ES 是一个强大的搜索引擎,它提供了非常丰富的数据检索 API 来满足用户各种各样的需求。我们今天要介绍的是部分非常基础的全文搜索 API,这部分 API 我们会在日常使用中经常用到,所以第一次接触 ES 的话这部分 API 可以多练习几次。
当我们在查询一些文本内容的时候一般不会做精确匹配,一来性能开销大,二来实际意义不大,正所谓吃力不讨好。
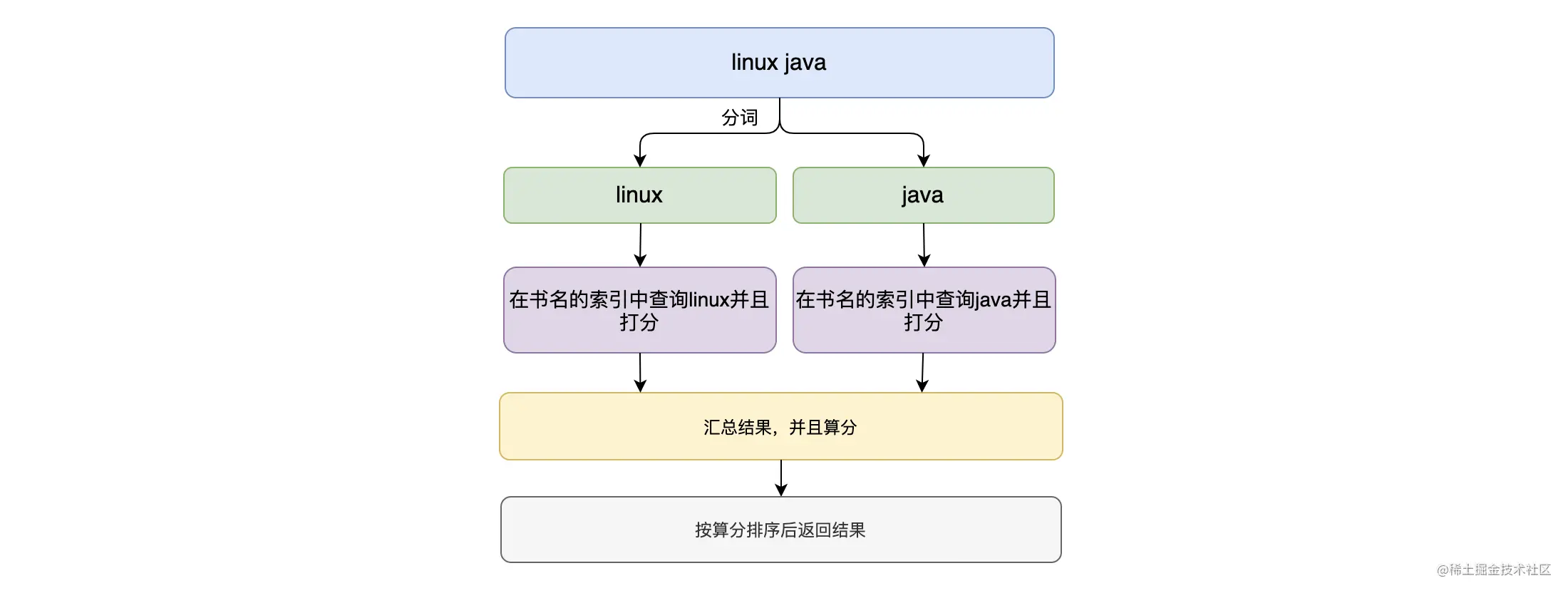
其实在我们写入数据的时候,系统会使用分词器把文本数据进行分词,并且统计每个词语出现的次数等信息。如上图,当我们检索文本数据的时候,会使用同样的分词器对检索内容进行分词,然后与文本内容匹配,根据统计信息给每个词语打分,最后根据公式算出相关性评分(内容的相似性),并且返回相关性最高的 TopN 个文档给用户。
ES 支持全文搜索的 API 主要有以下几个:
- match,匹配查询可以处理全文本、精确字段(日期、数字等)。
- match phrase,短语匹配会将检索内容分词,这些词语必须全部出现在被检索内容中,并且顺序必须一致,默认情况下这些词都必须连续。
- match phrase prefix,与 match phrase 类似,但最后一个词项会作为前缀,并且匹配这个词项开头的任何词语。
- multi match,通过 multi match 可以在多个字段上执行相同的查询语句。
为了更好地理解各个例子,我们还是以在线书店为例子,并且对其进行迭代。今天我们在书本的信息中增加了 price 价格字段、date 出版日期字段。并且在书名(”name”)字段我们使用了 standard 分词器来对文本进行分词处理,这个分词器会将文本按单词切分并且转为小写。
访问这里-gitee、这里-github获取构建数据的示例,在 Kibana 中执行下载后的脚本示例,我们来构建今天需要用到的数据。数据导入完成后,可以使用 match all API 进行查看:
# 匹配所有文档POST books/_search{"query": {"match_all": {}}}
完成上述操作后,下面就正式开始今天的内容啦。
一、match(匹配查询)
匹配查询可以处理全文本、精确字段(日期、数字等),其示例如下:
# 匹配查询POST books/_search{"query": {"match": {"name": "linux architecture"}}}# 结果{"hits" : {"hits" : [{"_id" : "3","_score" : 0.6931471,"_source" : {"book_id" : "4ee82464","name" : "Beginning Linux Programming 4th Edition",......}},{"_id" : "1","_score" : 0.5753642,"_source" : {"book_id" : "4ee82462","name" : "Dive into the Linux kernel architecture",......}}]}}
如上示例利用 match API 进行了一次全文本字段的查询,我们查询书本名字含有 “linux architecture” 的文档,系统匹配了 id 为 3 和 1 的文档,这两个文档的书名字段中含有了 “linux” 或者 “architecture” 词项。
在进行全文本字段检索的时候, match API 提供了 operator 和 minimum_should_match 参数:
operator,参数值可以为 “or” 或者 “and” 来控制检索词项间的关系,默认值为 “or”。所以上面例子中,只要书名中含有 “linux” 或者 “architecture” 的文档都可以匹配上。
minimum_should_match,可以指定词项的最少匹配个数,其值可以指定为某个具体的数字,但因为我们无法预估检索内容的词项数量,一般将其设置为一个百分比。
# 匹配查询POST books/_search{"query": {"match": {"name": {"query": "Dive linux kernea architecture","operator": "or","minimum_should_match": "75%"}}}}
如上示例,至少有 75% 的词项匹配上的文档才会返回。
