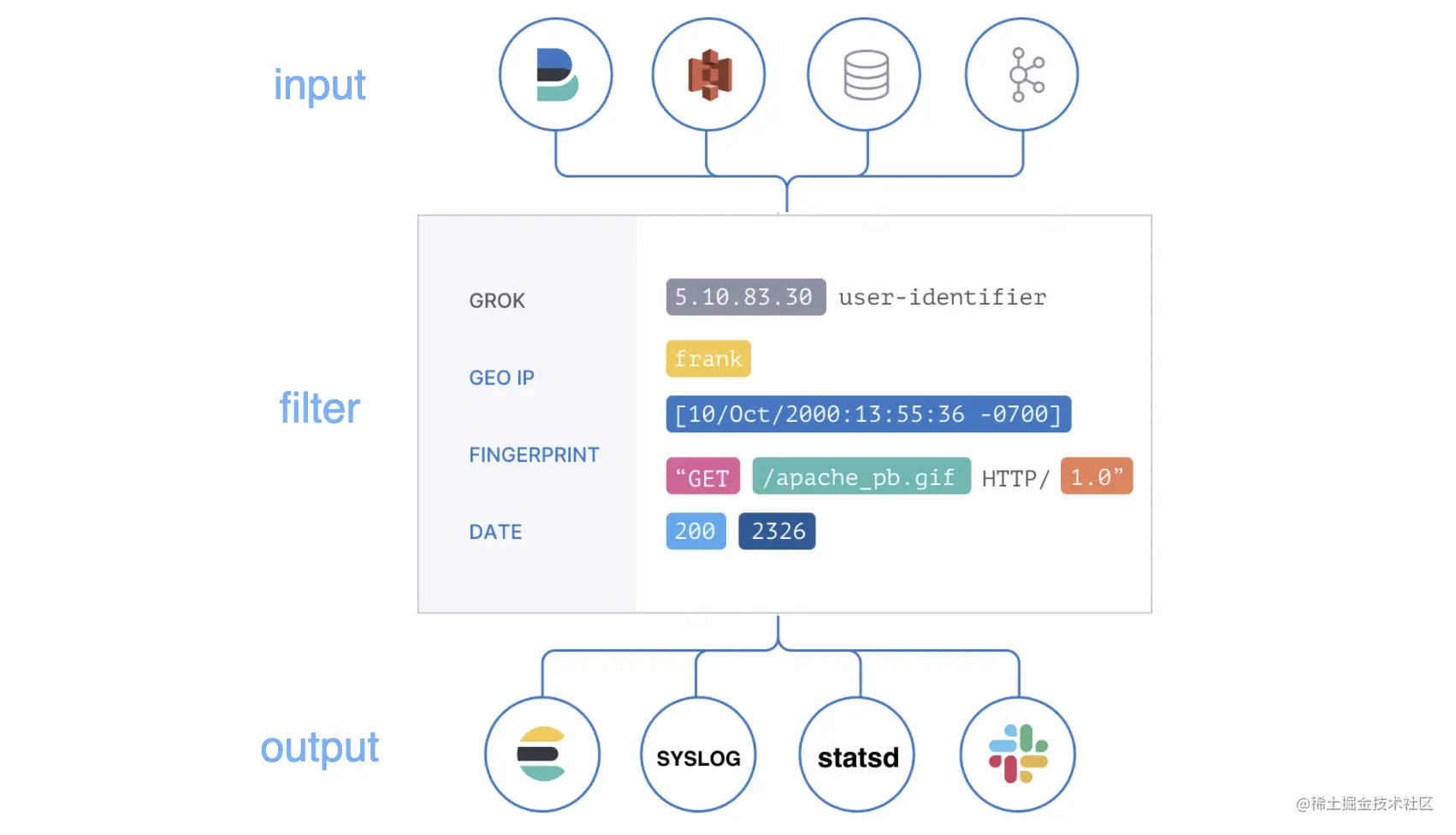
Logstash 的架构如上图,数据在 input 处被采集,然后通过 filter 被处理,最后从 output 流转到其他服务中去。
所以 Logstash 处理数据的整个流程为 input -- event —> filter event -- event —> output,其中 input、filter、output、event 概念的解析如下:
- input,通过 input 可以从各种各样的数据来源中采集数据。
- filter,数据解析、处理等操作,如可以为数据增加、删除某些字段,
- output,通过 output 你可以将处理后的数据保存到其他系统中,Logstash 提供了众多的 output 选择。
- event,在管道中流转的数据,可以通过 Codecs Plugins 来 encode 和 decode 数据,比较流行的格式有 json 和 msgpack、plain(text) 等。
Logstash 提供了非常多的 input、filter、output 的插件,本文是不可能全介绍的。但我们今天的目标非常明确,使用 Logstash 从 Kafka 采集日志数据、中间处理数据、最后输出到 ES 中保存日志数据,并且为每个服务每天创建一个索引来保存对应的日志数据。
2、Logstash 安装
在简单了解了 Logstash 中的几个概念和其工作方式后,下面我们来安装配置 Logstash。你可以在官方网站上选择下载你需要的版本,下面我们使用 wget 下载 tar 包进行安装:
# 下载 tar 包wget https://artifacts.elastic.co/downloads/logstash/logstash-7.13.0-linux-x86_64.tar.gz# 解压tar xvf logstash-7.13.0-linux-x86_64.tar.gz# 重命名mv logstash-7.13.0 logstash
进入 logstash 的 config 目录,创建 OrderServiceLog.conf 配置文件:
# 进入配置目录cd logstash/config# 创建 OrderServiceLog.conf 配置文件touch OrderServiceLog.conf# 将以下内容写入到到 test_log.conf 中input {kafka {bootstrap_servers => ["localhost:9092"]topics => ["order_service"]codec => "json"auto_offset_reset => "latest"decorate_events=> "basic"group_id => "logstash01"}}filter {grok {match => { "message" => "(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]" }}mutate {lowercase => [ "level" ]remove_field => ["beat"]}}output {elasticsearch {hosts => ["https://localhost:9211"]index => "%{[@metadata][kafka][topic]}_%{+YYYY-MM-dd}"user => "elastic"password => "123456"ssl => truessl_certificate_verification => falsecacert => "/home/ubuntu/ES/logstash/config/es_ca.pem"}}
如上示例,我们使用 kafka input 插件从 kafka 中获取数据,使用 elasticsearch output 插件将处理后的数据保存到 ES 中,使用了 mutate 和 grok 插件对数据进行处理。下面来详细介绍一下示例中用到的各个插件的配置项。
