采用分布式架构使得 ES 可以实现水平扩展存储空间,轻松存储海量数据,也提高了系统的可用性、数据的可靠性。但是分布式系统的设计也带来了一些问题,今天我们就来聊聊 ES 集群中常见的问题和解决方案吧。
我们知道 ES 中只能有一个 Master 节点管理着整个集群,所以今天一部分内容会聊聊与 Master 相关的问题:Master 的单点故障和主从架构系统最怕的脑裂问题。
要说分布系统就不得不说分布式系统的理论基础:CAP 定理,所以今天也会简单看看 ES 在 C(Consistency)、A(Availability)、P(Partition tolerance)这 3 者中是如何选择的。
最后我们看看 ES 是如何进行集群扩容和分片故障转移的。
所以今天的内容主要有:
- Master 的单点故障与解决方案。
- 什么是脑裂,如何避免出现脑裂。
- 在 C(Consistency)、A(Availability)、P(Partition tolerance)中 ES 是如何选择的。
- 面对与日俱增的数据,ES 是如何做到轻松进行集群扩容的。
- ES 是如何进行分片故障转移来保障数据可靠性的。
一、Master 单点故障的风险
分布式系统组建集群的方式一般有两种:主从模式和无主模式。像 Hbase、ES 等使用的是主从模式,而 Cassandra 使用的是无主模式。
相对于无主模式,主从模式可以让系统设计变得更加简单。系统中的 Master 作为权威的节点,系统中关键的操作都只能由 Master 来执行,比如管理集群的元数据信息等操作。但是只有一个 Master 节点可能会存在单点故障的问题,而且随着集群规模的增长,Master 节点备受压力。
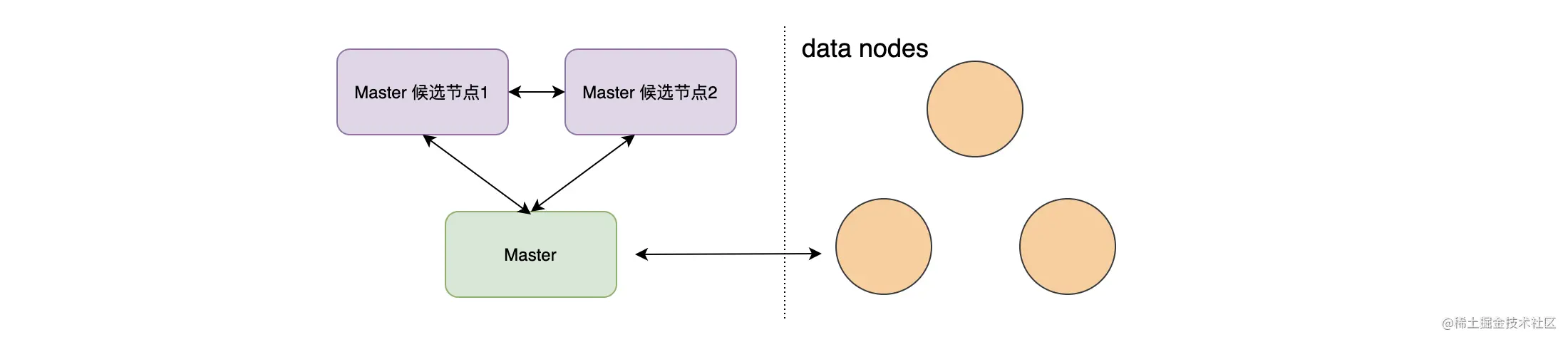
如上图,因为 Master 存在单点故障的问题,我们一般会将多个节点配置为 Master 候选节点,在 Master 节点宕机的时候这些节点可以升级为新的 Master 节点,从而解决 Master 存在单节故障点的问题。
由于存在多个候选者进行竞选 Master,如果由于某些原因系统产生了两个 Master,就产生了主从架构系统非常害怕的现象:脑裂。
二、脑裂
上面说过,集群中有且只能有一个 Master 存在,但是如果在网络出现问题情况下产生了两个 Master 会发生什么问题?可以预见的是,两个 Master 中元数据可能会变得不一样。当网络问题恢复后,谁将成为 Master,又该以谁的数据为准呢?
