集群运维涉及的知识是非常多的,并且需要你经过长期的实践才能有所收获。今天的主题并不是 “xxx问题的解决方案”这类的,因为每个团队遇到的问题、集群规模、数据规模、集群配置等都不一样,无法简单就某种问题给出准确的答案。
今天我们主要介绍的都是最基本的内容,包括以下几点:
- 常见的部署架构
- 如何做集群容量规划
- 如何设计和管理分片
- 线上环境的一些重要的配置
- 简单聊聊集群监控
其实集群运维这章本身安排了数据读写调优的部分的,但是限于篇幅的限制,这部分的内容将会在加餐的部分中出现。那废话不多说,下面就正式开始今天的内容把。
一、常见的架构和部署方式
在 《磨刀不误砍柴工:ES中的基本概念与名词解析》中我为你介绍了 ES 中各种节点类型和它们的职责,并且也介绍了如何配置让一个节点成为各种角色类型。如果这部分内容你有点遗忘的话,请先自行回顾。
一般来说,在部署的时候集群节点有两种形式:
- 每个节点多种角色,消耗的主机资源少,适合开发环境部署。
- 每个节点单一角色,消耗的主机资源多,适合在线上部署。
1. 每个节点多种角色
一般来说我们在开发环境中部署 ES 时会让一个节点承担多种角色,这让可以很大程度上节省机器资源。如果你的开发环境并发量很大或者存储数据很多,需要以线上环境的规模来部署的话,这种方式就不适合了。
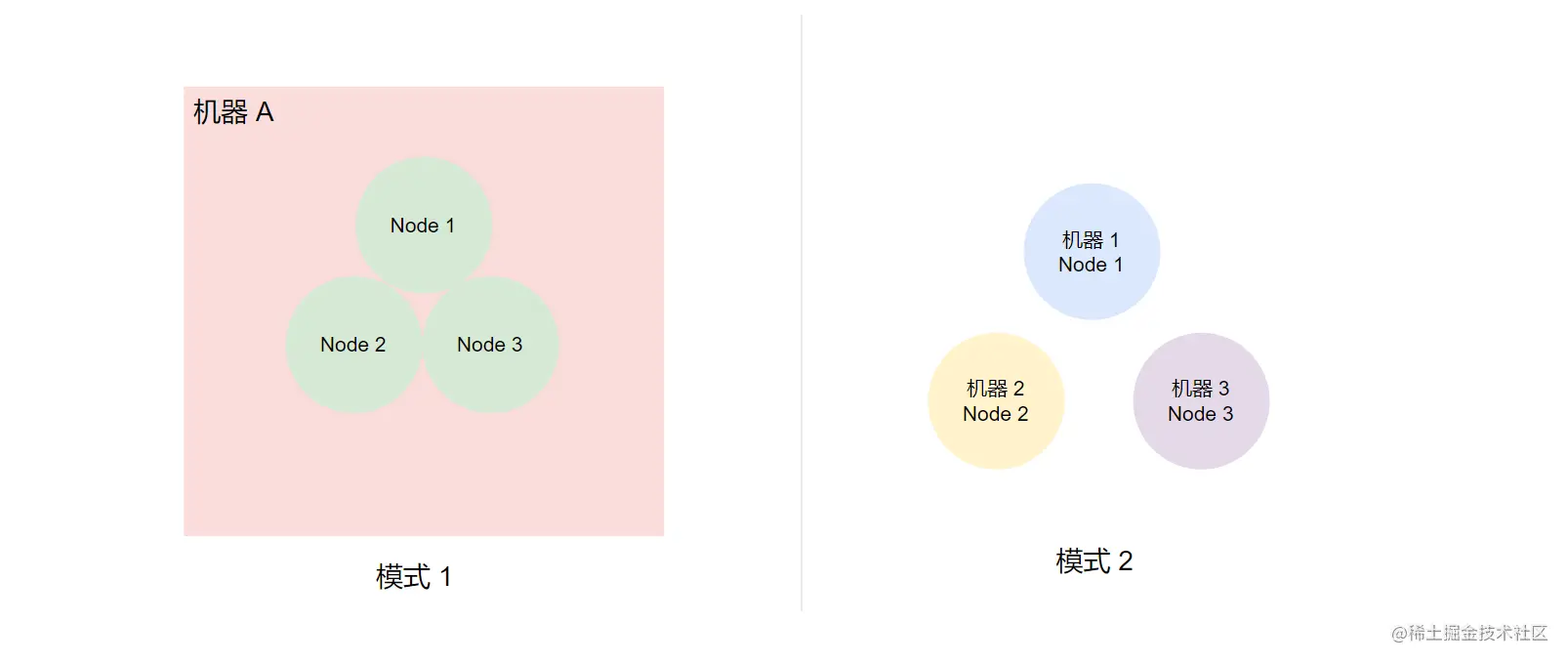
如上图,如果每个节点都配置多种角色的话,模式 1 我们就非常熟悉了,这个就是我们伪集群安装脚本安装完成后的集群架构,在一台机器上部署了多个 ES 实例。而如果我们把每个 ES 实例分别部署在不同的机器上的时候,其架构图如模式 2。一般来说,如果你的开发环境资源够用的情况下,我建议你部署模式 2。
2. 每个节点单一角色
上面提到过每个节点单一角色会消耗比较多的机器资源,所以适合在线上部署。那让每个节点职责分离的好处是啥呢?总结下来有以下几点:
- 每种类型的节点其对硬件的需求都不一样,可以按需分配。例如数据节点需要高配置的 CPU、内存、磁盘,而预处理节点 (Ingest Node)节点则需要高配置的 CPU、低配置的磁盘、中等配置的内存。
- 可以动态地对某种节点进行扩容,例如读的并发量量增多了,可以增加协调节点。
如上所述,一般来说不同角色类型的节点对硬件要求不同,下面表格整理了各种类型节点所需的硬件要求:
| 节点类型 | 职责 | 配置 |
|---|---|---|
