在之前的内容中我们已经多次接触过 Mapping 的概念和定义索引的 Mapping 了,今天我们来深入了解一下 Mapping。
那什么是 Mapping 呢?其实 Mapping 定义了索引中的文档有哪些字段及其类型、这些字段是如何存储和索引的。每个文档都是一个字段的集合,每个字段都有自己的数据类型,例如我们定义的 books 索引,其有 book_id、name 等字段。所以 Mapping 的作用主要有:
- 定义了索引中各个字段的名称和对应的类型。
- 定义各个字段、倒排索引的相关设置。如使用某字段使用什么分词器等。
PUT books{"mappings": {"properties": {"book_id": {"type": "keyword"},"name": {"type": "text","analyzer": "standard"}}}}
如上示例是我们定义一个索引的 Mapping 例子,可以看到 book_id 的类型为 keyword,而 name 的类型为 text,并且 name 字段指定了分词器为 standard。
在简单了解和复习了 Mapping 的概念后,我们今天的内容主要有以下几点:
- 什么是 Dynamic Mapping
- Mapping 支持的基本数据类型有哪些
- 如何快速自定义 Mapping
- Mapping 常用参数有哪些
下面就开始今天的内容吧~
一、Dynamic Mapping
除了预先定义好 Mapping 外,如果写入文档时索引不存在的话会自动创建索引,或者写入的字段不存在也会自动创建这个字段,官方把这种功能称为 Dynamic Mapping。
动态索引的好处是使得我们无需手动定义 Mapping,ES 帮我们根据文档的信息自动推算出了各个字段的信息。但是啊,推算的东西它不一定是准确的,很多时候并不是我们想要的东西!如果想要快速学习某些功能的时候 Dynamic Mapping 是挺方便的,但是我建议大家还是尽量自定义 Mapping。
在一个索引中定义太多的字段可能会造成 OOM 错误并且在错误恢复时会更加困难。如果使用了 Dynamic Mapping,在每个文档插入时增加了新的字段,可能会产生严重的问题。
下面是 Dynamic Mapping 的例子:
# 在不存在的索引中写入一个文档PUT test_mapping/_doc/1{"name": "es","count": 1}# 使用下面指令查看其 Mapping 的结果GET test_mapping/_mapping# Dynamic Mapping 产生的 Mapping 结果{"test_mapping" : {"mappings" : {"properties" : {"count" : { "type" : "long" },"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}
如上例子,只要你索引一个文档,那么这么这个索引及文档的字段、字段类型将会自动创建和定义。其中 count 的类型推断为 long,name 的类型推断为 text,并且加了一个子域,类型为 keyword。
当然我们也可以对 Mapping 的 Dynamic 属性进行设置,其示例如下:
PUT books/_mapping{"dynamic": "false"}
如上示例,我们设置了 books 的 dynamic 属性为 false。dynamic 属性的取值范围和作用如下:
- true:一旦有新的字段写入,Mapping 也同时被更新(自动创建了这个字段)。
- false:Mapping 不会被更新,新的字段不会被索引,但是新增的字段数据会出现在 _source 里。
- runtime:新的字段不会被索引,也是就是不能被检索,但是会以 runtime fields 的形式出现在 Mapping 中,并且新字段会存在于搜索结果的 _source 中。
- strict:如果写入不存在的字段,文档数据写入会失败。