3、kafka input 插件
kafka {bootstrap_servers => ["localhost:9092"]topics => ["order_service"]codec => "json"auto_offset_reset => "latest"decorate_events=> "basic"group_id => "logstash01"}
Kafka input 支持的配置项非常多,你可以参考官方文档,下面只针对示例中用到的进行解析:
- bootstrap_servers,此参数非常明显,就是指定 Kafka 集群服务地址的,所以这个是个数组。
- topics,指定要消费的 topics,同样也是个数组,可以指定多个 topic。
- codec,输入数据的格式,默认是 “plain”。
- auto_offset_reset,指定如何消费 topic 的消息,”latest” 是消费最新的消息。”earliest” 是消费最早的消息,相当于日志重放了。当设置 “none” 时,如果没有找到之前消费的 offset,将会抛出异常。
- decorate_events,控制是否将 Kafka 元数据加入到 event 中。如果不设置则无法通过 [@metadata][kafka][topic] 等方式获取 Kafka 元数据。其默认值为 none,需要设置为 basic 或者 extended 才可以生效。
- group_id,定义一个消费者组的 id。对于消费组可以看作是一个单一逻辑的消息订阅者,举个例子就是: 同一个消费者组的消费者消费同一个 topic 数据时不会产生多次消费同一个消息的问题。所以当消费同一个 topic 的消息时,所有的 Logstash 实例应该设置同一个 group_id。
4、filter 插件
filter {grok {match => { "message" => "(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]" }}mutate {lowercase => [ "level" ]remove_field => ["beat"]}}
同样 filter 的插件也是非常多的,上面的示例中我们用了 grok 来提取日志产生的时间和日志的级别,使用 mutate 来将在 grok 中产生的日志级别转为小写,并且去除所有与 “beat” 相关的字段。
grok 插件
grok 其提供的功能简单来说就是可以将非结构化的数据解析为结构化数据,所以其非常适合解析 syslog、web 服务、mysql 等适合人类阅读但不适合计算机使用的日志, 下面举一个列子:
# 输入的非结构化日志数据[2022-04-07 12:07:50,335] [ERROR] [ActorSystemImpl] [default-dispatcher-4] - 登录异常,账号或者密码错误!# grokgrok {match => { "message" => "(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]" }}
grok 自定义正则语法:(?