| Master 候选节点 | Master 负责了整个集群的状态管理 | 低配置的 CPU、内存、磁盘 |
| 数据节点(Data Node) | 负责数据存储和读取 | 高配置的 CPU、内存、磁盘 |
| 协调节点(Coordinating Node) | 负责请求的分发,搜索结果的整合 | 高配置的 CPU、中等配置的内存、低配置的磁盘 |
| 预处理节点(Ingest Node) | 负责处理数据、数据转换 | 高配置的 CPU、中等配置的内存、低配置的磁盘 |
| Warm & Hot Node | 存储冷、热数据的数据节点 | Hot 类型的节点,都是高配配置,Warm 都是中低配即可 |
这个表其实很好理解,要满足相应的功能就要有相应的硬件资源来支持。负责数据存储就要有好的磁盘、读取的数据要缓存起来的话内存少不了等等。但是这里所谓的高、中、低配置是相对的,总不能平均 10 个并发每秒,就要给协调节点 32 核 30G 内存是吧。所以具体情况具体分析。
好了,由于每个节点单一角色,所以可以组合出来的集群形式或者架构有很多种,下面介绍常见的架构类型。
1、基本架构

如上架构图,我们在协调节点前加了一个 LB(负载均衡器)来对请求负载到各个协调节点。上述架构的好处是,可以单独增加协调节点来应对并发量增加的情况,也可以单独增加数据节点对集群存储量进行扩容。为了防止 Master 出现单点故障造成集群不可用的情况,我们部署了 3 个 Master 候选节点,其中一个成为了 Master。如果需要部署 Kibana 和 Cerebro 可以将它们部署在协调节点上。
这个种架构是线上部署最基本的架构,如果没有特别的情况,你线上集群的配置都应该比这个强,毕竟谁都不想被关小黑屋!
需要注意的是,如果你的集群节点都在一个机房,那么应该把这些节点尽量分配在不同的机架上,不然一个机架断电、断网可能导致整个集群直接宕机。
2、读写分离架构
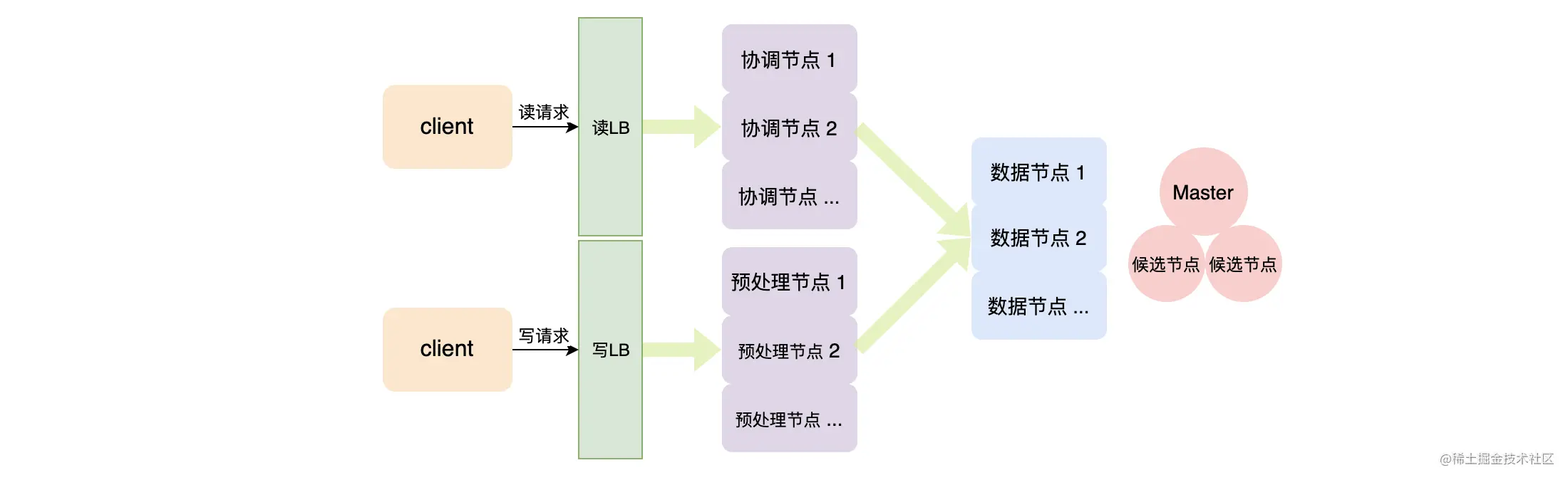
如上架构图,在业务上有需要预处理的数据时,采用读写分离的架构。增加一个写操作的 LB 和多个预处理节点(Ingest Node),并且把写请求从写 LB 负载到各个预处理节点上即可。这种架构下可以动态调整预处理节点个数来满足数据预处理、写入的需求。
3、多机房异地多活
如下架构图,在我们介绍副本和 ES 数据模型的时候,我们提到过 PacificA 算法并不适合跨机房的网络环境,所以以下的这种跨机房的部署方式是有问题的。
