我们知道 ES 检索数据在底层实现的时候非常依赖倒排索引这种数据结构,但在做聚合查询的时候,ES 会用什么样的数据结构去进行处理呢?是单纯地借助倒排索引?聚合里面会有什么坑,什么样的聚合操作会严重影响性能?
为了更清楚地理解聚合操作,今天我们来简单探讨一下 ES 聚合查询的内部实现原理。所以今天我们的内容主要有:
- doc_values 在聚合中的作用。
- Ordinals Mapping 对聚合的影响。
- 聚合查询的执行过程简介。
- 什么是 High Cardinality,其对聚合有什么影响。
一、不合适聚合操作的倒排索引
先来思考一个问题,假如只有倒排索引,那么以下这个聚合操作该如何执行:
POST books/_search{"query": {"match_phrase": {"name": "linux"}},"aggs": {"author_agg": {"terms": {"field": "author"}}},"size": 0}
如上示例,其中 author 字段是 keyword 类型。示例中通过查询书名中带有 “linux” 的书本,并且对这些书本的作者进行分组聚合,其执行过程分为两步:
- 通过 query 查询出匹配的文档的 id 列表。
- 根据 query 查询的结果(id 列表)查询聚合字段的值,然后对这些值进行分桶聚合统计。
我们知道,倒排索引非常有利于全文搜索,所以对于第一步来说其实没啥压力的,其执行流程如下:
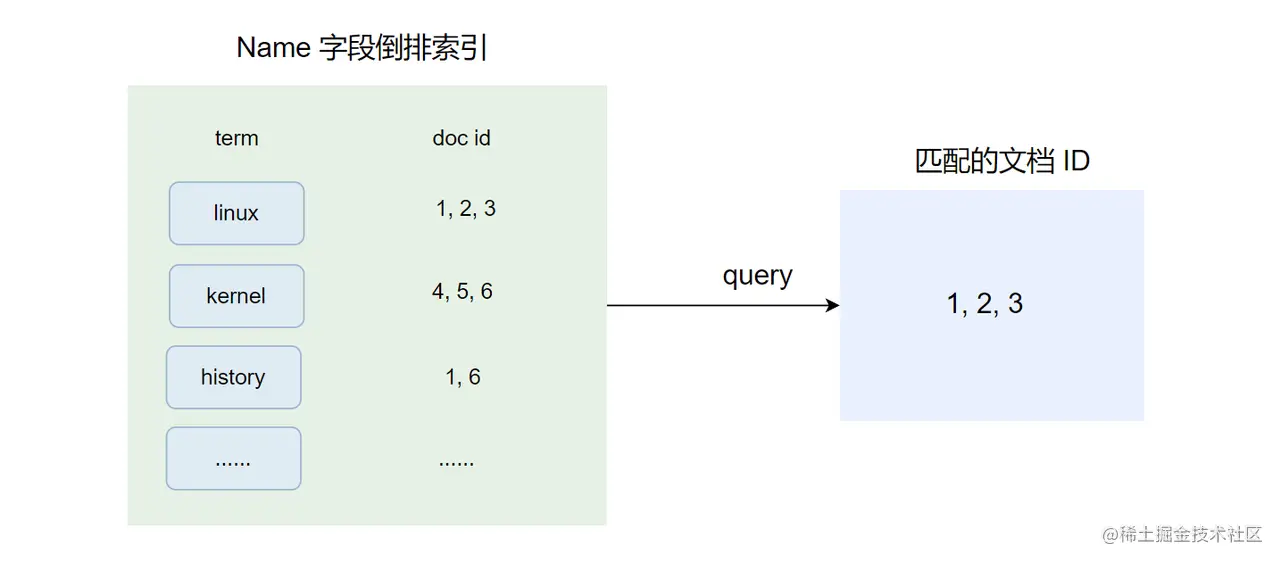
如上图,第一阶段将会命中文档 1、2、3,此时倒排索引可以很好地满足查询的需求,但第 2 步的聚合需求呢? 下图是 author 字段的倒排索引:

要对第一步命中的文档 1、2、3 的 author 字段进行分组聚合,必须要找出这些文档的 author 字段的值才能进行操作。 所以当我们只有倒排索引来处理聚合的过程,此时只能遍历整个 author 字段的倒排索引,对于每一个 term 将其对应的 doc id 与第一步命中的文档 id 做对比,然后记录 term 和这两个 doc id 列表的交集:
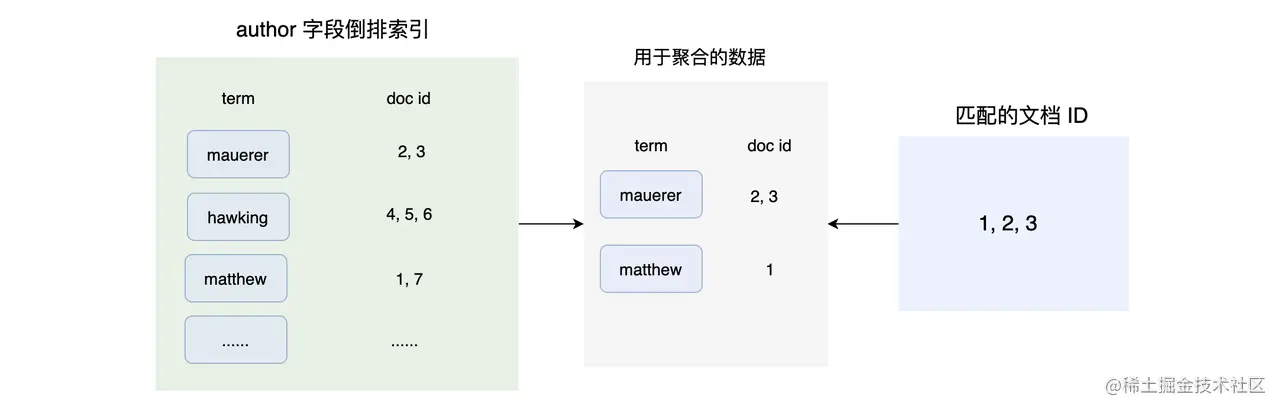
如上图,最后根据求出的交集数据进行聚合统计操作。其实你会发现,这个求交集数据的做法是非常耗时的,因为要遍历整个倒排索引。而要高效完成这个需求,正排索引就非常合适了:通过文档 id 获取文档或者文档中某个字段的内容。
在本小册中我们提到过的概念中属于正排索引的有:doc_values 和 fielddata。今天后续的内容主要跟 doc_values 相关,而与 fielddata 相关的内容我们以后有机会再一起探究。
二、doc_values 正排索引
通过上一小节我们知道,倒排索引可以提供高效的全文检索能力,但是不能高效地完成对数据的聚合和排序操作,此时就需要正排索引了。
一个字段如果要建立正排索引就需要打开 doc_values(当然 text 类型的字段打开 fielddata 也是可以的),默认的情况下 ES 会为几乎所有的字段打开 doc_values,但 text、annotated_text 除外。doc_values 其实并不神秘,它本质上是一个序列化后的列式存储结构,其在数据索引的时候建立,其存储的值与 _source 中的值是相同的。由于 doc_values 是一个正排索引,所以 doc_values 适用于排序、聚合、脚本访问(access to field values in scripts )等操作。
