通过对之前章节的学习,相信你已经对 ES 相关的知识有了一定的了解。在前面的内容中,我们多次提到了“倒排索引”这个概念,但是一直没有对它进行过详细介绍和讲解,接下来我们会用两篇文章来对倒排索引进行详细介绍:《索引的故事:正排索引与倒排索引简介》和《全文搜索背后的支撑:倒排索引的实现》。
索引从本质来讲就是一种为了加快检索数据的存储结构,就像书的目录一样,可以很快地帮助我们查找到某个章节所在的位置。而 ES 正是通过正排索引和倒排索引来提供高效的数据获取和检索能力的。
为了更好地帮助你理解,这里我们结合一个现实中的例子来说明一下。假如有一天你去参加唐诗宋词背诵大赛,这个比赛主要有两个项目:一个是给定诗词的名称,请你背诵诗词的内容;另一个是给定多个词语,请你说出同时带有这些词语的古诗词的名称,并且背诵诗词内容。对于第一个项目,相信难度不会很大,你多多少少也是可以背诵出几首的。但是对于第二个项目,你可能需要先在心里一首首默念一下,判断内容中是否同时包含给定的词语。很明显,这种逆向操作的难度是要比第一种大的。
如果我们要做一个机器人去参加这个唐诗宋词背诵比赛,面对这两个项目,我们该怎么设计程序才可以让机器人快速地检索出对应的诗词呢?其实在信息检索的领域中,有两个非常重要的技术可以解决这两个需求,那就是我们前面提到的正排索引和倒排索引。
那到底什么是正排索引和倒排索引呢?它们又是如何实现的呢?又有什么区别呢?本文将为你简单介绍正排索引和倒排索引,并且会在下一篇文章中重点介绍倒排索引的实现。
一、正排索引
如果要赢得诗词比赛的第一个项目,那么设计的思路也比较简单:我们可以把诗词的名字作为唯一 ID,诗词的内容作为值,然后用哈希表存储起来,这样查询的时候就可以实现在 O(1) 复杂度下完成对信息的检索,非常高效。像这种实体 ID 到数据实体内容的关联关系的索引我们称为正排索引。
因此,正排索引非常适合处理键值查询的场景。以下的查询你肯定不陌生:
# poetry_title 是主键select author, content from poetry where poetry_title = '静夜思';
上述查询语句实现了以诗词名字(唯一 ID)获取诗词作者和内容的功能。那要满足上述需求,有哪些数据结构可以实现这个正排索引呢?一般实现正排索引的数据结构主要有三种:哈希表、有序数组和 B+ 树。
下面我就为你简单分析一下这几种数据结构的优缺点,综合对比,看看哪种比较适合作为实现正排索引的数据结构。
哈希表
哈希表是一种以键值对(Key-Value)存储的数据结构,我们可以非常高效地使用 Key 来获取对应的 Value 值,其复杂度为 O(1)。哈希表的实现思路非常简单,只需要利用哈希函数将 Key 转换为一个确定的数值,并且将对应的 Value 放到数组对应的位置即可。如果发生哈希冲突,就将对应的数组位置保存为一个列表的地址,相应的 Value 可以插入这个列表的头或者列表的尾巴。  如上图,经过哈希算法,《静夜诗》这首诗的内容被存储在了数组的第一个位置,《陋室铭》和《登鹳雀楼》被存储在了 M 这个位置,并且它们发生了哈希冲突,所以用链表把它们链接起来了。从这里可以看出数据插入只需要计算位置,而且即使发生哈希冲突,也只是将数据放到链表的头部或者尾部,不需要移动数据,所以哈希表的数据插入是非常高效的。
如上图,经过哈希算法,《静夜诗》这首诗的内容被存储在了数组的第一个位置,《陋室铭》和《登鹳雀楼》被存储在了 M 这个位置,并且它们发生了哈希冲突,所以用链表把它们链接起来了。从这里可以看出数据插入只需要计算位置,而且即使发生哈希冲突,也只是将数据放到链表的头部或者尾部,不需要移动数据,所以哈希表的数据插入是非常高效的。