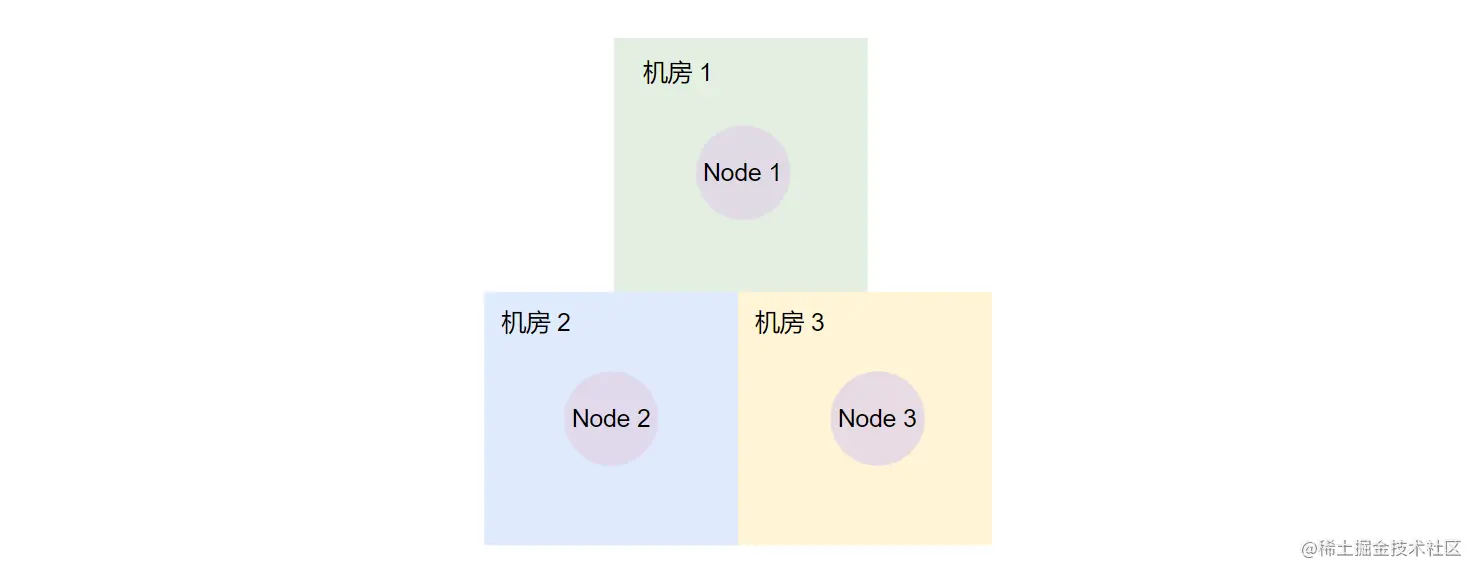
那异地多活该怎么做呢?我们可以以集群为单位把 ES 部署在各个机房中来实现异地多活。
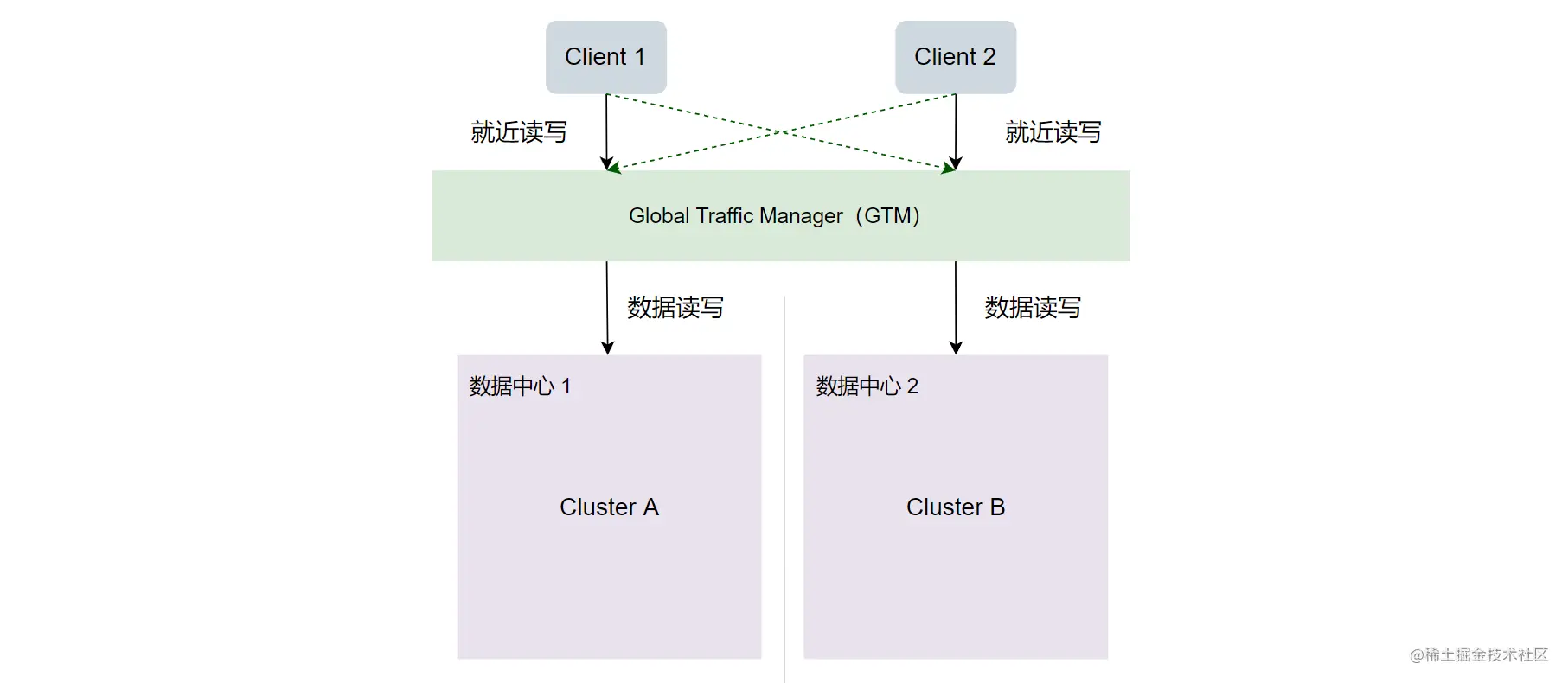
如上架构图,通过 GTM(全局流量管理)可以实现各个 Client 就近读取数据中心的数据,当就近的数据中心无法提供服务的时候,可以访问其他数据中心(绿色箭头)。那各个数据中心的集群如何保证数据一致性的呢?一般有以下几种方法:
- 在程序上实现数据双写,如果直接先写 Cluster A,再写 Cluster B 看起来是可以的,但这两个写操作不是原子性的,可以利用 MQ 等中间件来保证两个数据中心的数据写入的最终一致性。对于双写如何保证数据一致性的问题,这里不再展开。
- 利用官方 Cross Cluster Replication(CCR) 的方案,这里也不再展开,感兴趣的同学可以查看官方文档进行深入学习。
关于异地多活这个话题啊,我觉得同学们应该感兴趣的,后续有机会的话我们可以详细、深入地聊聊这个话题。当然大部分同学的业务应该还没到要做异地多活的程度。
二、集群容量规划
对集群做容量规划是要得出一个集群大概需要多少个节点、每种类型的节点多少个、索引需要设置多少个分片等。
在规划一个集群容量时需要考虑的因素主要有:
- 业务形式,到底是搜索类业务还是日志类业务,业务增长的趋势是如何的。
- 并发写入的吞吐量有多大、是否需要做数据预处理。
- 查询的形式,是否需要做复杂的聚合查询,查询的QPS、RPS是多少。
- 单条文档的大小、分片的副本数、文档总数(预估业务量)、数据保留多久(日志类),这几个因素跟分配存储大小息息相关。
上面提到过一般来说应用分为两种类型:日志类业务和搜索类业务,这两种类型的业务都有各自的特点:
- 日志类业务:数据增长快,但是这些数据是基于时序存储,可能一年后就不会再查询了。
- 搜索类业务:业务数据增长缓慢,但是数据可能一直都被查询,可能需要做一些复杂查询操作。
所以对于日志类的业务,如果查询并发量不高是可以考虑使用机械磁盘来节省成本的,而搜索类业务建议数据节点使用 SSD。对于这两种业务来说,单节点能承受的数据量也是不同的。下面是阿里云文档给出的建议:
- 日志类业务: 单节点磁盘最大容量 = 单节点内存大小(GB)* 50,即内存与磁盘的比例为 1 : 50。