因为要建立正排索引,所以打开 doc_values 属性的字段会消耗一定的磁盘空间,并且数据索引的时候会慢点。doc_values 产生的正排索引保存在 .dvm 和 .dvd 文件中:

如果你想要进一步了解 .dvm 和 .dvd 的结构,可以参考此文档。
doc_values 通过序列化数据结构到磁盘上,可以依赖操作系统的文件系统缓存来缓存数据,而不需要占用 JVM 的堆内内存。当然,doc_values 的数据是按需加载,因为 doc_values 可能会很大,如果全量加载到内存中,可能因装不下而发生 OOM。
当我们确定一个字段不需要进行排序和聚合时,可以考虑关闭其 doc_values 属性。但是遗憾的是,如果你想重新打开某个字段的 doc_values 属性,需要重建索引(reindex)。那什么样的字段可以关闭 doc_values 属性呢?带有唯一属性的字段其实是没有必要打开 doc_values 的,例如实体 id,它们一般都是 UUID 类型,我们也不会拿它们来进行聚合、排序,此时可以关闭 doc_values。要关闭 doc_values 的属性可以使用如下示例:
PUT my-index-000001{"mappings": {"properties": {"status_code": {// 默认开启了 doc_values"type": "keyword"},"session_id": {"type": "keyword",// 明确关闭 doc_values"doc_values": false}}}}
最后 doc_values 的特性可以总结为以下几点:
- doc_values 其实是一个正排索引。
- 除了 text 类型的字段,其他默认都是打开的。
- doc_values 正排索引在数据写入的时候就创建,跟倒排索引一样。
- doc_values 的数据存储在 .dvm 和 .dvd 文件中,可以利用文件系统缓存进行缓存,并且按需加载。
- doc_values 适用于排序、聚合、脚本访问(access to field values in scripts )等操作。
关于doc_values 的信息,可以参考这份官方文档。
三、Ordinals Mapping
1、什么是 Ordinals
上面提到 doc_values 会利用文件系统缓存来缓存数据,并且是按需加载的。现在需要考虑这样一种情况:在我们维护的短信系统里有 1 亿条数据,每条数据都有一个 status 字段来表示这条短信的发送状态,status 的可选值为:sending、failed、delivrd。那么光保存这个 status 值就要花费 600M 到 700M 内存。
那怎么做可以节省内存呢?要节省空间一般就两种方式:编码和压缩。这里可以将字符串排序后进行编码,然后记录这张编码表,并且数据中的 status 使用编码后的值来保存,这样一来可以将所需要的内存减少到 100M。
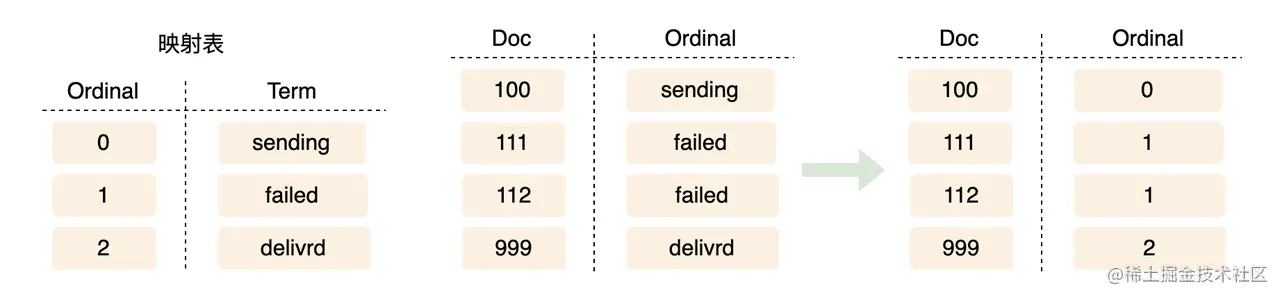
如上图,图中的映射表就是 Ordinals Mapping 了,其实这里的道理浅显易懂,就是将比较长的字符串通过编码的方式减少其占用的空间。
2、Global Ordinals