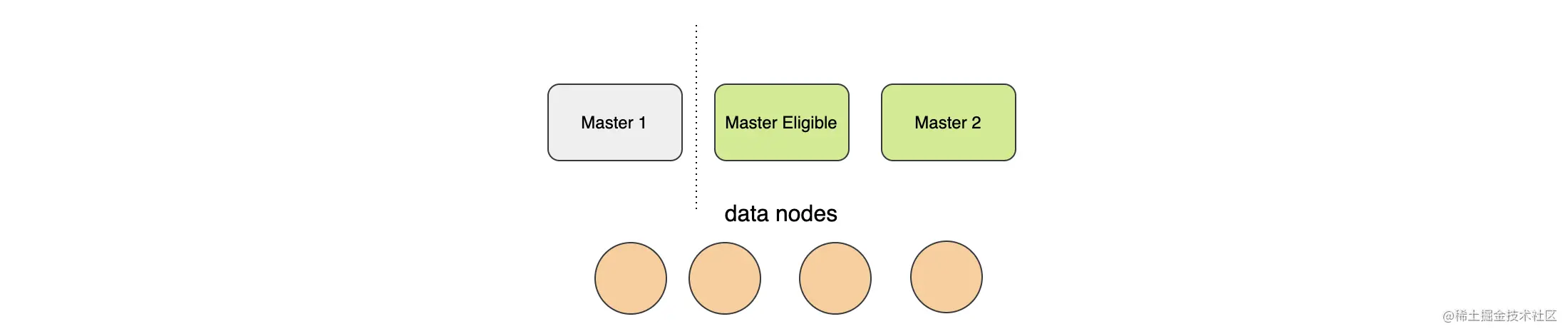
当采用主从模式的集群因为某些原因(网络分区、机器负载高导致假死等)导致出现了两个活动主节点的情况,我们称为集群脑裂。脑裂的危害非常大,会破坏集群数据的一致性。
那如何避免产生脑裂呢?ES 使用了 Quorum 机制来避免脑裂,在进行选主的时候,需要超过半数 Master 候选节点参与选主才行。假如有 5 个 Master 候选节点,如果要成功选举出 Master,必须有 (5 / 2) + 1 = 3 个 Master 候选节点参与选主才行。
在早期的版本中,我们需要设定一个仲裁(Quorum)的条件,只有 Master Eligible 节点(Master 候选节点)数大于 Quorum 的时候才能进行选主。其中Quorum的算法如下:
Quorum = (Master 候选节点数 / 2) + 1
早期的 ES 需要手动配置这个仲裁条件,在 elasticsearch.ymal 文件中配置:
discovery.zen.minimun_master_nodes = 3 //上面算出来的Quorum
其实这样做呢,是会出现问题的,说不定哪个新来的小朋友不了解脑裂和这个配置的或者不小心配置错了,导致集群无法选举或者产生脑裂就惨了。所以在 ES 7.0 后就移除了这个参数了,毕竟 Master 候选节点间是需要通信的,还是系统自己算比较靠谱!