- 搜索性能要求高的场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 10,即内存与磁盘的比例为 1 : 10。
- 正常情况:单节点磁盘最大容量 = 单节点内存大小(GB)* 30,即内存与磁盘的比例为 1 : 30。
一个集群的容量规划跟你的业务、资源数量相关性很大,所以容量规划需要因地制宜,而上面这些都只是经验总结,尽量往这个靠即可。
三、设计和管理分片
我们知道 ES 的分片分为主分片和副本分片,那对于索引分片的分配下面将分为主分片和副本分片两种情况来讨论。虽然下面提供了一些分片设计的规则和建议,而且都是比较官方或者大厂实践出来的,但是实际该如何操作,应以你的应用场景为出发点进行设计和分配。
1. 主分片的设计和分配
当一个索引只分配一个主分片的时候,可以避免出现之前提到过的分布式算分偏差的问题、聚合结果不准确的问题。但是一个索引一个分片就把 ES 分布式的特性浪费掉了,因为即使增加再多的数据节点,这个索引也是无法进行水平扩展的。随着这个索引数据量的增加,其将无法满足业务的并发读写需求。
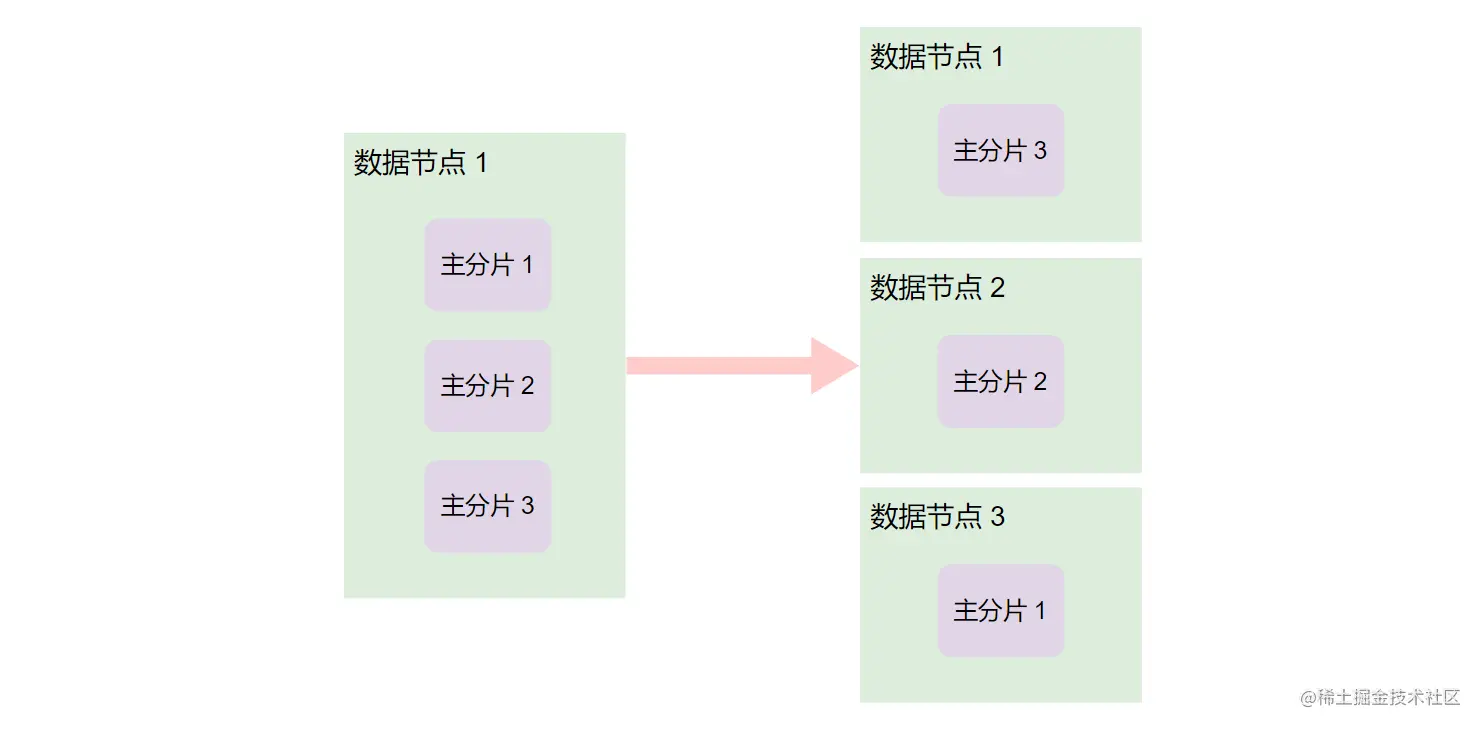
如上图,当一个索引的主分片数量比数据节点数量多的时候,如果加入新的数据节点,系统会自动将这些分片分配到其他机器上,以达到一个分片平衡的状态。
我们知道一个索引的多个主分片可以负载更多的读写请求,但并不是越多的主分片就越好。因为一个主分片就是一个 Lucene 索引,它是会消耗系统资源的。并且过多的主分片会使得 Master 管理的数据增多,增加其负担。
那该如何设置索引的主分片数量和每个主分片的容量呢?我从阿里云提供的文档和 ES 官方文档 中总结了以下几点:
- 每个分片最好 在 10G 到 50G 之间。日志类的应用最好不要超过 50 G。
- 阿里云的文档建议一个分片的存储量保持在 30 GB 以内最优。
- 阿里云的文档建议分片的个数(包括副本)要尽可能等于数据节点数,或者是数据节点数的整数倍。
- 阿里云的文档建议单个节点上同一索引的分片个数不要超 5 个。
- 每个节点可以可以维护的分片数量是有限的,官方给出的值是每 GB 内存最多维护 20 个分片。
控制分片的大小其实有很多好处的,例如可以加快分片在集群内迁移的速度、同样也可以加快灾难恢复的速度、进行 Merge 时可以减少占用的资源、分片过小会导致集群分片数量增多等等。