可惜的是上述的 Ordinals Mapping 是 Segment 级别的,而聚合操作是需要收集整个 Shard 的数据,也就是要遍历所有的 Segment。所以为了可以在 Shard 层面可以使用 Ordinals,就需要一个全局的 Ordinals Mapping,也就是 Global Ordinals Mapping。Global Ordinals Mapping 是在构建在 Segment Ordinals Mapping 上的,所以其维护与 Segment Ordinals Mapping 间的转换关系。Global Ordinals Mapping 与 Segment Ordinals Mapping 关系如下图:
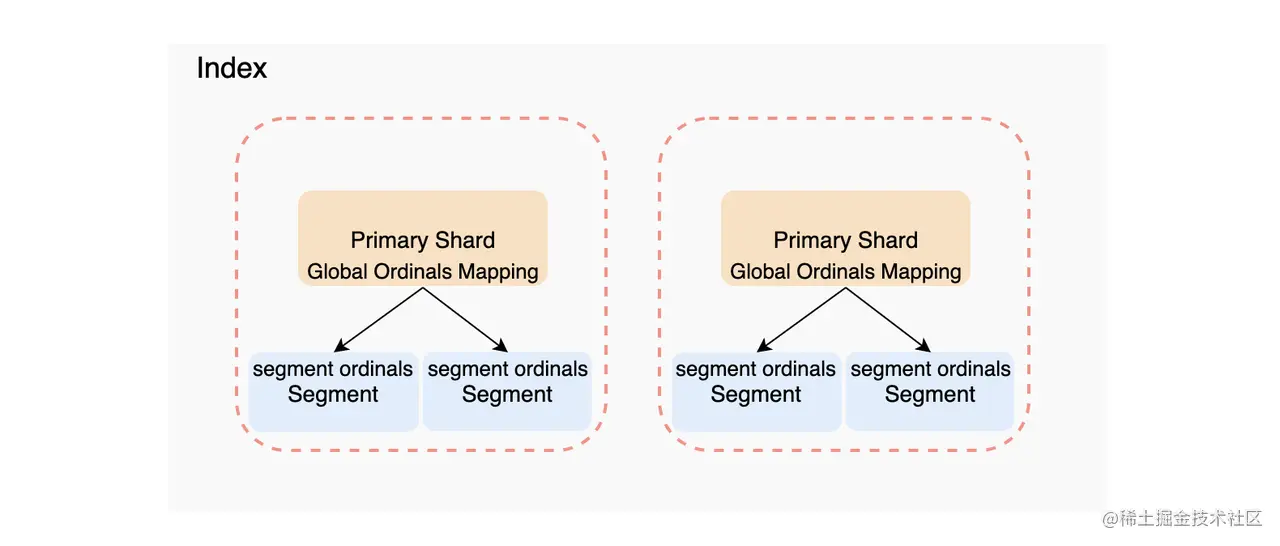
3、Global Ordinals 的加载时机
如果要使用 Global Ordinals Mapping,那么其必须要在搜索前构建。默认的情况,其会在第一次使用的时候才会被加载,这个有利于提高写入的速度,因为一旦有新的 Segment 生成,已经生成的 Global Ordinals Mapping 就需要重新构建,这个是要消耗资源的。
但如果你的系统是搜索优先的话,可以通过提早加载 Global Ordinals Mapping 来优化聚合的速度:
PUT my-index-000001/_mapping{"properties": {"tags": {"type": "keyword","eager_global_ordinals": true}}}
当 eager_global_ordinals 设置为 true 的时候,Global Ordinals Mapping 将会在 Shard refreshed 时构建, 这样做会把本应该属于在搜索时才构建 Global Ordinals Mapping 直接转换到在索引数据时就进行构建。
4、什么时候会使用 Global Ordinals Mapping
Ordinals Mapping 只会在“字符串类型”的字段上构建,“数字类型”的字段如 geo、date 等是不需要 Ordinals Mapping 的。当一个搜索请求包含以下几种情况将会使用到 Global Ordinals Mapping:
- 对 keyword、ip、flattened 类型字段进行分桶聚合(Bucket aggregations)的时候。
- 对一个打开了 fielddata 属性的 text 类型字段进行分桶聚合(Bucket aggregations)的时候。
- 操作父子文档(join 类型的字段),包括 has_child 查询、parent 聚合。
需要注意的是 Global Ordinals Mapping 会使用堆内存进行存储,这部分内存属于 field data cache(这里不展开了,可以看官方文档)。所以当我们聚合一个大基数(High Cardinality)字段的时候可能会触发 field data 熔断,就是说假如你的字段是一个 UUID 字符串(32个字节),每条数据都不一样,那么这个字段的 Global Ordinals Mapping 将会消耗非常多的内存资源。
更多关于 Global Ordinals Mapping 的信息,你可以参考官方文档。
四、聚合查询的过程
聚合的详细过程是非常复杂的,没办法在这里进行展开,但我们可以简单了解一下其执行过程。
