我们知道为了应对海量数据的存储,ES 被设计成一个复杂的分布式系统,利用分布式系统的特性,可以将海量的数据分散到多个节点上存储。ES 的索引是由一个或多个分片组成的,而数据是存储在分片上的,为了更好地利用集群的硬件资源,系统应该把这些数据均匀地写到各个不同节点的分片上,尽量避免产生数据倾斜。
为了避免出现数据倾斜,系统需要一种高效的方式把数据均匀分散到各个节点上存储,并且在检索的时候可以快速找到文档所在的节点与分片。所以今天我们就来了解一下 ES 的路由算法是如何把数据均匀分布到各个节点的,并且了解一下系统如何进行分布式数据检索的。
一、ES 的数据路由算法
当我们需要将数据分散到不同节点上时,我们首先可以想到的是利用映射算法将文档 ID 映射到某个固定的节点上。对于映射算法,一般有以下几个:
| 算法 | 描述 |
|---|---|
| 1. 随机算法 | 数据写入时,将数据随机写到一个分片中去。在查询时由于无法知道对应的文档存在于哪个分片,所以需要遍历所有分片 |
| 2. 中心节点维护数据路由的映射关系 | 存在单点故障、文档量大的时候维护成本高、效率低下、数据迁移可能会非常麻烦等问题 |
| 3. 通过对路由 key 的值进行计算,得出的值对应到相应的分片 | 维护简单,通过计算可以快速路由到对应的分片 |
符合我们需求的映射算法,应该要满足数据写入后可以进行快速定位、查询,并且占用资源还要小,所以随机的算法并不适合。第二种算法通常需要非常多的资源来维护映射关系,并不经常选择。而第三种算法则可以满足系统设计的需求。
ES 的数据路由算法是根据文档 ID 和 routing key 来确定 Shard ID 的过程。默认的情况下 routing key 为文档 ID,路由算法一般情况下的计算公式如下:
shard_number = hash(_routing) % numer_of_primary_shards
当然你可以在请求中指定 routing key,下面是新增数据的时候指定 _routing 的写法:
PUT books/_doc/doc_id?routing=routing_key{"name": "java","id": "book_id"}
ES 使用随机的文档 ID(当我们写入数据时不指定文档 ID,系统会自动分配随机 ID) 和 Hash 算法是可以保证文档均匀地分散到各个分片中的,但是如果文档 ID 是用户自定义的(如上面例子的 doc_id),或者是用户指定 routing key 的时候,这个 hash 出来的值可能会不够随机而导致出现数据倾斜的情况。
其实之前提到过,索引设置了主分片数后就不能修改,如果要修改就需要 reindex(就是数据迁移了),造成这样的一个原因就是路由算法不支持。举个简单的例子,如下:
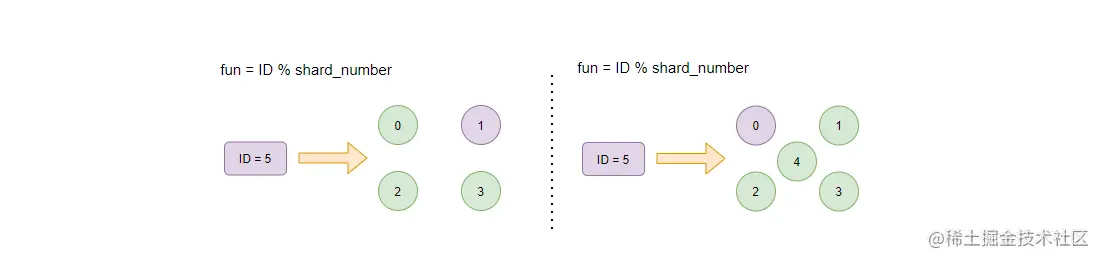
路由算法是用文档 ID 对 Shard 的数量取余数,如上图:当 Shard 数量为 4 的时候,ID = 5 的文档将会存储在紫色的 Shard 1 中;而如果这个时候,我们把分片的数量增加到 5,并且不进行数据迁移的话,那么检索 ID = 5 的文档时,经过路由算法将会得出此文档是存储在 Shard0 中的,但事实是,这个文档一直存在于 Shard1 中。
OK,在有了路由算法后,系统可以很容易地知道每个文档在哪个节点和分片上了,那下面我们来看看分布式搜索的流程是如何实现的。
二、分布式搜索流程
整体来说,ES 的搜索过程可以分为两个阶段:
- Query 阶段:查询阶段,主要获取文档的排序值和文档 ID 到协调节点。并且协调节点通过排序确定要获取的文档 ID 列表。
- Fetch 阶段:通过 multi get 的方式到对应的分片上获取文档数据。
因此,接下来我们就来详细剖析下这两个阶段,除此之外,还会讲解下由 Query 和 Fetch 这种方式带来的深度分页和相关性算法偏离的问题。
Query 阶段
Query 阶段会根据搜索条件遍历每个分片(主分片或者副分片中的其一)中的数据,返回符合条件的前 N 条数据的 ID 和排序值,然后在协调节点中对所有分片的数据进行排序,获取前 N 条数据的 ID。
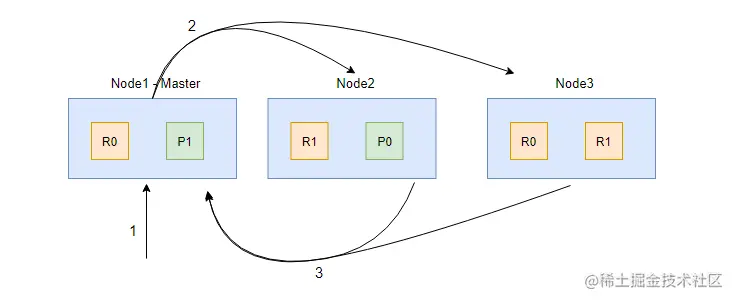
Query 阶段的流程如上图,其中 1、2、3 步解析如下:
- 客户端发起 search 请求到 Node1;
- 协调节点 Node1 将查询请求转发到索引的每个主分片或者副分片中,每个分片执行本地查询并且将查询结果打分排序,然后将 from + size 个结果保存到 from + size 大小的有序队列中。
- 每个分片将查询结果返回到 Node1(协调节点)中,Node1 对所有结果进行排序,并且把排序后结果放到一个全局的排序列表中。
需要注意的是,在协调节点转发搜索请求的时候,如果有 N 个 Shard 位于同一个节点时,并不会合并这些请求,而是发生 N 次请求!