二、Mapping 支持的数据类型
Dynamic Mapping 的功能可以自动推断字段的类型,这些类型都是 ES 支持的基本数据类型,这些类型主要有: 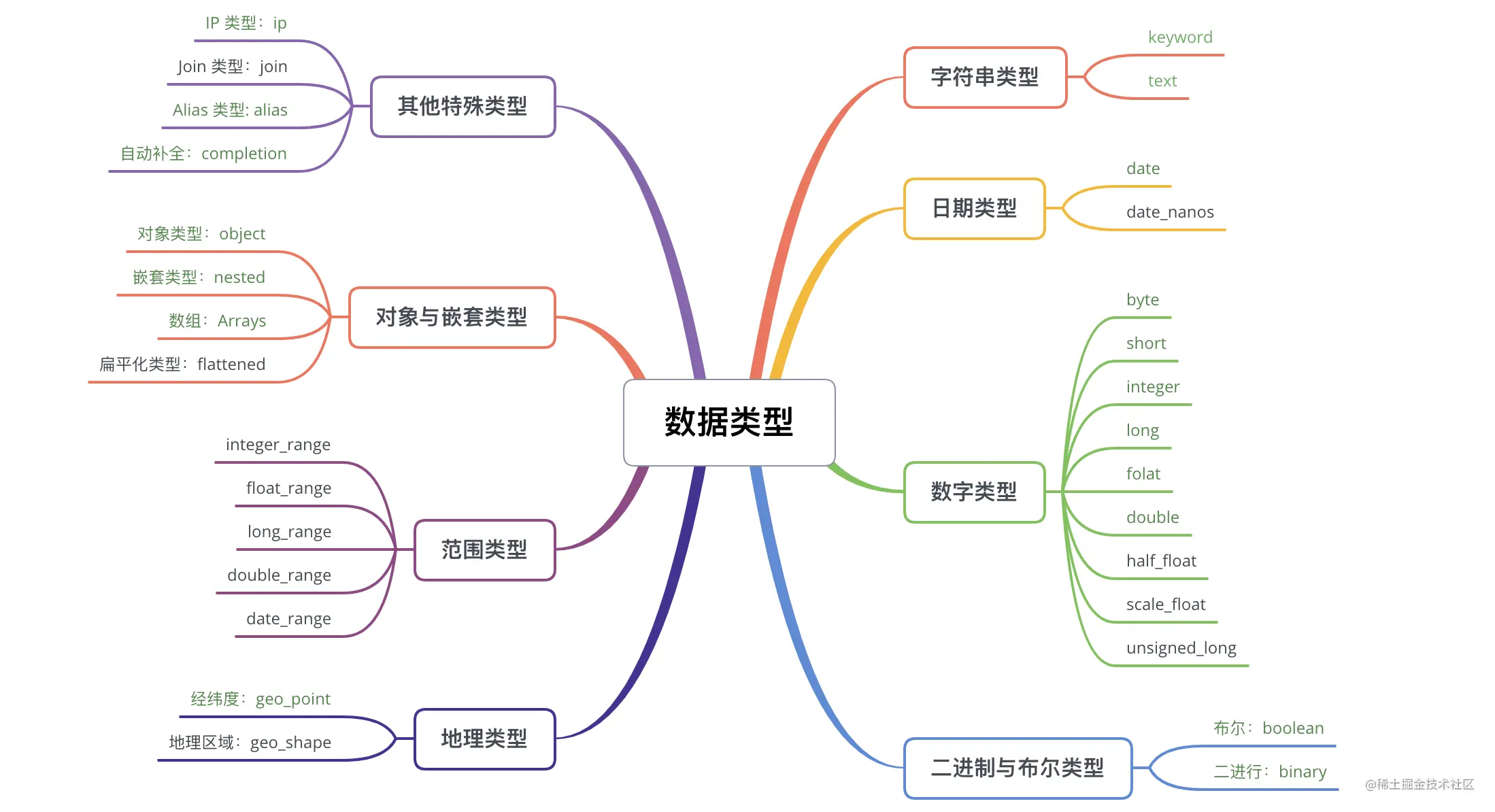
如上图,ES 提供的数据类型主要分为字符串、日期、数字、二进制、布尔、范围、地理、对象、嵌套类型等,比较常用的数据类型在图上已经用绿色进行标记了。
下面对常用的数据类型进行介绍,更多关于 Mapping 基本数据类型的内容可以参考官方文档。
1. 字符串
在 7.x 之后的版本中,字符串类型只有 keyword 和 text 两种,旧版本的 string 类型已不再支持。
keyword 类型适合存储简短、结构化的字符串,例如产品 ID、产品名字等。其适合用于聚合、过滤、精确查询。
text 类型的字段适合存储全文本数据,如短信内容、邮件内容等。text 的类型数据将会被分词器进行分词,最终成为一个个词项存储在倒排索引中。
2. 日期类型
我们知道 JSON 中是没有日期类型的,所以其形式可以如下表示:
- 字符串包含日期格式,例如:”2015-01-01” 或者 “2015/01/01 12:10:30”。
- 时间戳,以毫秒或者秒为单位。
实际上,在底层 ES 都会把日期类型转换为 UTC(如果有指定时区的话),并且作为毫秒形式的时间戳用一个 long 来存储。
3. 数字类型
数字类型分为 byte、short、integer、long、float、double、half_float、scaled_float、unsigned_long。
除了 half_float 和 scaled_float,其他我们都熟悉,就不再赘述了。half_float 是一种 16 位的半精度浮点数,限制为有限值。scaled_float 是缩放类型的的浮点数。
在满足需求的前提下,应当选择尽可能小的数据类型,除了可能会减少存储空间外,也会提高索引数据和检索数据的效率。
4. 对象与嵌套类型
我们的数据很多时候都需要用对象和数组、嵌套类型等复杂数据类型来表示的,例如书本作者可能有多个,这个时候作者字段就需要保存为一个数组。
下面来介绍一下对象和数组,至于嵌套类型(nested),我们将在后续的课程中再来介绍。
JSON 中是可以嵌套对象的,保存对象类型可以用 object 类型,但实际上在 ES 中会将原 JSON 文档扁平化存储的。假如作者字段是一个对象,那么可以表示为:
{"author": {"first":"zhang","last":"san"}}
但实际上,ES 在存储的时候会转化为以下格式存储:
{"author.first": "zhang","author.last": "san"}
对于数组来说,ES 并没有定义关键字来表示一个字段为数组类型。默认的情况下,任何一个字段都可以包含 0 个或者多个值,只要这些值是相同的数据类型。所以我们在创建数据的时候可以直接写入数组类型:
PUT books/_doc/3{"author": ["Neil Matthew","Richard Stones"],}
三、快速自定义 Mapping
前面提到,建议大家自定义 Mapping,而不要用 Dynamic Mapping 来生成。但是当 Mapping 拥有的字段非常多的时候,自定义 Mapping 是非常痛苦的并且容易出错。那有没有办法减轻一下我们的工作量呢?相信机智的你已经想到办法了。
我们可以把 JSON 对象直接写入,利用 Dynamic Mapping 的特性帮我们生成出一个初步可用的 Mapping,然后我们修改这个 Mapping 来直到满足需求即可。大概的步骤如下:
- 创建临时索引,并且写入业务数据。
- 获取这个临时索引的 Mapping。
- 根据业务场景,完善这个 Mapping。如对某些字段定义对应的分词器等。
- 完成后删除临时的索引,并创建符合需求的索引。