需要注意的是在需要处理多行的日志的时候,需要加上 (?m),因为 grok 的正则表达式语法与普通的正则表达式语法一样,默认是不支持匹配回车换行的。你可能会问,%{SPACE} 是啥意思?其实 grok 默认提供的正则表达式有非常多,而 SPACE 是其中一个。但我不会在这里展开这部分内容,后续我们出几篇与各种插件相关的加餐内容,敬请期待!
更多关于 grok 插件的内容你可以参考官方文档,如果要 debug 你自定义的 grok 正则表达式,可以访问这个网站。
mutate 插件
mutate 插件允许我们对修改字段的数据,例如执行字段重命名、字段内容替换、字段值大小写转换等功能。
在上述的示例中,我们将 grok 插件匹配出来的 level 字段的值内容进行了小写转换,并且将 beat 相关的字段去除了。
mutate 提供的操作有挺多的,也很好理解,更多的使用示例请参考官方文档。
5、elasticsearch output 插件
同样 Logstash 提供的 output 插件非常多,我们今天的示例是把数据输出到 ES,使用的 elasticsearch output 插件配置如下:
output {elasticsearch {hosts => ["https://localhost:9211"]index => "%{[@metadata][kafka][topic]}_%{+YYYY-MM-dd}"user => "elastic"password => "123456"ssl => truessl_certificate_verification => falsecacert => "/home/ubuntu/ES/logstash/config/es_ca.pem"}}
elasticsearch output 插件提供的配置选项也是非常多的,下面对我们示例中用到的做解析:
- hosts,ES 集群的地址,如果指定一个数组的话会负载到各个节点去。
- index,指定保存数据的索引,其中我们使用了 %{[@metadata][kafka][topic]} 来获取数据是从哪个Kafka topic 来的,需要注意 Kafka input 插件需要 设置 decorate_events 为 basic 或者 extended 才可以生效。使用 %{+YYYY-MM-dd} 来获取当前日期。最终示例中索引的名字为 test_log_${date}。
- user 和 password, ES 的用户和密码,我们在《安全无小事:集群安全》配置了的。
- ssl,开启使用 SSL 连接到 ES 集群。
- ssl_certificate_verification,是否开启证书认证,这里设置 false。因为我们在 《安全无小事:集群安全》中配置的证书没有配置证书的 subject 等,所以设置为 true 时将无法启动,报错如下:

- cacert,指定链接到 ES 集群的 .cer 或者 .pem 证书。可以使用我们在 《安全无小事:集群安全》中通过 elastic-certificates.p12 生成的 es_ca.pem 证书。
6、运行 Logstash
ok,完成了 Logstash 配置后,执行下面指令来启动 Logsatsh:
nohup ./bin/logstash -f config/OrderServiceLog.conf >> ./run.log 2>&1 &
五、日志存储与检索的应用
如果顺利,到这里整个简易的 ELK 系统已经部署完成了,下面我们来推送几个业务日志,并且在 Kibana 中进行查询。在这之前请先关闭之前打开的 Kafka 消费者,免得影响测试结果。
执行下面的指令来推送日志:
# 把日志写入到 /home/ubuntu/OrderService.log,请修改文件路径echo "[2022-04-07 12:07:50,335] [ERROR] [ActorSystemImpl] [default-dispatcher-4] - 登录异常,账号或者密码错误![2022-04-07 12:07:50,335] [ERROR] [ActorSystemImpl] [default-dispatcher-4] - 登录异常,账号或者密码错误!" >> /home/ubuntu/OrderService.log
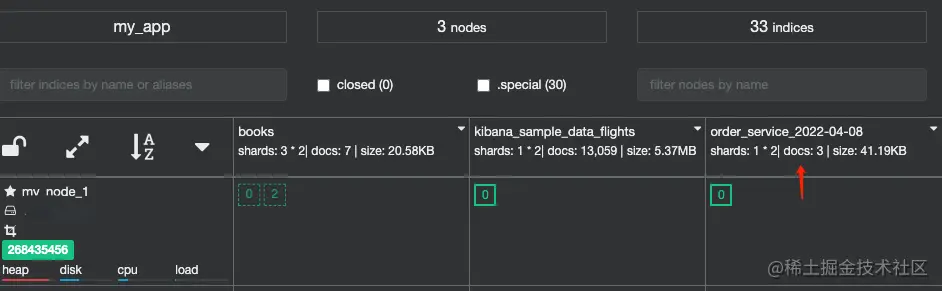