三、可用性和一致性间的抉择
在设计分布式存储系统的时候,CAP 理论是无论如何都绕不过去的。
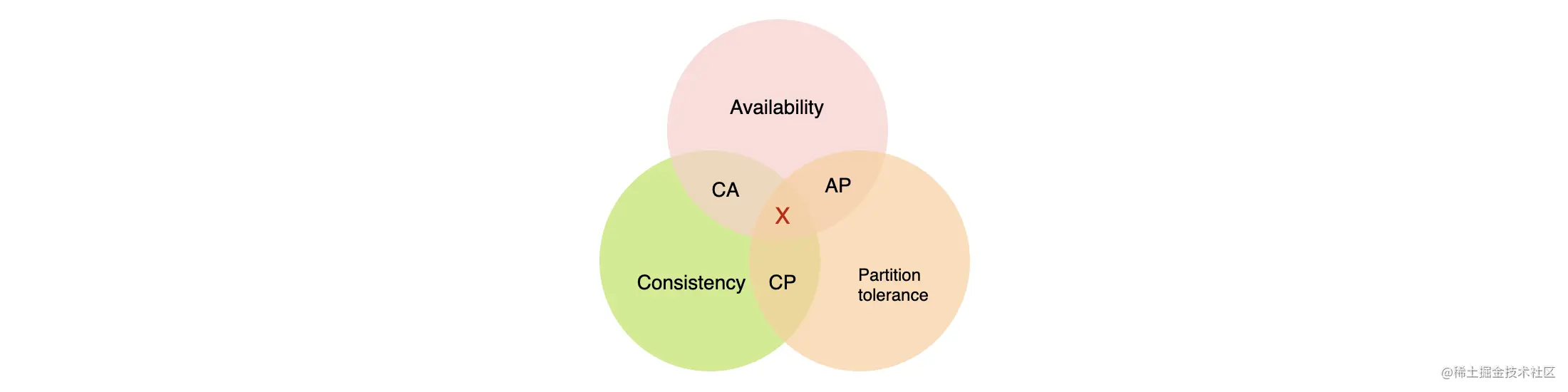
CAP 理论定义了:分布式数据存储系统最多只能满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项 。下面简单介绍一下这 3 个特性。
- 一致性(Consistency) 一致性是指数据的一致性,即客户端操作成功后,所有节点上的数据都是相同的。一致性的策略主要有:
- 强一致性:更新后的数据可以立刻在后续的访问中读到。
- 弱一致性:数据更新后,后续对该数据的读取可能得到旧值也可能得到更新后的值。
- 最终一致性:一段时间后各个节点的数据会达到一致状态,最终所有请求都会读到更新后的值。
在 CAP 中一致性指的是强一致性。
- 可用性(Availability)
可用性是指服务一直可用,系统读写都能在正常的响应时间内返回。
- 分区容错(Partition tolerance)
分区容错是指在系统遇到网络故障或者部分节点故障的时候,系统依然可以对外服务。
ES 是一个分布式数据存储系统,当然也要遵循 CAP 理论的。但在现实中网络环境总是不可靠的,所以网络分区总是会出现,那么 P 是我们必须要保证的。在剩下的可用性和一致性中,ES 更倾向于选择可用性。
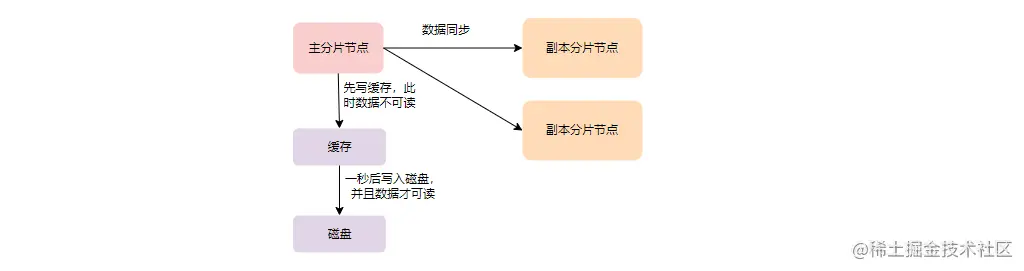
如上图,数据写入的时候会先在主分片上写缓存、日志,然后再将数据同步到副本分片中。在主分片上写入成功的数据并不能马上被查询到,而是默认每一秒将缓存的数据写到磁盘上,这部分数据才能被检索。所以从这个角度来看,ES 并没有保证强一致性,而更像是最终一致性。默认的情况下,只需要主分片写成功即可,系统并不要求必须有多少个副本分片写入成功才可以。
其实 ES 本身系统的定位就是一个准实时的系统,并没有必要保证强一致性,反而更需要考虑的是可用性。更多关于数据存储的过程、副本同步策略将会在后续的内容中详细描述。
四、集群扩容
当系统的数据量与日俱增时,对集群进行扩容是非常必要的。当为系统增加数据节点的时候,索引的分片会均匀地分配到各个数据节点中去,从而达到负载均衡的目的。这些工作都是系统自己完成的,用户只需要加一台机器即可!