在使用 Dynamic Mapping 的时候,JSON 文档的字段类型会自动转换为ES的类型,下面是对照表:
| JSON类型 | ES类型 |
|---|---|
| Boolean | boolean |
| 整数 | Long |
| 浮点数 | Float |
| 字符串 | 1、匹配 Text,并且增加 Keyword 子字段。2、匹配为日期,设置为 Date。3、匹配为数字,设置为 Long 或者 Float,这个功能默认关闭。 |
| 对象 | object |
| 数组 | 由第一个非空数值的类型决定 |
| 空值 | 忽略,不做转换 |
四、Mapping 的常用参数
Mapping 参数可以用来控制某个字段的特性,例如这个字段是否被索引、用什么分词器、空值是否可以被搜索到等。Mapping 提供的参数有很多,更多的 Mapping 参数实例可以参考官方文档。下面的内容我们挑几个来介绍:index,analyzer、dynamic、null_value、copy_to。
1. index
当某个字段不需要被索引和查询的时候,可以使用 index 参数进行控制,其接受的值为 true 或者 false。使用示例如下:
PUT index_param_index{"mappings": {"properties": {"name": {"type": "text","index": false # name 字段不进行索引操作},"address": { "type": "text" }}}}
2. analyzer
这个参数其实我们用过多次了,它是用来指定使用哪个分词器的。
当我们进行全文本搜索的时候,会将检索的内容先进行分词,然后再进行匹配。默认情况下,检索内容使用的分词器会与字段指定的分词器一致,但如果设置了 search_analyzer,检索内容使用的分词器将会与 search_analyzer 设定的一致。其使用实例如下:
PUT analyzer_index{"mappings": {"properties": {"name": {"type": "text","analyzer": "simple","search_analyzer": "standard"}}}}
3. dynamic
可以在文档和对象级别对 Dynamic Mapping 进行控制,刚刚在 Dynamic Mapping 一节的内容中介绍过 dynamic 属性对文档级别的影响了,现在结合文档和对象级别来一个示例:
PUT dynamic_index{"mappings": {"dynamic": "strict", # 1,文档级别,表示文档不能动态添加 top 级别的字段"properties": {"author": { # 2,author 对象继承了文档级别的设置。"properties": {"address": {"dynamic": "true", # 3,表示 address 对象可以动态添加字段"properties":{}},"country": { "properties":{} }}}}}}
如上示例,在 1 处,我们控制了整个文档的 dynamic 为 strict,即如果写入不存在的字段,文档数据写入会失败。其中 author 对象没有设置 dynamic 属性,其将会继承 top 级别的 dynamic 设置。 我们在 “author. address” 对象级别中也设置了 dynamic 属性为 true,其效果是 address 对象可以动态添加字段。
4. null_value
如果需要对 null 值实现搜索的时候,需要设置字段的 null_value参数。null_value 参数默认值为 null,其允许用户使用指定值替换空值,以便它可以索引和搜索。
需要注意的是,null_value 只决定数据是如何索引的,不影响 _source 的内容, 并且 null_value 的值的类型需要与字段的类型一致,例如一个 long 类型的字段,其 null_value 的值不能为字符串。使用 “NULL” 显式值来代替 null,使用示例如下:
# 创建索引PUT null_value_index{"mappings": {"properties": {"id": { "type": "keyword" },"email": {"type": "keyword","null_value": "NULL" # 使用 "NULL" 显式值}}}}# 插入数据PUT null_value_index/_doc/1{"id": "1","email": null}# 查询空值数据GET null_value_index/_search{"query": {"term": { "email": "NULL" } # 使用显式值来查询空值的文档}}
5. copy_to
copy_to 参数允许用户复制多个字段的值到目标字段,这个字段可以像单个字段那样被查询。其使用示例如下:
# 创建索引PUT users{"mappings": {"properties": {"first_name": {"type": "text","copy_to": "full_name"},"last_name": {"type": "text","copy_to": "full_name"},"full_name": { "type": "text" }}}}# 插入数据PUT users/_doc/1{"first_name": "zhang","last_name": "san"}# 查询GET users/_search{"query": {"match": {"full_name": {"query": "zhang san","operator": "and"}}}}# 结果{"hits" : {"hits" : [{"_source" : {"first_name" : "zhang","last_name" : "san"}}]}}
如上示例可以看到,返回的结果中,_source 里是不包含 full_name 字段的。
6. doc_values
对数据进行检索的时候,倒排索引可以提高检索的效率,但是在对字段进行聚合、排序、使用脚本访问字段值等操作的时候,需要一种不同的数据结构来支持。
Doc values 是基于列式存储的结构,在索引数据的时候创建。它存储的值与 _source 中的值相同,使用列式存储结构使得 Doc values 在处理聚合、排序操作上更高效。Doc values 支持几乎所有的类型字段,但是 text 和 annotated_text 除外。
Doc values 默认是开启的,保存 Doc values 结构需要很大的空间开销,如果某个字段不需要排序、聚合、使用脚本访问,那么应该禁用此字段的 Doc values 来节省磁盘空间。其使用示例如下:
PUT my-index{"mappings": {"properties": {"status_code": {"type": "keyword"},"session_id": {"type": "keyword","doc_values": false}}}}
五、总结
今天为你介绍了 Mapping 的概念和 Mapping 常用参数、支持的字段类型。
Mapping 定义了索引中的文档有哪些字段及其类型、这些字段是如何存储和索引的,就好像数据库的表定义一样。
Dynamic Mapping 的特性可以帮助我们快速自定义一个 Mapping 来满足需求,但生产环境还是建议使用自定义的 Mapping,毕竟可控的东西才是可靠的。
Mapping 支持的数据类型有非常多,选择字段类型的时,在满足需求的情况下,应选择空间开销最小的那种。
除了设置字段的类型,定义 Mapping 的时候还可以使用 Mapping 提供的参数来控制某个字段的特性。控制好字段的特性,有时候可以帮助提高检索效率、节省磁盘空间等。
好了今天的内容到此为止,Mapping 的内容是非常多的,更多关于 Mapping 相关的使用信息可以参考官方文档。