除了处理全文本外,我们还可以使用 match API 查询包含精确字段的文档,其示例如下:
POST books/_search{"query": {"match": {"date": "2010-06-01"}}}
上述示例将会匹配出版日期为 “2010-06-01” 的书本。
二、match phrase(短语匹配)
简单来说,短语匹配会将检索内容进行分词,这些词语必须全部出现在被检索内容中,并且顺序必须一致,默认情况下这些词都必须连续。其示例如下:
# 短语匹配POST books/_search{"query": {"match_phrase": {"name": "linux kernel" # 换成 "linux architecture" 是无法匹配的}}}# 结果{"hits" : {"max_score" : 0.5753642,"hits" : [{"_id" : "1","_score" : 0.5753642,"_source" : {"book_id" : "4ee82462","name" : "Dive into the Linux kernel architecture",......}}]}}
如上实例,查询书名中带有 “linux kernel” 短语的书本。默认的情况下,当我们搜索书名中带有 “linux architecture” 的时候,是无法命中文档的,因为没有书本的名字带有这个短语。这个时候可以使用 slop 参数来指定词项间的距离差值,即两个词项中可以含有多少个其他不相关的词语,slop 默认是 0。
# match_phrase 使用 slopPOST books/_search{"query": {"match_phrase": {"name": {"query": "linux architecture","slop": 1}}}}# 结果为命中文档 id 为 1 的文档
如上示例,当 slop 设置为 1 的时候,即使文本内容为 “…… Linux kernel architecture” 也是可以进行匹配的,其中 “kernel” 这个不相关的词被跳过了。
三、match phrase prefix (短语前缀匹配)
match phrase prefix 与 match phrase 类似,但最后一个词项会作为前缀,并且匹配这个词项开头的任何词语。可以使用 max_expansions 参数来控制最后一个词项的匹配数量,此参数默认值为 50。使用实例如下:
# 匹配以 "linux kerne" 开头的短语POST books/_search{"query": {"match_phrase_prefix": {"name": "linux kerne"}}}# 匹配以 "linux kerne" 开头的短语,每个分片最多匹配 2 个POST books/_search{"query": {"match_phrase_prefix": {"name": {"query": "linux kerne","max_expansions": 2}}}}
如上示例,第一个例子可以匹配书名中含有 “linux kernea”、”linux kerneb” …… 等短语的文档。而第二个例子,我们限制了最后一个词项的通配匹配个数为 2。需要注意的是,max_expansions 参数是分片级别的,也就是 max_expansions = 2 的话,每个分片最多匹配 2 个文档,如果有 3 个分片的话,最多返回 6 个匹配的文档。
一般来说 match_phrase_prefix API 可以实现比较粗糙的自动建议功能,但要实现自动建议的功能,可以使用 Suggest API(我们后续的内容将会介绍)。
四、multi match
multi-match API 构建在 match 查询的基础上,可以允许在多个字段上执行相同的查询。
# multi match APIGET /books/_search{"query": {"multi_match": {"query": "linux architecture","fields": ["nam*", "intro^2"]}}}
如上示例,fields 参数是一个列表,里面的元素是需要查询的字段名字。fields 中的值既可以支持以通配符方式匹配文档的字段,又可以支持提升字段的权重。如 “nam*“ 就是使用了通配符匹配的方式,其可以匹配到书名(name)字段。而 “intro^2” 就是对书本简介字段(intro)的相关性评分乘以 2,其他字段不变。