所以当我们设计一个索引分片的时候,应当预估业务可能产生的数据量,增长量等,然后再根据预估量和上述的规则设计索引的分片。
2. 副本分片的设计和分配
副本的存在可以分担部分读负载、提高系统的可用性和数据可靠性,但其同样要消耗资源。副本分片的设计除了使用上述主分片的规则外,每个分片的副本(主副本 + 从副本)数量不能超过数据节点的数量。
从副本的数量要根据业务形式和并发量来做决定,例如这个索引的业务是不是要经常跑聚合操作?还是写多读少?从副本的一个特点是可以实时增减,所以当你发现一丝不对劲的蛛丝马迹时可以及时调整。
四、重要的配置
下面来看看线上系统需要配置的重要配置项。主要有 JVM 和 Linux 参数、网络配置、硬件选择。
1. JVM 配置项
JVM 的配置在 config / jvm.options 文件中,在 JVM 配置上我们主要把目光集中在 Xms 和 Xmx 这两个参数上。我们使用 Xms 设置堆内存最小值 ,而使用 Xmx 设置堆内存最大值。
JVM 配置需要以下几点:
- Xms 和 Xmx 的值必须一样。这样启动时就分配好内存空间,避免运行时申请分配内存造成系统抖动。
- Xmx 不要超过机器内存的 50%,留下些内存供 JVM 堆外内存和操作系统使用。
- 并且 Xmx 不要超过 32G。建议最大配置为 30G。接近 32G,JVM 会启用压缩对象指针的功能,导致性能下降。具体可以参考:a-heap-of-trouble
在生产环境 JVM 需要使用 Server 模式,另外你需要监测集群节点实例的 GC 情况来选择合适的垃圾收集器。
2. Linux 系统设置项
禁用操作系统的 swapping
很多的操作系统在物理内存不够用时,会将部分物理空间的数据交换到 swap 空间(磁盘)上,使得系统不会因为内存不够用而产生异常的情况。如果 JVM 的内存被交换到磁盘上会造成性能下降,所以在 Linux 上部署的时候需要关闭 swapping。
下面指令临时关闭 swapping:
sudo swapoff -a
另外可以在 /etc/security/limits.conf 中设置 vm.swappiness=1。更多关于 swapping 的设置可以参考官方文档。要注意的是,更改了 /etc/security/limits.conf 配置后需要退出当前用户,在控制台重新登录即可生效。
增加文件描述符
ES 运行的时候需要使用非常多的文件,所以要调大文件描述符数量的值。
使用下面指令设置文件描述符的数量:
sudo ulimit -n 65535
或者可以在 /etc/security/limits.conf 中设置 nofile 的值为 65535。更多关于文件描述符的配置可以参考官方文档。
设置 mmap counts ES 使用了 mmapfs 来存储索引,但是默认的 mmap counts 的数量实在太少了,这样可能会造成 OOM 异常。
使用下面指令设置 mmap counts:
sudo sysctl -w vm.max_map_count=262144
或者在 /etc/sysctl.conf 中设置 vm.max_map_count 的值为 262144,设置完成后需要执行 sysctl -p 刷新。
设置最少的线程数量 ES 运行时会创建多种线程池来执行各种各样的操作,所以必须保证 ES 可以创建新的线程,而这个数量最少为 4096。可以使用下面指令设置线程数量:
sudo ulimit -u 4096
同样,也可以在 /etc/security/limits.conf 中设置 nproc 的值为 4096。
TCP 重传超时 ES 各个节点间的通信是使用 TCP 协议的,但是在丢包的情况下很多 Linux 系统默认最多重传 15 次,而这会 15 次重传会耗时 900 秒以上。这意味着系统发现出现网络分区的情况需要非常长的时间。可以使用下面的指令来设置重传的次数:
sudo sysctl -w net.ipv4.tcp_retries2=5
同样你也可以在 /etc/security/limits.conf 中设置 net.ipv4.tcp_retries2 的值,并且执行 sysctl net.ipv4.tcp_retries2 进行刷新。
对于 Linux 下的环境配置更多的信息可以参考官方文档。
3. 网络设置
对于 ES 的网络配置,如果可以提供多块网卡的话,最好将 http 和 transport 绑定到不同的网卡,并且设置对应的防火墙规则。如果 http 接口需要提供外网访问的话,需要配置 https 和安全认证方式。
在上面架构的内容中我们也讨论过了,单个集群的节点不要跨机房部署,节点间的网络环境越快越好。
4. 硬件选择
对于硬件配置,如内存、磁盘,上面的内容已经说得比较清楚了,这里不再赘述。需要注意的是,不要使用硬件配置超高的机器来部署集群的多个节点,因为一旦这台机器网络出问题或者宕机,可能会导致集群不可用。也就是说不要在一台机器上部署多个节点!