如上指令,你需要修改 OrderService.log 的文件路径,并且与 filebeat.inputs 指定监听的文件一致。日志推送后,可以在 cerebr 中可以看到新创建的索引 order_service_${date}:
此时我们可以在 Kibana 把这个索引加入到 Index patterns,然后再在 Discover 中进行日志查询。点击 Kibana 左边菜单栏最下面的 Stack Management,然后再点击最左边的 Kibana 下的 Index patterns,出现下面的界面:
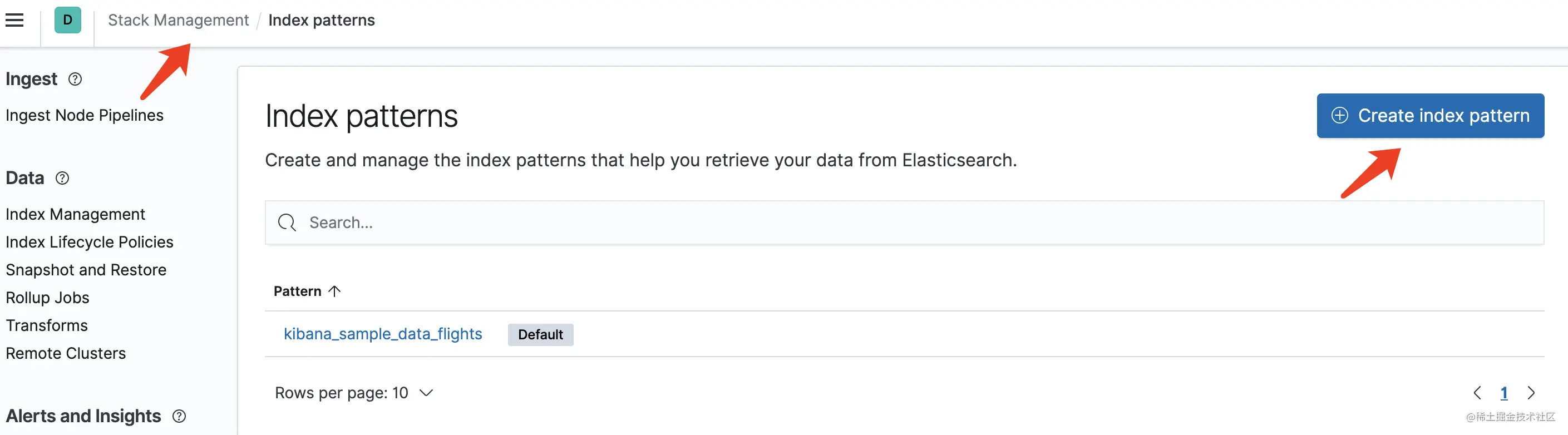
可以看到此时我的环境中已经配置了 Kibana 提供的航班数据了。点击 Create index pattern 按钮,选择我们生成的日志索引,进行创建 pattern:
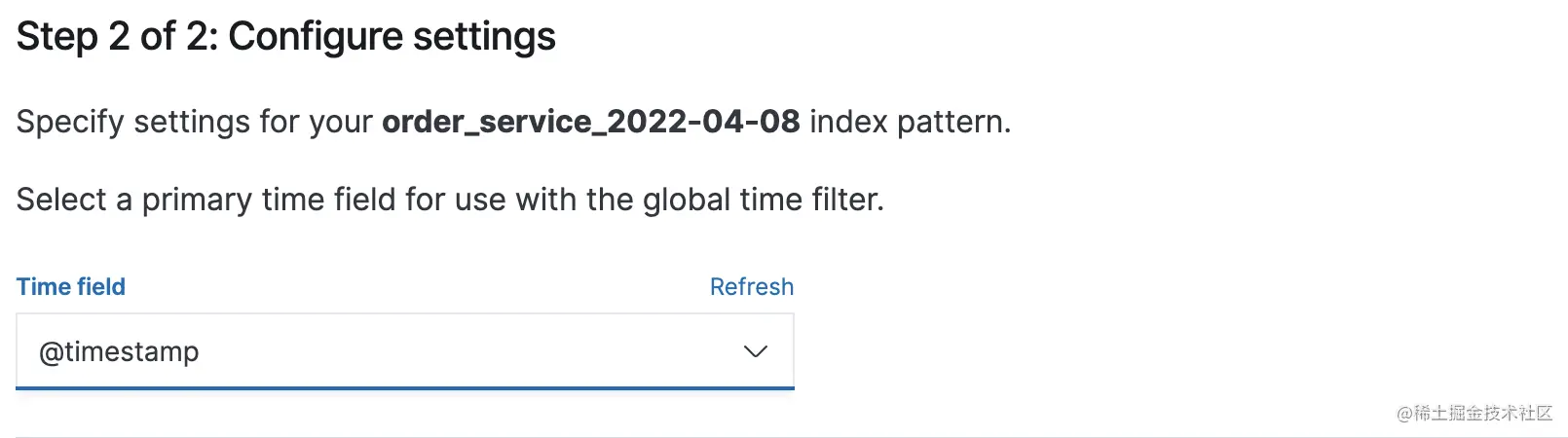
如上图,这里需要选择 @timestamp,这样可以方便在 Kibana 中做日期筛选。完成 pattern 创建后,点击 Kibana 左边菜单栏的 Analytics 下的 Discover:
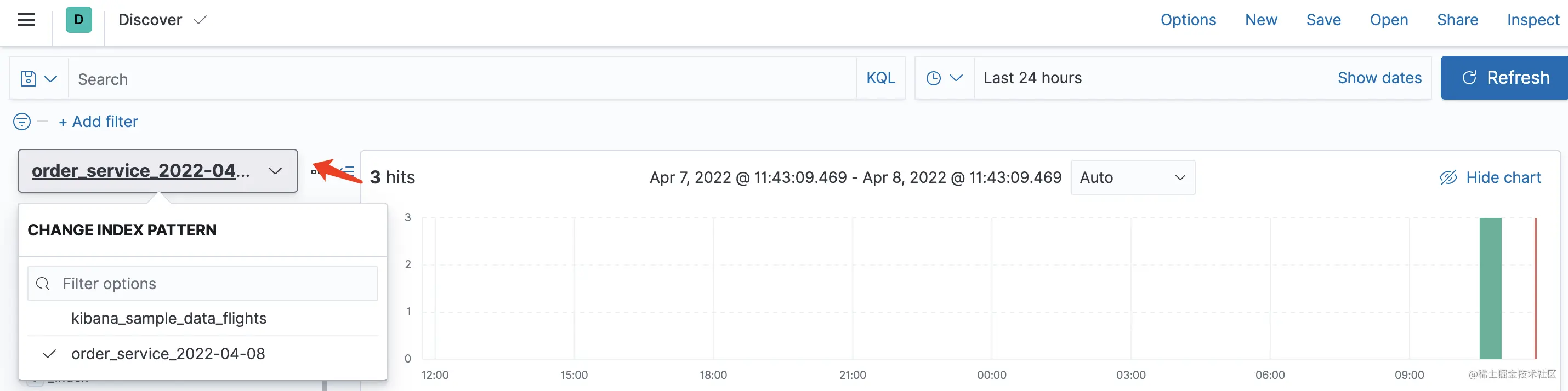
如上图,点击箭头处选择我们需要查看的日志数据索引即可。此时我们可以在 Kiaban 进行日志搜索:
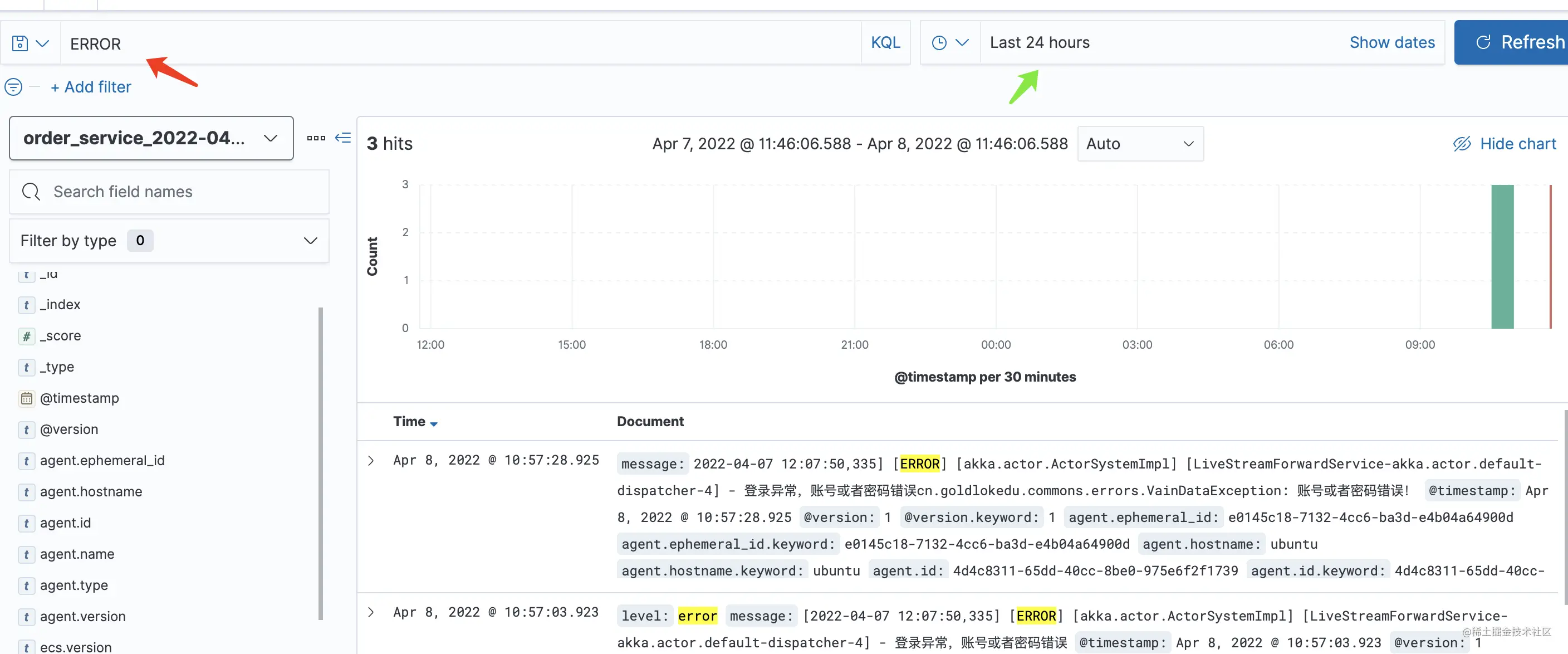
如上图,红色箭头处可以搜索关键字,而绿色箭头处可以搜索时间。
默认的情况下会显示整个文档的信息,但是文档中有很多的元数据字段并不是我们关心的。所以我们需要选择出我们关心的字段:
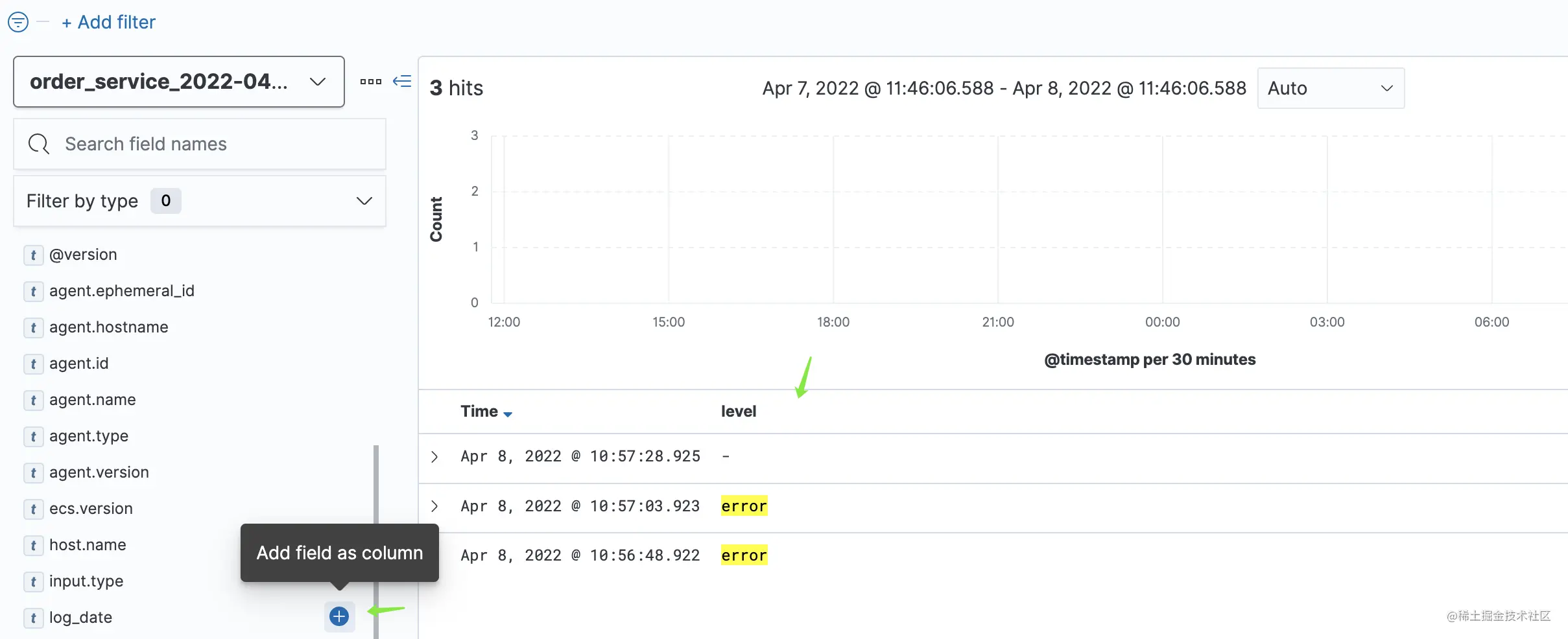
如上图,点击左边的字段,点击显示的加号即可。
至此,整个 ELK 的搭建和使用已经完成,Kibana 中提供的功能还有很多,剩下的你可以慢慢摸索,这里就不展开了。
六、总结
今天为你介绍了 ELK 常见的架构及它们的优缺点,然后我们搭建了一套适合企业级使用的 ELK 系统,并且针对使用到的各个组件进行了简介。
在我们搭建的 ELK 系统中,使用了轻量级日志采集器 Filebeat 来采集服务产生的日志,然后通过其output 输出到 Kafka 消息队列中。引入 Kafka 可以起到削峰、异步操作、日志重放的作用,可以避免数据丢失。
通过 Logstash kafka input 插件从 Kafka topic 中读取日志数据,然后在 filter 中对读到的数据进行处理,其中使用了 grok 来处理非结构化数据,从日志中提取出了日志等级和日志时间。使用 mutate 插件来修改数据字段和其内容,最终通过 elasticsearch output 插件输出内容到 ES 中进行保存。
最后我们也介绍了如何在 Kibana 中检索入库的日志。