ES 的 Term 聚合操作其实并不是我们认为的那样先进行查询,然后再在查询的结果上做聚合的。ES 会先加载我们上面介绍的 Global Ordinals Mapping,然后以 Global Ordinals Mapping 的每一项作为一个 bucket,最后遍历查询的结果,将统计数据映射到每个 bucket 中。此时你会发现,如果聚合字段是 High Cardinality 的话,构建 Global Ordinals Mapping 将会消耗大量的时间和资源。
一个简单的 term 聚合总的来说大致步骤如下:
- 为要聚合的字段加载 Global Ordinals Mapping(如果需要的话),构建分桶,这个过程的耗时会跟文档数量、要加载的段数量、字段的基数(Cardinality)等有关。
- 执行 query,得到匹配的文档 ID,然后通过聚合字段的 doc_values 得到聚合字段的值的集合。
- 将得到的字段的值的集合映射到分桶里,然后统计各个分桶的数据。
- 根据设置的 size,获取 top N 返回。
对于多层次的聚合,其过程则更加复杂,对这个感兴趣的话可以进一步深入研究。
五、实践案例,基于 High Cardinality 字段的聚合
好了,上面说了那么多理论上的东西,可能读到这里都有点晕了,下面我们搞个例子来加深对上述概念的理解。
小明维护着一个短信系统的索引 sms,这个索引有一个 phone 的字段记录用户的手机号码,其类型是 keyword 的。每当给用户发送一条短信时,系统会写入一条数据,当前系统已给超过 10 亿用户发过短信了,现在小明要统计库里收短信最多的 1000 位用户和对应的短信数量。
GET sms/_search{"aggs": {"sms_count": {"terms": {"field": "phone","size": 1000}}},"size": 0}
小明很快就写好了上述的统计示例,这一看也挺简单的,但是小明发现这统计运行得贼慢。一开始小明以为是需要聚合的数据太多导致的,那就将数据限定在一天内吧,于是执行以下聚合:
GET sms/_search{"query": {"range": {"sent_time": {"gte": "2022-08-03T00:00:00Z","lt": "2022-08-04T00:00:00Z"}}},"aggs": {"sms_count": {"terms": {"field": "phone","size": 100}}},"size": 0}
但结果还是一样很慢,那到底为啥呢?下面我们来帮小明分析一下为啥这个语句运行这么慢。
首先通过排查,我们发现 ES 的部署架构、分片数量等都比较合理,排除了 系统架构方面的问题。然后通过分析发现系统已经有超过 10 亿的用户了,说明 phone 这个字段是大基数的(High Cardinality),此时对 phone 字段进行聚合会触发加载 Global Ordinals Mapping 的过程!即使加了 query 语句对需要聚合的数据进行过滤,但 Global Ordinals Mapping 是在查询最开始的时候构建的,也就是在 Filter 前!
所以即使我们过滤出的聚合数据只有几条,在发生 High Cardinality 的情况下,依然会非常耗时,因为花费大量时间来构建 Global Ordinals Mapping。