multi-match API 还提供了多种类型来设置其执行的方式:
best_fields: 默认的类型,会执行 match 查询并且将所有与查询匹配的文档作为结果返回,但是只使用评分最高的字段的评分来作为评分结果返回。
most_fields: 会执行 match 查询并且将所有与查询匹配的文档作为结果返回,并将所有匹配字段的评分加起来作为评分结果。
phrase: 在 fields 中的每个字段上均执行 match_phrase 查询,并将最佳匹配字段的评分作为结果返回。
phrase_prefix: 在 fields 中的字段上均执行 match_phrase_prefix 查询,并将最佳匹配字段的评分作为结果返回。
cross_fields:它将所有字段当成一个大字段,并在每个字段中查找每个词。例如当需要查询英文人名的时候,可以将 first_name 和 last_name 两个字段组合起来当作 full_name 来查询。
bool_prefix:在每个字段上创建一个 match_bool_prefix 查询,并且合并每个字段的评分作为评分结果。
上述的这几种类型,无非就是设置算分的方式和匹配文档的方式不一样,可以使用 “type” 字段来指定这些类型,以 best_fields 为例,其示例如下:
# multi match APIGET /books/_search{"query": {"multi_match": {"query": "linux architecture","fields": ["name", "intro"],"type": "best_fields", # 指定对应的类型"tie_breaker": 0.3}}}
如上示例,此查询将会在 books 索引中查找 “name” 字段包含 “linux “ 或者 “architecture” 的文档或者在 “intro” 字段中包含 “linux “ 或者 “architecture” 的文档。
一般来说文档的相关性算分由得分最高的字段来决定的,但当指定 “tie_breaker” 的时候,算分结果将会由以下算法来决定:
- 令算分最高的字段的得分为 s1
- 令其他匹配的字段的算分 * tie_breaker 的和为 s2
- 最终算分为:s1 + s2
“tie_breaker” 的取值范围为:[0.0, 1.0]。当其为 0.0 的时候,按照上述公式来计算,表示使用最佳匹配字段的得分作为相关性算分。当其为 1.0 的时候,表示所有字段的得分同等重要。当其在 0.0 到 1.0 之间的时候,代表其他字段的得分也需要参与到总得分的计算当中去。通俗来说就是其他字段可以使用 “tie_breaker” 来进行“维权” 。
更多关于的 multi-match API 用法请参考官方文档。
五、总结
本文为你介绍了几个 ES 全文搜索的 API。
我们可以使用 match API 来做匹配查询,其既可以查询全文本的内容也可以查询精确字段的内容。同时在做全文本查询的时候提供 operator 参数来控制词项间的关系,而使用 minimum_should_match 可以控制命中词项的个数或者比率。
可以使用 match phrase API 来做短语查询,其提供了 slop 参数来控制词项间能有多少个不相关的词语,默认是 0 个。而 match phrase prefix API 与 match phrase 类似,只不过 match phrase prefix API 的最后一个词项会作为前缀来匹配与其相同的任何词语,默认情况下最多匹配 50 个,可以使用 max_expansions 参数来控制。
可以使用 multi-match API 在多个字段中执行同一个查询语句。其支持以通配符的方式来匹配需要查询的字段,并且支持提升字段的权重来影响这个字段的相关性评分。 multi-match API 还支持了多种类型来决定其匹配文档的方式和相关性评分的计算方式。
其实总结这几个 API 的用法和思路,全文搜索重点在于如何做文档匹配和文档算分。ES 提供的全文搜索的功能是非常丰富的,本文也只是挑了些简单但又重要的功能来介绍,更多的 API 和参数使用可以参考官方文档。
最后,如果大家对这些 API 的使用还有点生疏的话,可以参考官方文档多实操几次。
好了,今天的内容到此为止。欢迎你在留言区与我分享你的想法,我们一起交流、一起进步。