Fetch 阶段
在 Fetch 阶段,协调节点会从 Query 阶段产生的全局排序列表中确定需要取回的文档 ID 列表,然后通过路由算法计算出各个文档对应的分片,并且用 multi get 的方式到对应的分片上获取文档数据。
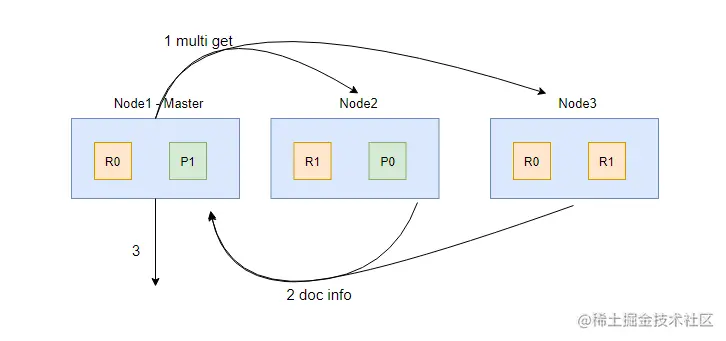
Fetch 阶段的流程如上图,其中 1、2、3 步解析如下:
- 协调节点(Node1)确定哪些文档需要获取,然后向相关节点发起 multi get 请求;
- 分片所在节点读取文档数据,并且进行 _source 字段过滤、处理高亮参数等,然后把处理后的文档数据返回给协调节点;
- 协调节点等待所有数据被取回后返回给客户端。
深度分页的问题
Query + Fetch 的方式看似很合理,但也会产生一些问题:
- 每个分片上都要取回 from + size 个文档(不是 from 到 size,而是 from + size);
- 协调节点需要处理 shard_amount * ( from + size ) 个文档。
在 from + size 很大的情况下,协调节点需要处理的数据就会很多,这个就是深分页产生的原因,所以一般在产品上我们都是一页一页地翻,而不是跳到任意一页。ES 为解决分页的需求提供了 3 种 API,我们将在后续的章节中单独讲解。
相关性算分偏离
从 Query 阶段我们知道,文档的评分是在各自的 Shard 上获取的,而因为 ES 的每个 Shard 就是 Lucene 的一个索引,所以每个分片都是基于自己的数据进行相关性算分的,即分片的相关性算分都是独立的。这样文档的算分只是基于系统中部分数据来计算的,从而会导致打分偏离的情况。
解决这个问题的方式也有多种:
- 如果索引的数据不多的情况下,可以设置主分片数为 1,但这个一般不太现实。
- 索引数据量大的情况下,需要保证数据均匀地分布在各个分片中。
- 使用 DFS Query Then Fetch, 在 URL 参数中指定:_search?search_type=dfs_query_then_fetch。这样设定之后,系统先会把每个分片的词频和文档频率的数据汇总到协调节点进行处理,然后再进行相关性算分。这样的话会消耗更多的 CPU 和内存资源,效率低下!
从这 3 种解决方式来看,基本上只有第 2 种是可用的了,而要保证数据均匀地分布在各个分片中,我们在路由算法的部分提过了,尽量使用 ES 的随机 ID 和 Hash 算法,尽量(在没有具体需求强制下)不要指定 _routing value。
三、总结
本节我为你介绍了 ES 的路由算法和分布式数据搜索的原理。
ES 的数据路由算法是根据文档 ID 和 routing key 来确定 Shard ID 的过程。默认的情况下 routing key 为文档 ID。为了保证数据可以均匀的分布在各个分片中,应尽量使用 ES 的随机 ID 和 Hash 算法。
ES 的分布式搜索分为两个阶段:Query 和 Fetch。系统在 Query 阶段对每个分片上的数据进行查询得出符合条件的文档 ID 和评分,并汇总到协调节点进行排序。在 Fetch 阶段以 multi get 的方式进行文档内容的获取,最终返回结果给客户端。
由于 Query 阶段会把每个分片查询到的数据都汇总到协调节点,所以当使用 from + size 方式进行分页查询并且 from + size 很大的时候,会出现深分页的问题。
因为 ES 的相关性算分会在每个分片上独自计算,所以可能会有相关性算分偏离的情况。为了避免出现这种情况,应尽量使用 ES 的随机 ID 和 Hash 算法。