那如何解决这个问题?根据 Global Ordinals Mapping 特性有以下几个解决方式:
- 因为 Global Ordinals Mapping 是 Shard 层面的,所以增加 Shard 的数量,可以减少每个 Shard 的 Global Ordinals Mapping 中项的量。这种情况下,需要字段可以通过这种方式减少在每个Shard 中数量。显然对于 phone 来说,这个是不行的,除非用 routing key 把特定的 phone 分配到同一个 Shard 中去。并且增加主分片需要 reindex 操作,所以也不是一个好的选择。
- Global Ordinals Mapping 是在使用时构建的,可以通过将 Global Ordinals Mapping 的构建时机转到数据写的时候,可以设置大一点的 refresh interval 和设置 eager_global_ordinals 为 true。
- 修改 terms 聚合的 execution_hint 值来跳过 Global Ordinals Mapping 的构建步骤,在 terms 聚合中 execution_hint 可选为 map 或者 global_ordinals:
- map,直接使用字段的值来进行分桶聚合统计,适合在聚合少量数据的时候使用,也就是不使用 Global Ordinals Mapping 了 。
- global_ordinals,使用 Global Ordinals Mapping 来辅佐聚合数据。
execution_hint 的使用示例如下:
GET sms/_search{"query": {"range": {"sent_time": {"gte": "2022-08-03T00:00:00Z","lt": "2022-08-04T00:00:00Z"}}},"aggs": {"sms_count": {"terms": {"field": "phone","execution_hint": "map","size": 100}}},"size": 0}
当聚合少量数据的时候可以使用 execution_hint = map 的方式来处理,这种方式或者可以解决小明第二种情况的问题,但是要聚合全量数据的时候还是没有办法解决。我的建议是,通过其他方式将库里的数据进行处理,然后记录每个 phone 对应的次数供后续查询使用,又或者将原来的索引改造成按月、按周、按日来生成,这样可以降低单个 Shard 中的数据量。
你可以参考这个 issue 来看看别人对于 Global Ordinals Mapping 和 High Cardinality 的讨论。
六、总结
今天主要介绍了 doc_values 和 Global Ordinals Mapping 在聚合中的作用,并且简单介绍了聚合的执行过程。
也通过一个案例讲解了 High Cardinality 对聚合操作的影响,并且介绍 execution_hint 的配置,当然不同类型的分桶聚合会有其他 execution_hint 的选项,这个你可以参考具体的分桶聚合的分档。要记住的是,对 High Cardinality 字段进行分桶聚合,百害而无一利,所以要尽量避免。
当然对于聚合来说,本文的内容只是冰山一角,后续又机会的话,我们再来探讨聚合里的其他话题。对于 ES 使用来说,你除了要熟知其内部的原理外,一个查询的好坏也很大程度取决于你对数据的熟悉程度。
