之前在群里聊天的时候,发现有挺多同学需要做数据导入的操作,所以今天我们就来聊一下写入数据的调优思路,并且对导入数据的操作进行优化。
写调优有很多方向,今天我们的内容会涉及 Mapping 设计、操作系统层面的设置、ES 相关参数的调优。最后我们将在导入数据的场景下对 ES 相关参数进行测试,看看他们对数据写入的影响能有多大,当然我们不是要对 ES 进行压测,而是简单地、尽可能地采取控制变量的方式来测试某个参数对写入速度的影响。
一、Mapping 设计建议
Mapping 设计得好不好对整个写入时间的影响是巨大的,在满足业务需求的情况下,Mapping 约精简越好。下面给出一些 Mapping 设计的建议,这些建议都遵循一个思想:够用就好,让系统少干活。
1、字段尽量少,够用即可
字段越多,写入的时候占用的资源就越多,相同的 index buffer 能存储的数据条数越少。更多的字段对搜索也是有影响的,ES 非常依赖于底层的文件系统缓存,我们肯定想把更多的数据(index segment)缓存起来,这样可以提升性能。
其实搜索分为两个阶段,一个是 search,一个是 fetch。search 阶段根据查询条件从系统找到对应数据的 ID,而 fetch 则根据这些 ID 从系统中获取对应的数据内容。所以可以把需要搜索的内容放到 ES 里,而文档的源数据放到 mysql 或者 hbase 里,搜索的时候从 ES 里搜索出文档 ID,再从 mysql 或者 habse 中获取文档数据。
2、不需要的搜索的字段不要索引
对于那些存储在 ES 中,但有不需要进行搜索的字段,可以设置其不需要索引:
PUT myindex{"mappings": {"properties": {"content": { "type": "text" },"name": {"type": "text","index": false}}}}
如上示例,name 字段不需要索引,所以将其设置 index 属性为 false 即可。
3、数据扁平化,尽量避免使用 nested、parent-child 类型
尽量减少 object 类型的使用,更建议将数据扁平化。越是复杂的数据结构,系统要处理的事情就越多,写入就越慢。而且 nested、parent-child 等数据类型,在查询时候性能也很差。
4、禁用 Dynamic Mapping
必须明确每个字段的类型和属性,建议禁用 Dynamic Mapping。例如上述的 name 字段,我们想让其不进行索引,但如果是 Dynamic Mapping 处理后,默认是会进行索引的,这并不符合我们的需求。
5、使用合适的数据类型
根据业务需要来选择最合适的数据类型,例如 ID、枚举等用 keyword,文章标题用 text 等。
6、配置合适的分词器
不同的分词器性能大不相同,需要根据业务符合度来进行选择。例如 IK 分词器有 ik_max_word 和 ik_smart 两种模式,分词的粒度不一样,性能也有差别。
7、关闭 Norms
如果一个字段不需要算分,可以关闭其 Norms,下面是官方的示例:
PUT my-index-000001/_mapping{"properties": {"title": {"type": "text","norms": false}}}
在底层 Norms 存储了各种归一化因子,这些因子在查询数据的时候用于算分。尽管保存这些归一化因子对算分很有用,但是需要耗费一定的磁盘空间。通常来说,开启了 Norms 的字段,每个文档都需要一个字节来保存这些信息,即使这个文档内容里没有这个字段。
8、关闭 doc_values
doc_values 是用来给文档建立正排索引的,与 fielddata 不同的是,doc_values 在索引时创建,并且需要占用磁盘,开启 doc_values 有利于对这个的值进行排序和聚合。 对于非 text 字段的类型,doc_values 默认是打开的,下面是关闭 doc_values 的示例:
PUT my-index-000001{"mappings": {"properties": {"session_id": {"type": "keyword","doc_values": false}}}}
所以,当我们确定一个字段不需要进行排序和聚合时,可以考虑关闭其 doc_values 属性。但是遗憾的是,如果你想重新打开某个字段的 doc_values 属性,需要重建索引。
在 Mapping 上优化的点其实还有很多,如果你不清楚一个字段的类型和属性该如何设置,建议从官方文档中获取相关的信息。
二、操作系统层面的调优
ES 作为一个应用程序运行在操作系统上,那么调整操作系统相关的参数来适配 ES 的运行是至关重要。这里有部分内容在《睡个安稳觉的关键:集群运维》中已经详细介绍过了,这部分的内容我会一笔带过。
1、关闭操作系统交换分区
为了防止物理空间的数据被交换到 swap 空间(磁盘)上,需要关闭 swapping:
sudo swapoff -a
2、增加系统最大的线程数
为了保证 ES 可以创建新的线程,需要在 /etc/security/limits.conf 中设置 nproc 的值为 4096:
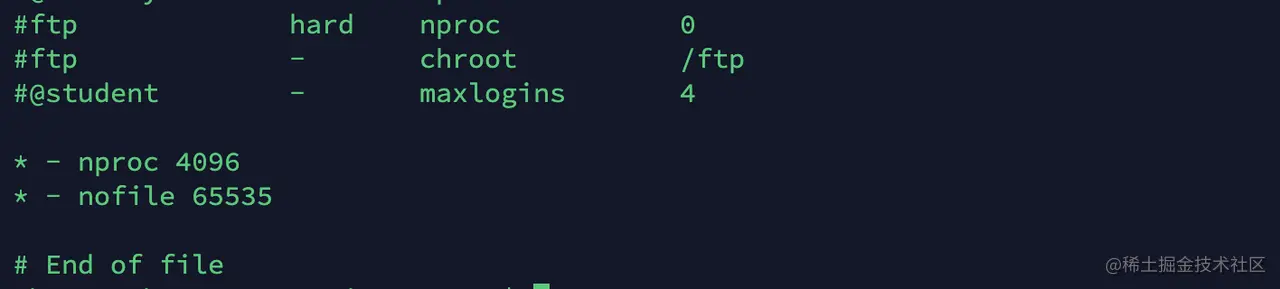
保存后,用户再次登录上系统,即可生效。
3、增加文件句柄数量
ES 运行的时候需要使用非常多的文件,所以要调大文件描述符数量的值。同样需要在 /etc/security/limits.conf 中设置 nofile 的值为 65535,配置如上图。
4、设置 mmap counts
ES 使用了 mmapfs 来存储索引,但是默认的 mmap counts 的数量实在太少了,这样可能会造成 OOM 异常。可以在 /etc/sysctl.conf 中设置 vm.max_map_count 的值为 262144,设置完成后需要执行 sysctl -p 刷新。
5、磁盘调优
相当于机械硬盘来说,使用 SSD 等更好的硬件设备可以有效 I/O 性能。在使用 SSD 的时候,你需要确保系统的 I/O 调度程序是正确的。然后在磁盘挂载的时候需要关闭写入上次访问时间的记录等操作,这些操作会影响磁盘的寿命。更多关于 SSD 的调优,请参考更专业文档。
6、JDK 和 JVM
Xms 和 Xmx 的配置这里就不再赘述了。建议使用 ES 对应版本官方推荐的 JDK,并且根据实际的场景和需要使用对应的垃圾收集器。
三、ES 层面的调优
ES 默认的参数和设置是综合了索引数据的速度、搜索实时性、数据可靠性等因数的。所以当我们在某些场景下可以调整具体的参数来满足相应的业务需求。例如我们在做数据导入的时候,此时没有搜索的需求,实时性也不高,那么可以优化写入的性能,减少等待的时间。
通过对《数据持久化:分布式文档的存储流程》的学习,我们对数据写入的流程应该非常熟悉了,如果你印象还不够深,请重新翻阅!针对整个写入流程,要提升写入的性能,可以从以下几个点入手:
- 合并单个请求到批量请求,也就是尽量使用 Bulk 方式写入数据。
- 减少 index refresh 的次数,同时会减少生成 segment 的数量,也减少了 merge 的频率。
- 加大 translog flush 的间隔,这样可以降低 iops。
- 将请求均匀分发到各个节点进行处理,尽量利用集群资源。
- 减少副本的数量,写入时因为要将数据同步到副本,所以这也是要消耗时间的。
1、Bulk 请求
通过对源码的阅读,我们知道不管是单个请求还是批请求,最终都转化为 Bulk 的方式来进行处理的。使用 Bulk 的方式有利于提高写入的性能,这个其实也很好理解,如果链接不是长链接,每写入一条数据都进行一次 TCP 链接的过程,那效率是多低啊。另外一般来说,建议一个批里只处理同一个索引的数据,不同索引的数据分多个批进行提交。
虽然说要将数据进行批提交,但是并不是批越大就越好的,建议是 5M 到 10M 一个批。假设平均一条数据为 1k,那么一个批就是 5000 到 10000 条数据。当然这个并不是绝对的,你需要根据你的集群情况来做调整。你可以先每个批 5000 条开始进行测试,然后 8000、12000,直到写入的性能不在提高为止。
2、减少 index refresh 的次数
减少 index refresh 的次数可以减少生成 segment 的数量,也减少了 merge 的频率。调整 index refresh 的次数可以调整以下两个参数:
indices.memory.index_buffer_size # 静态配置,需要在 elasticsearch.yml 中配置index.refresh_interval: 120s # 动态的配置,直接使用 API 进行设置即可
1. indices.memory.index_buffer_size
indices.memory.index_buffer_size 是一个静态的配置,需要在 elasticsearch.yml 中配置,并且需要重启 ES 服务才能生效。 index_buffer_size 你可以配置一个字节数,如 5242880(5M),也可以配置一个比例,如 20%,即占用堆内存的 20%(默认是 10%),如果你配置了堆内内存为 1G 的话,此时 index_buffer_size 为 200M。需要注意的是,index_buffer_size 的空间是节点内所有分片共享的。
当然除了指定 indices.memory.index_buffer_size,还可以指定 indices.memory.min_index_buffer_size、indices.memory.max_index_buffer_size 来指定 index_buffer_size 最小占用的空间和最多占用的空间。这两个参数都是在 index_buffer_size 用百分比设置的时候才会生效的。
indices.memory.index_buffer_size 的配置如下:

2. index.refresh_interval
默认的情况下,ES refresh 操作会每秒进行一次,可以通过调整 index.refresh_interval 的值来调整 refresh 的时间间隔。需要注意的是,refresh 会把 index_buffer 的内容写到磁盘中(实质是在磁盘缓存中),生成 Segment 文件,此时的文档才可以被检索。
如果需要禁止 refresh 操作,可以把 index.refresh_interval 设置为 -1。不再进行 refresh 操作,那如果 index_buffer 满了会怎么办,炸吗?炸是不会炸,还是会进行 refresh,然后清理 index_buffer。
3、加大 translog flush 的间隔
为了防止数据丢失,保证数据的可靠性,默认情况下是每个请求 translog 都刷盘。如果我们是在导数数据的应用场景,那么为了提高写入的性能,可以不每个请求都对 translog 进行刷盘。对 translog 刷盘的控制参数有以下几个:
- index.translog.durability,可选项有 request(默认)和 async。request 是指每个请求都会对 translog 进行刷盘,而 async 是异步刷盘,每隔 index.translog.sync_interval 进行刷盘。
- index.translog.sync_interval,translog 刷盘的时间间隔,默认 5s,不能小于 100 ms。
- index.translog.flush_threshold_size,当 translog 的量达到这个阈值将会触发刷盘,默认是 512 M。调大这个阈值可以减少刷盘的次数和大段的合并次数。
这几个参数的配置样例如下:
index.translog.durability: async # 默认值为 requestindex.translog.sync_interval: 60s(自己设置)index.translog.flush_threshold_size: 1gb(自己设置)
4、将请求均匀分发到各个节点进行处理
使用 ES 生成的随机 ID 可以将数据均匀分发到各个节点进行处理,可以有效地利用集群的计算资源。并且使用 ES 生成的随机 ID 写入时不需要先检查一遍 ID 是否已经存在,可以有效提高写入的效率。
5、减少副本的数量
在写入主分片成功后,数据同步到副本是并行进行的,按道理只需要等待最慢的那个返回即可以完成写入。但其实我们在导入数据的时候,可以设置从副本的数量为 0,等数据导入完成后,再设置从副本的数量,然后等系统自己同步到各个节点上,其示例如下:
PUT /myindex/_settings{"number_of_replicas": 2}
四、ES 层面调优的实践
上面提到了几个优化的配置,下面我们来测试一下他们对导入数据性能的影响。
下面先交代一下我的测试环境,机器信息如下图:

我用的是一台 4 核 8 线程,内存 8G 的虚拟机,磁盘为机械硬盘,系统为 Ubuntu 16.04,ES 是 3 节点的伪集群,-Xms 和 -Xmx 都是 512m。
我使用的测试数据集为微信公众号语料库,我从这个语料库中抽取了前 25 万条,大约 1G 的数据(每条数据大约 4.2k),使用 elasticdump 把数据从机器 A 导入到部署 ES 机器的机器 B 中。
我们的测试并不是对服务进行压测,而只是为了测试各个配置项对导数数据时性能的影响,所以我们采用控制变量法来对对比各个配置的效果。最后,由于物理机还有部署了很多其他的虚拟机,它们上面也跑了很多其他业务,可能导致测试结果有抖动的情况发生。然后为了保证公平性,每次测试都会重启系统,待系统稳定后再进行测试。
1、调整 Bulk 大小
此处我们用基础的伪集群配置来测试,没有任何调优。测试的 Mapping 模板如下,其中主分片 3 个,从副本 0 个:
PUT articles{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_smart"},"account": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_smart"},"title": {"type": "text","analyzer": "ik_smart"}}},"settings": {"number_of_shards": 3,"number_of_replicas": 0}}
- 3200 条数据一个批:


如上图,这种情况共耗时 4 分 39 秒。
- 7200 条数据一个批:


如上图,当每个批 7200 条数据(30M 左右)时,共耗时 4 分 07 秒。
- 10200 条数据一个批:


如上图,当每个批 10200 条数据时,共耗时 4分 15 秒。
- 13200 条数据一个批:
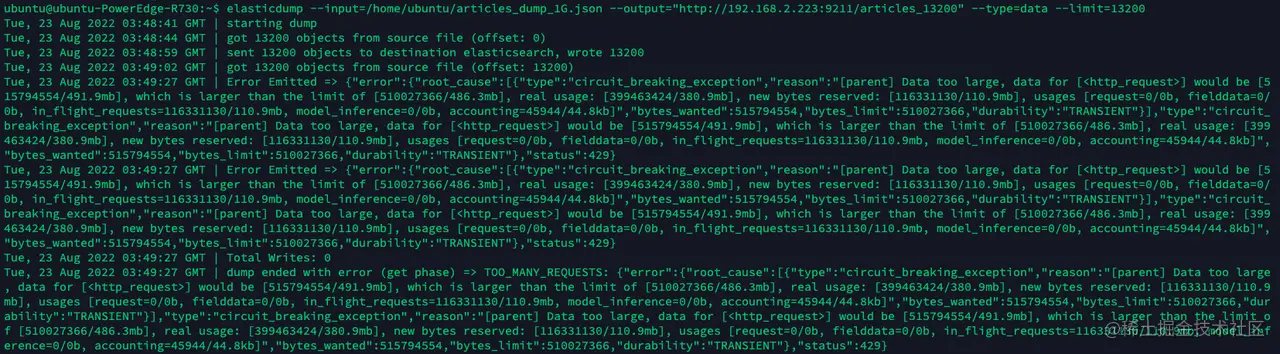
如上图,当我把条数调整到 13200 时,部分请求直接被拒绝了。
可以看到,调整 Bulk 的大小确实可以提高导入的性能。总数据量相同的情况下,更少的批次可以减少提交的次数,毕竟 TCP 链接是很耗时的。如果每个批次 10 条数据,并且不是长链接的情况下,需要交互 2.5 万次,想想都觉得低效。
最后,我这个测试环境的极限估计在 7200 到 10200 间。
2、调整副本分片
此处我们同样用基础的伪集群配置来测试,没有任何调优,每个批用 7200 条数据来测试。测试的 Mapping 的模板如下,其中主分片 3 个,从副本将根据测试来进行调整:
PUT articles{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_smart"},"account": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_smart"},"title": {"type": "text","analyzer": "ik_smart"}}},"settings": {"number_of_shards": 3,"number_of_replicas": 0}}
- 0 副本:


如上图,0 副本的情况下,耗时 4 分 35 秒。
- 1 副本:


如上图,1 副本的情况下,耗时 7 分 09 秒,比 0 副本的情况足足多了 2 分 34 秒。
- 2 副本:


如上图,2 副本的情况下,耗时 9 分 06 秒,比 1 副本的情况多了 1 分 57 秒。
可以看到,副本越多的情况下,耗时会越多。出乎我意料之外的是,2 副本的耗时比 1 副本的耗时要多很多。因为数据同步到各个副本节点是并行发送的,所以不应该多那么多的。出现这种情况的原因是,我们的集群部署在同一台机器上,在数据写到主分片的时候,其实 CPU 基本跑满了,所以同时在两个副本上写入数据会存在资源竞争的情况。
最后完成数据导入后,可以使用以下示例设置副本的数量,ES 会自动创建这些副本,并且同步数据:
PUT /myindex/_settings{"number_of_replicas": 2}
3、调整 Buffer Size
这里我们同样使用上面的 Mapping 模板,需要设置从副本数量为 0,每个批 7200 条数据。然后需要在 elasticsearch.yml 更改对应的配置项:

如图,因为节点的堆内内存为 512m,所以 1% 的堆内内存大约为 5m,我们用 min 和 max buffer size来对其控制,不同的情况需要对它们进行更改,并且需要重启集群。
- 1% 堆内内存(5m):


如上图,buffer size 在 5m 的时候,耗时 4 分 49 秒。
- 3% 堆内内存(15 m):


如上图,当 buffer size 调大到 15m 的时候,耗时 4 分 33 秒,比 5m 的情况块了 16 秒。
- 3% 堆内内存(15 m),不进行 refresh:
要关闭 refresh,需要在创建 Mapping 时进行设置:
PUT articles_buffer_15m_no_refresh{"mappings": { ...... },"settings": {"number_of_shards": 3,"number_of_replicas": 0,"index.refresh_interval": "-1" # 不进行 refresh}}


如上图,当 buffer size 调大到 15m,并且不进行 refresh 时,耗时 4 分 27 秒,稍微快了一点。
- 10% 堆内内存(50m):


如上图,当 buffer size 调大到 50m 时,耗时 4 分 26 秒,比 15m 的时候快了一点点。
- 10% 堆内内存(50m),不进行 refresh :


如上图,当 buffer size 调大到 50m 时,并且不进行 refresh 时,耗时 4 分 25 秒。
整体来看,增加 buffer size 可以提高写入的性能。这里其实隐含着一个细节的,我们设置 buffer_size = 10m 其实是每个节点都有 10m,每个节点上所有的分片会共享这个 buffer。当我们每个批次 7200 条数据(大约 30m) 会分给 3 个节点进行处理,实际上每个节点接收的是 10m 的数据。
4、调整 Translog Flush 时机
这里我们同样使用上面的 Mapping 模板,需要设置从副本数量为 0,不进行 refresh ,每个批 7200 条数据。
- Translog Flush


如上图,当每个请求都进行 Translog Flush 时,耗时 4 分 22 秒。
- 不进行 Translog Flush
如果不进行 Translog Flush,需要才创建 Mapping 时加入以下配置:
PUT articles_buffer_translog_not_flush{"mappings": { ...... },"settings": {"number_of_shards": 3,"number_of_replicas": 0,"index.refresh_interval": "-1","index.translog.durability":"async","index.translog.sync_interval": "240s","index.translog.flush_threshold_size": "512m"}}