虽然使用哈希表存储数据,可以通过哈希算法快速定位到 Key 对应的 Value 的存储位置从而获取对应的值,但是由于经过哈希算法计算后各个 Key 是无法排序的,所以单是哈希表的结构无法实现范围查询。因此说哈希表非常适合等值查询的应用场景。
有序数组
有序数组的优缺点就更明显了,因为数据有序,可以使用二分法进行查询,其复杂度为 O(log(N)),所以非常适合等值查询和范围查询。但是在每次数据插入时都要移动插入位置之后的所有数据,这个操作的成本就非常高了。如下图,在 EntityX 要插入到 Entity2 后面时,Entity3 和其后面的所有数据都需要往后移动。因此说有序数组适合在存储静态数据的场景下使用。

B+ 树
B+ 树是现在 MySQL InnoDB 索引底层实现的数据结构,它一定程度上解决了有序数组插入数据时的低效,也解决了哈希表无法进行范围搜索的问题,并且 B+ 树非常适合在内存、磁盘上存储和访问,相对于哈希表和有序数组而言,它的优势非常明显,毕竟现在很多应用数据量都是海量的。 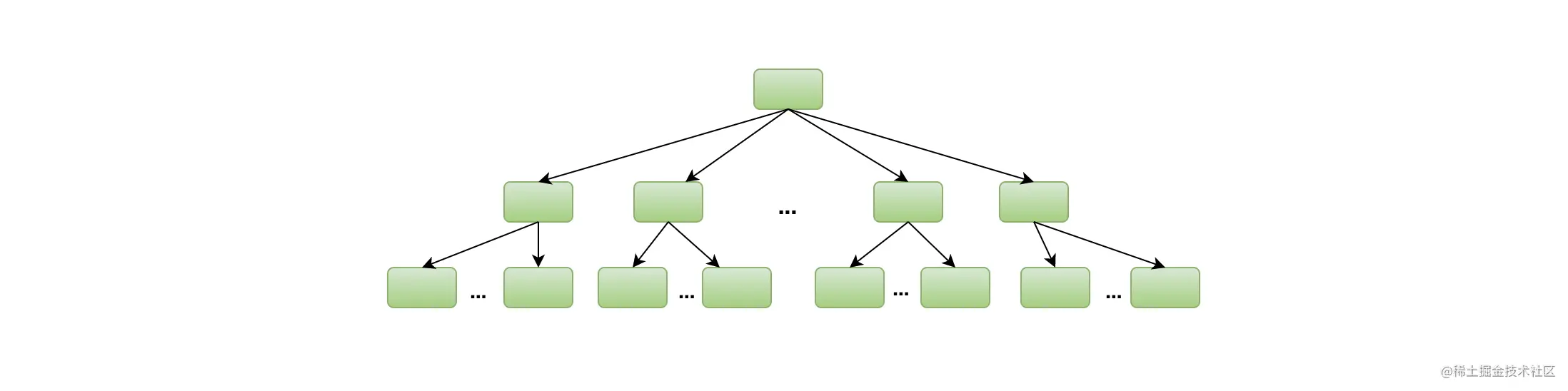 如上图,这是一个 B+ 树的模型,其在 MySQL InnoDB 的实现中每个节点都是一页,每页的默认大小为 16K,所以每页(每个节点)都可以放下多条数据。以 InnoDB 的一个 Int 类型字段索引为例子,每个页可以存储 1000 多条数据,那么上图 3 层的树就可以保存 100 万+的数据了。如果树高 4 层,则可以保存 10 亿+的数据。
如上图,这是一个 B+ 树的模型,其在 MySQL InnoDB 的实现中每个节点都是一页,每页的默认大小为 16K,所以每页(每个节点)都可以放下多条数据。以 InnoDB 的一个 Int 类型字段索引为例子,每个页可以存储 1000 多条数据,那么上图 3 层的树就可以保存 100 万+的数据了。如果树高 4 层,则可以保存 10 亿+的数据。
另外,在优化后,树的第一层一定在内存中,而第二层也大概率在内存中,所以查找数据时磁盘平均的访问次数并不高(InnoDB 还有页缓存)。 一旦数据被定位到某个页后,将其加载到内存中,由于页内的数据是有序的,所以可以使用类似于二分法的方式访问整个页的数据,从而达到快速查询到所需数据的目的。由于 B+ 树在读写上的性能优势,以及适配磁盘的访问方式,其在数据库引擎领域已被广泛应用。
其实数据库技术发展到现在,还有非常多的数据结构应用在搜索引擎的设计中,例如 LSM 树、跳表等,感兴趣的话可以自行查阅相关资料。现在回归到古诗词背诵大赛的需求,下面表格是我们可以找到的诗词数据,根据上面我们学习的实现正排索引的数据结构,到底哪个最为适合呢?我认为哈希表和有序数组都合适,一来是因为古诗词的数据量不会太大,内存可以放得下所有数据,二来是这个项目没有范围查询也没有新增数据的需求,三来哈希表和有序数组的实现比 B+树简单。
| 诗词名字 | 诗词内容 |
|---|---|
| 静夜思 | 床前明月光,疑是地上霜。…… |
| 水调歌头·明月几时有 | 明月几时有?把酒问青天。不知天上宫阙,今夕是何年。…… |
| 陋室铭 | 山不在高,有仙则名。水不在深,有龙则灵。…… |
| 咏鹅 | 鹅,鹅,鹅,曲项向天歌。…… |
二、倒排索引
上面说,正排索引是实体 ID 到实体内容的关系,利用它可以很好地解决第一个比赛项目的需求。但是第二个需求是给定多个词语,找出内容中包含给定词语的诗词,这个我们就没有办法使用正排索引来处理了。但是如果我们把所有诗词的内容进行分词,然后建立各个词语到诗词名称(或者诗词的 ID)的索引会如何?