下面是集群由一个节点变成 3 个节点时,主副分片的迁移过程,其中 P 代表主分片,而 R 代表副本分片。
如下图,一开始在 Node1 上有 3 个主分片,但没有副分片:

如下图,当添加第二个节点后,副本分片就被分配到 Node2 了,其中 R0 代表的是 P0 的副本:

如下图,当添加了第三个节点后,索引的所有主副分片都被平均分配到集群的 3 个节点上:

如上图,其中灰色的 P0、R2 分片被迁移走了。可以看到如果其中一个节点挂了,其所有的数据都在其他两个节点上存在,所以不会丢失数据。在数据迁移的过程中需要保证主分片要均匀分配外,还要保证副本分片不能和它的主分片分配到同一个节点上,否则仍然存在数据丢失的风险。而当一个主分片异常时,其副本分片可能会被提升为主分片。
五、分片故障迁移
ES 通过副本机制来保障数据的可靠性,当一个数据节点下线后,系统会对这个节点上的主分片进行故障迁移,从而防止数据丢失。
集群扩容的本质就是添加数据节点,而分片故障转移是指在数据节点下线后 ES 自动将下线的主分片重新分配到其他节点,并且产生相应副本分片的过程。主分片的重新分配其实是将某个最具条件的副本分片升级为主分片。下面是分片故障转移过程的一个简单实例。
主节点下线:

如上图, 假设集群有 3 个节点,其中索引有 3 个主分片和每个主分片对应一个副本分片,现在 Node1(Master)下线了,集群进行重新选主,Node2 成为了新的 Master。这个时候集群状态为 Red,因为部分主分片没有分配成功。
主分片迁移(副本分片升级为主分片) :

如上图,在 Node2 成为主节点后,下线的 P1 和 P2 开始做迁移,说是迁移其实是将其他节点上最符合条件的副本分片升级为主分片,所以在 Node2 的 R1 成为了 P1,在 Node3 中的 R2 成为了 P2。这个时候集群状态变为 Yellow,因为部分主分片的副本没有分配成功。
创建新的副本分片: 
如上图,在 R1 和 R2 升级为主分片 P1 和 P2 后,系统会再分配出新的 R1 和 R2,这个时候集群状态变为 Green。
六、总结
今天为你介绍了 ES 集群中常见的问题和解决方案。
在设计系统的时候,ES 选择了主从架构,为了避免出现 Master 单节点故障的问题,我们应该在生产环境中配置多个 Master 候选节点。而为了防止脑裂的产生,ES 使用了 Quorum 机制来避免脑裂,在进行选主的时候,需要超过半数 Master 候选节点参与选主才行。
CAP 是分布式数据存储系统的一个基础理论,作为一个准实时系统,ES 并没有选择 CAP 中的强一致性特性,而是选择了可用性。
在为系统增加存储空间时,我们只需要为集群添加一个数据节点即可,剩下的工作 ES会为我们自动完成。在数据迁移的过程中系统会保证主分片均匀分配,并且还会保证副本分片不会和它的主分片分配到同一个节点上。
为了保证数据的可靠性,在发生分片故障的时候,ES 是会自动完成数据迁移的。系统会先在其他节点上恢复主分片,然后再从其他节点上恢复足够多的副本分片。