如上图,当每个请求都不进行 Translog Flush 时,耗时 3 分 53 秒。这个优化提升的比较明显,直接进入 3 分钟大关了。
到此,我们从一开始每个批次 3200 条数据的耗时 4 分 39 秒,一路优化到最后的 3 分 53 秒,需要注意的是,部分配置是有特定的使用场景的。
五、问题排查
系统出现问题,绝大部分的情况下是因为资源不够用了,而导致资源不够用的情况有非常多,可能是架构不合理,例如全部节点部署在一台虚拟机上、可能是 Mapping 设计不合理、可能是使用者使用的方式不合理,例如 Bulk 的 size 非常大等。下面提供一些排查问题的思路,但不限于写入操作,因为有可能读操作会影响到系统,导致了写入慢的情况时有发生。
1、内存参数设置不合理
给 ES 的内存不是越多越好的,我们建议一个节点最多不超过 30G,要预留一半的内存给操作系统,这部分堆外的内存 Lucene 会用到。
2、深分页或者返回的结果集过大
深分页的问题我们前门已经有过非常详细的介绍了,不宜用 from = 10000, size = 1000 这样的方式来进行分页。应使用 Point In Time + search after 的方式来处理深分页的问题。另外不要返回过大的结果集,我相信不会有哪个用户会对一次获取 1w+ 的结果感兴趣的。
3、不合理的查询语句导致系统消耗过多的资源
很好理解,我们在使用 mysql 的时候都说不建议使用 “select * from table” 这样的语句,也建议搜索走索引。同样 ES 也是这个道理,需要获取的字段越少,会更有利于提高性能。聚合查询的结果集过大可能会消耗大量的内存资源(如聚合过多的唯一值,时间戳是一个),而使用模糊查询甚至可能会导致内存溢出的问题。另外使用 text 排序也不是一个好主意,也不是一个有意义的事情。
4、数据倾斜,未能充分利用好集群资源
最好将分片均匀分配到各个节点上去,也建议尽量不要使用自定义的文档 ID,而使用 ES 随机的 ID。
5、Mapping 设计、分片和集群容量规划不合理
Mapping 设计的一些建议我们在本章已经介绍过了,而分片和集群容量规划我们在 《睡个安稳觉的关键:集群运维》有非常详细的介绍了。
6、段合并占用大量的 I/O 资源
虽然段合并是在后台运行的,但有时候会占用过多的 I/O 资源。
7、集群处于不稳定的状态,触发大量分片迁移和恢复
例如不断有节点上线和下线,导致分片迁移和恢复,这样会占用大量的资源。
8、并发查询量大和大量 Bulk 写入堆积
系统扛不住的话,扩容吧。写入并发高的话,入队列排队处理也是一种方案,不过需要系统可以接受这种延时。
9、磁盘 I/O 出现瓶颈
磁盘撑不起的时候,可以换 SSD 或者扩容。
10、JVM 垃圾回收不给力
这个就要针对你实际的场景来做 JVM 参数方面的调优了。如果节点不断出现 full gc 的情况,可以考虑加点内存并且重启。
问题排查是一件非常难的事情,一般来说系统出现问题都会伴随着出现 CPU 被占满、频繁触发耗时的 Full GC、内存 OOM、磁盘 I/O 高等现象,然后从这些现象开始进行跟踪。最终结果很可能是 Mapping 设计不合理、系统部署的架构不合理、查询语句不合理等问题。
六、总结
今天为你介绍了一些关于 ES 写入调优相关的方法。
我们从 Mapping 设计开始说起,正确的 Mapping 设计可以有效把性能问题扼杀在摇篮里。而 Mapping 设计遵循着一个重要的思想:够用就好,让系统少干活。
当然除了 Mapping 设计要做好,操作系统和 JVM 层面的配置也会对 ES 的性能有非常大的影响,这部分我们也在 《睡个安稳觉的关键:集群运维》中有过详细的讨论了。
最后我们把重点放在了 ES 参数层面的调优上,主要有以下几个:
- 将索引的从副本分片设置为 0
- 适当加大 index buffer 的大小,在 elasticsearch.yml 中配置 indices.memory.index_buffer_size 的值。
- 加大 index refresh 间隔,降低 segment merge 的频率,可以降低 IO,使用 index.refresh_interval 参数,导完数据后设置回原来的值即可,默认 1s。
- 控制 Bulk 的大小,5m 到 10m 最好。
- 加大 translog flush 的间隔,默认情况下是每个请求都刷盘,其配置为:index.translog.durability: request,现在如果可以接受数据丢失的情况下可以配置为:
index.translog.durability: async index.translog.sync_interval: 60s(自己设置)index.translog.flush_threshold_size: 1gb(自己设置)