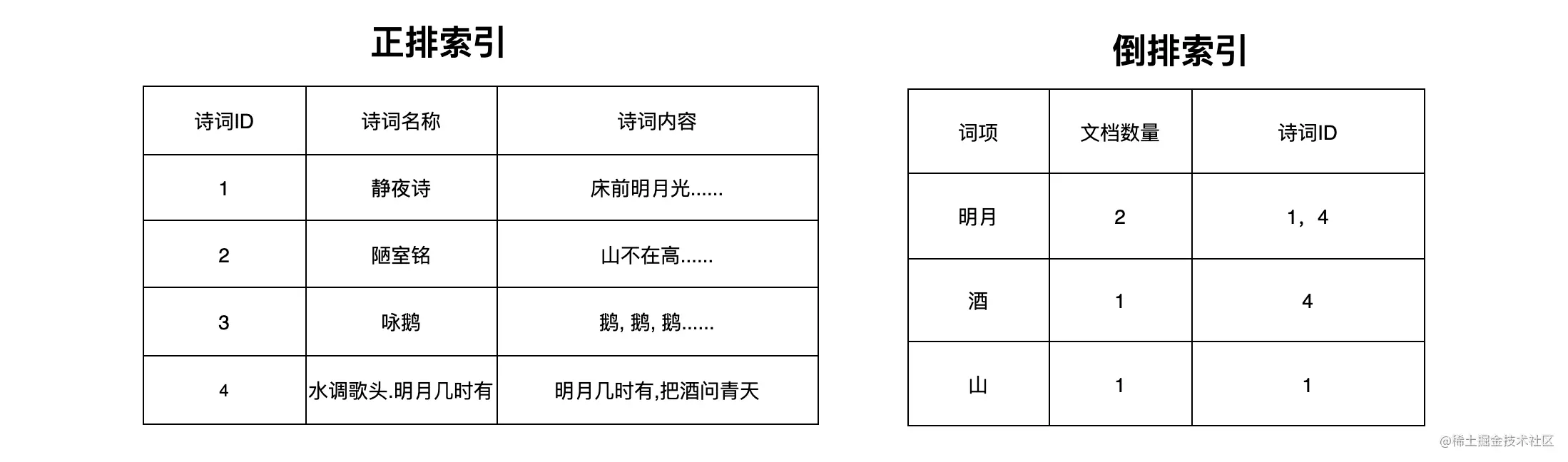 如上图,我们把分词后保存词项到实体 ID 关系的索引称为倒排索引。根据倒排索引,我们可以获取词项对应的诗词 ID,如果有多个词项,我们会有多个列表,然后做交集即可。根据交集出来的 ID 列表再去正排索引中查找对应的诗词内容即可。这样,第二个比赛项目的需求也满足了。
如上图,我们把分词后保存词项到实体 ID 关系的索引称为倒排索引。根据倒排索引,我们可以获取词项对应的诗词 ID,如果有多个词项,我们会有多个列表,然后做交集即可。根据交集出来的 ID 列表再去正排索引中查找对应的诗词内容即可。这样,第二个比赛项目的需求也满足了。
在上图的倒排索引表中,我们除了要保存词项与诗词 ID 的关系外,还需要保存这个词项在对应文档出现的位置,这是因为很多检索的场景中还需要判断关键词前后的内容是否符合搜索要求。 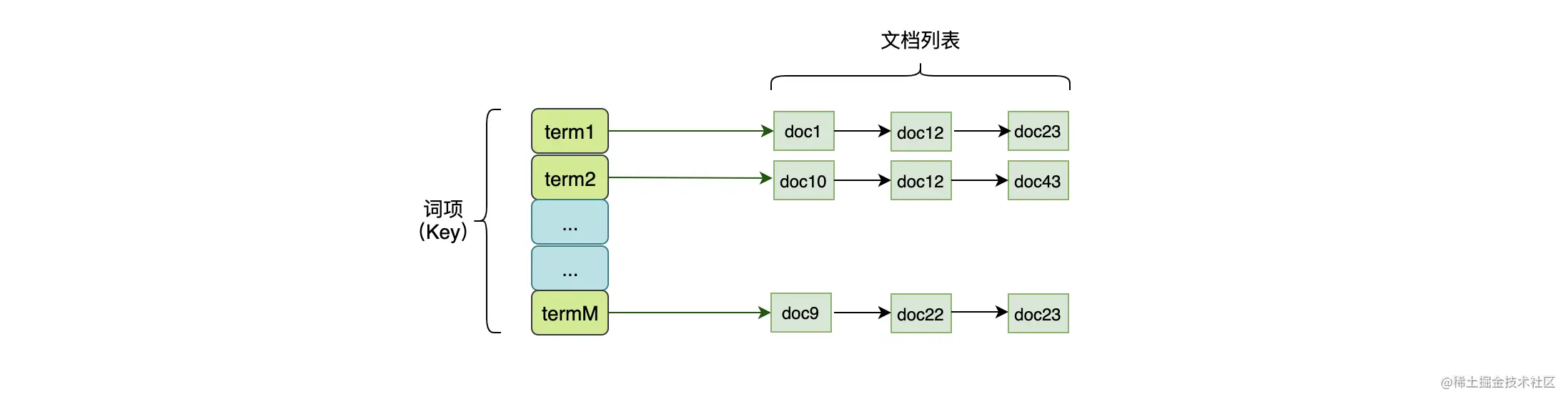 如上图,这个倒排索引使用哈希表来实现也是可以的,其有着 O(1) 查询复杂度,能完美地满足我们的需求。但是呢,现实中数据往往是海量的,如果简单地使用哈希表来实现倒排索引是不可行的,因为存储海量的数据时,系统将会面临下面几个问题:
如上图,这个倒排索引使用哈希表来实现也是可以的,其有着 O(1) 查询复杂度,能完美地满足我们的需求。但是呢,现实中数据往往是海量的,如果简单地使用哈希表来实现倒排索引是不可行的,因为存储海量的数据时,系统将会面临下面几个问题:
- 分词形成的词项(term)可能是海量的,需要可以在内存和磁盘上高效存储;
- 既然词项是海量的,那么如何快速找到对应的词项也是个问题;
- 每个词项对应的文档数可能非常多,也就是上图中文档列表的链表很长;
- 在词项对应的文档多的情况下,多个文档列表间做交集的效率将是个挑战。
其实这四个问题可以分为两个方面:词项方面的问题和文档列表方面的问题。在 Lucene 的倒排索引的实现中,其使用词项索引(Term Index)来解决上述 1 和 2 的问题,而对于 3 和 4,Lucene 对数据进行了压缩处理,使用 Roaring Bitmaps、跳表等技术来进行快速求交集。在面对海量的数据时,系统的设计往往都是非常复杂的,我将在下篇来介绍倒排索引的实现,并且看看这些问题是如何解决的。
三、总结
在这一讲中,我为你介绍了正排索引和倒排索引的定义和简单实现,也提到了倒排索引在实现时面对的几个问题。
我们把记录实体 ID 到数据实体内容的关联关系的索引称为正排索引。正排索引可以使用哈希表、有序数组、B+ 树来实现。哈希表实现的正排索引适合等值查询的应用场景,但不适合应用在范围查询的场景。有序数组在等值查询和范围查询上有着高效率,但不适合有数据改动的应用场景。B+ 树实现的正排索引有着高效的查询效率,非常适合在内存、磁盘上存储和访问,所以在数据库引擎领域已被广泛应用。
我们把保存词项到实体 ID 关系的索引称为倒排索引。 简单的倒排索引可以用哈希表来实现,但现实的应用环境,数据都是海量的,我们需要更高效的数据结构来实现,而这些数据结构和实现将会在下一篇文章中进行介绍。