五、集群监控
集群上线后我们需要对其进行监控,以免出现问题了我们还不知道。我们可以通过采集 ES 集群的指标然后存储在 ES 中,通过 Kibana 提供的可视化功能实时监测各个节点的运行状态。其实 cerebro 也提供了不错的监控功能,但今天我们来简单看看 ES 官方提供的监控方式。
ES官方提供的监控方式有两种:基于组件自身监控和使用 Metricbeat 监控,下面分别看看它们是如何工作的。
基于组件自身监控 基于组件自身监控的方式不需要安装额外的组件,所以其有快捷简单的优点,但是采集指标的时候会占用组件自身的资源。
默认的情况下,ES 集群监控采集数据的功能是关闭的,需要使用下面指令打开:
PUT _cluster/settings{"persistent": {"xpack.monitoring.collection.enabled": true}}
你也可以在 Kibana 中打开这个配置(Management => Stack Monitoring):
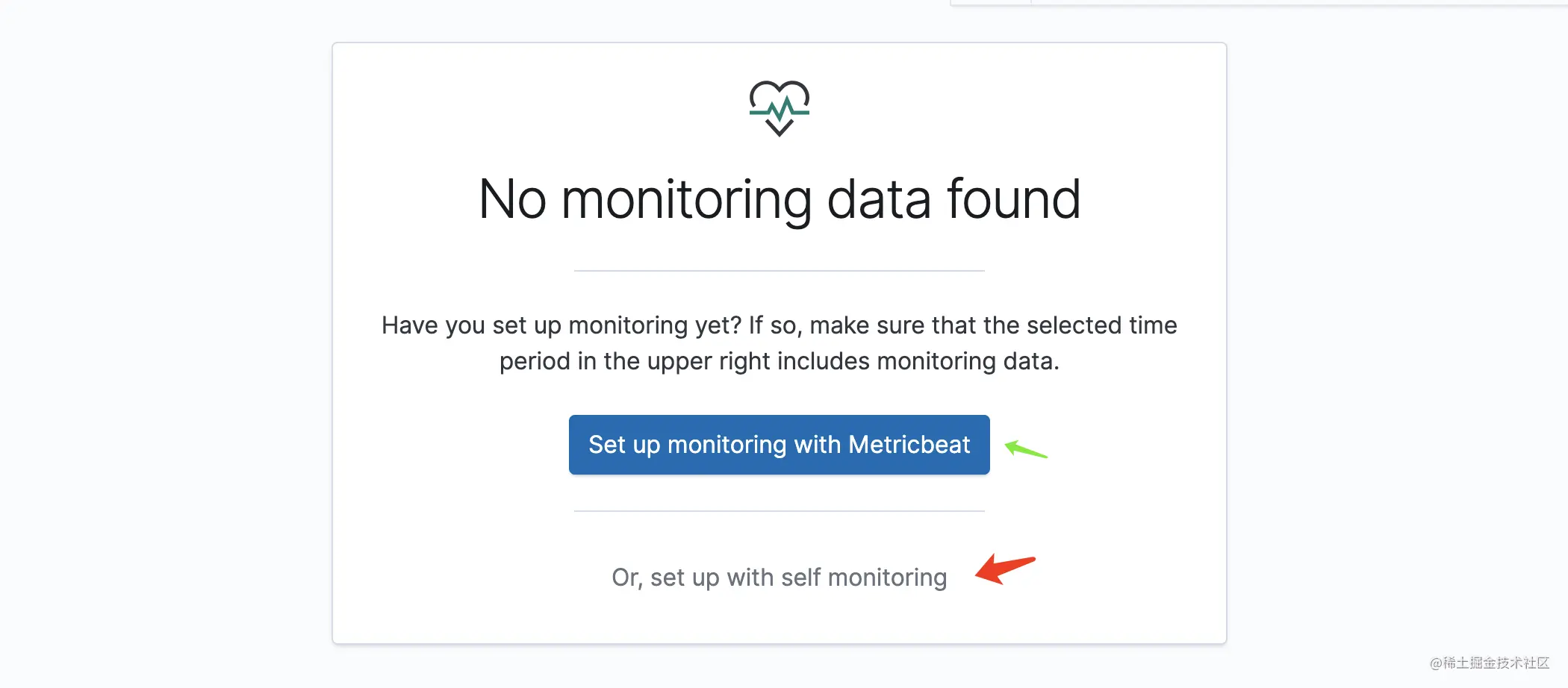
点击红色按钮开启基于组件自身监控的功能,而绿色箭头的是开启基于 Metricbeat 监控的功能。
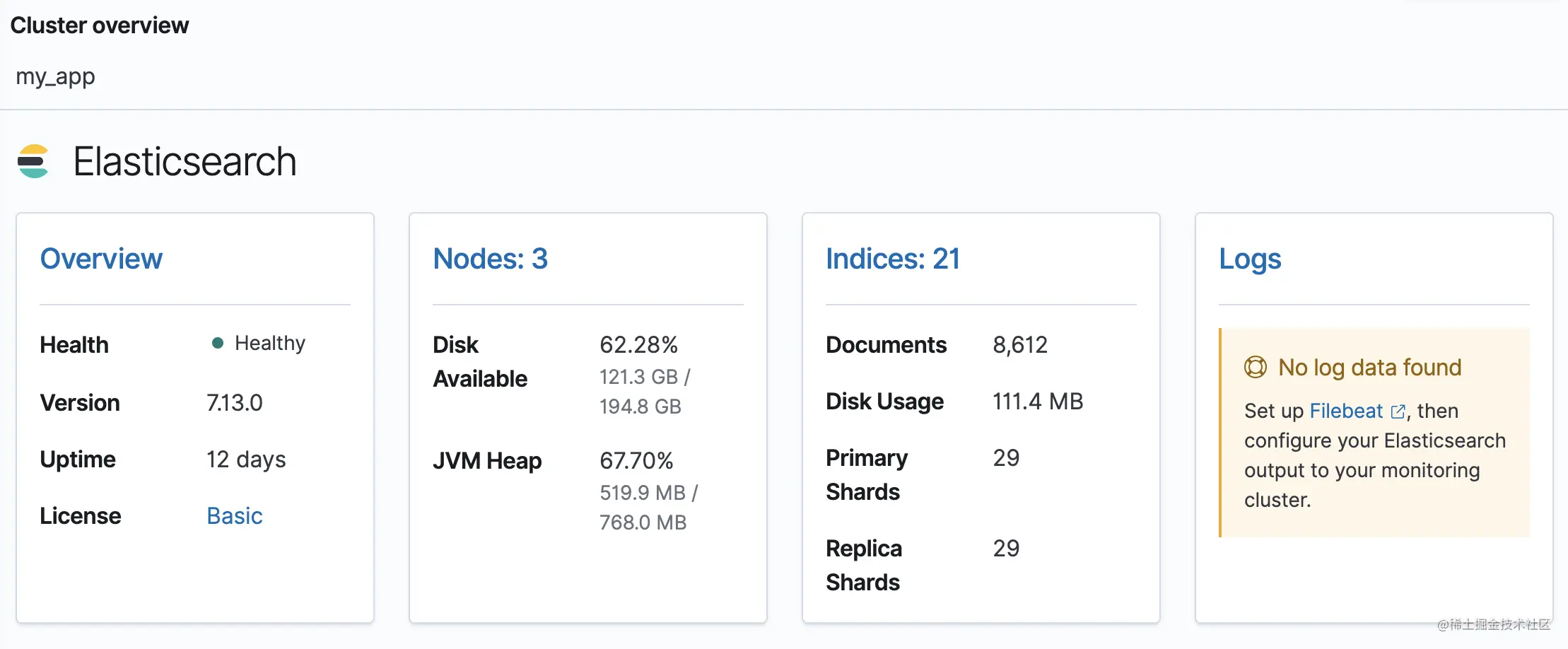
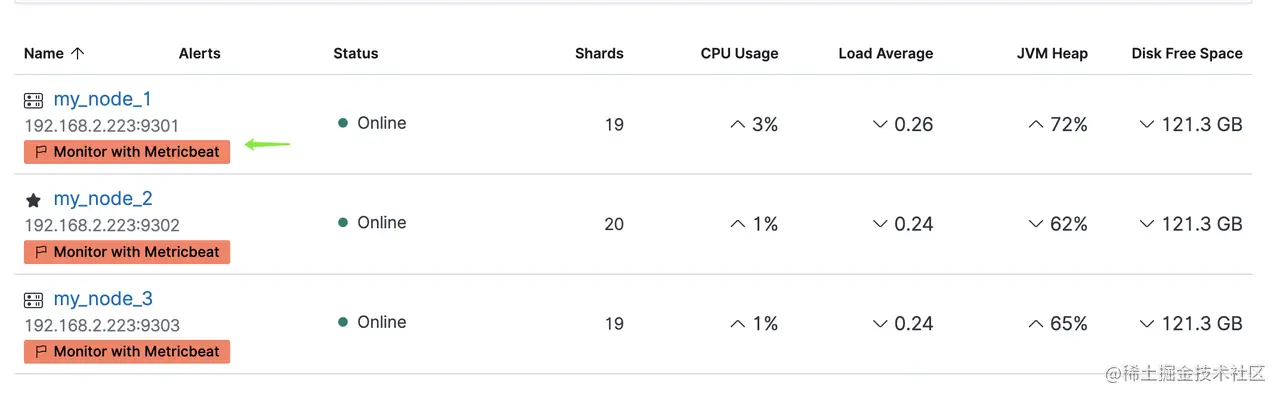
如上图,你可以点击 Overview 和 Nodes 等查看对应的详情。
使用 Metricbeat 监控
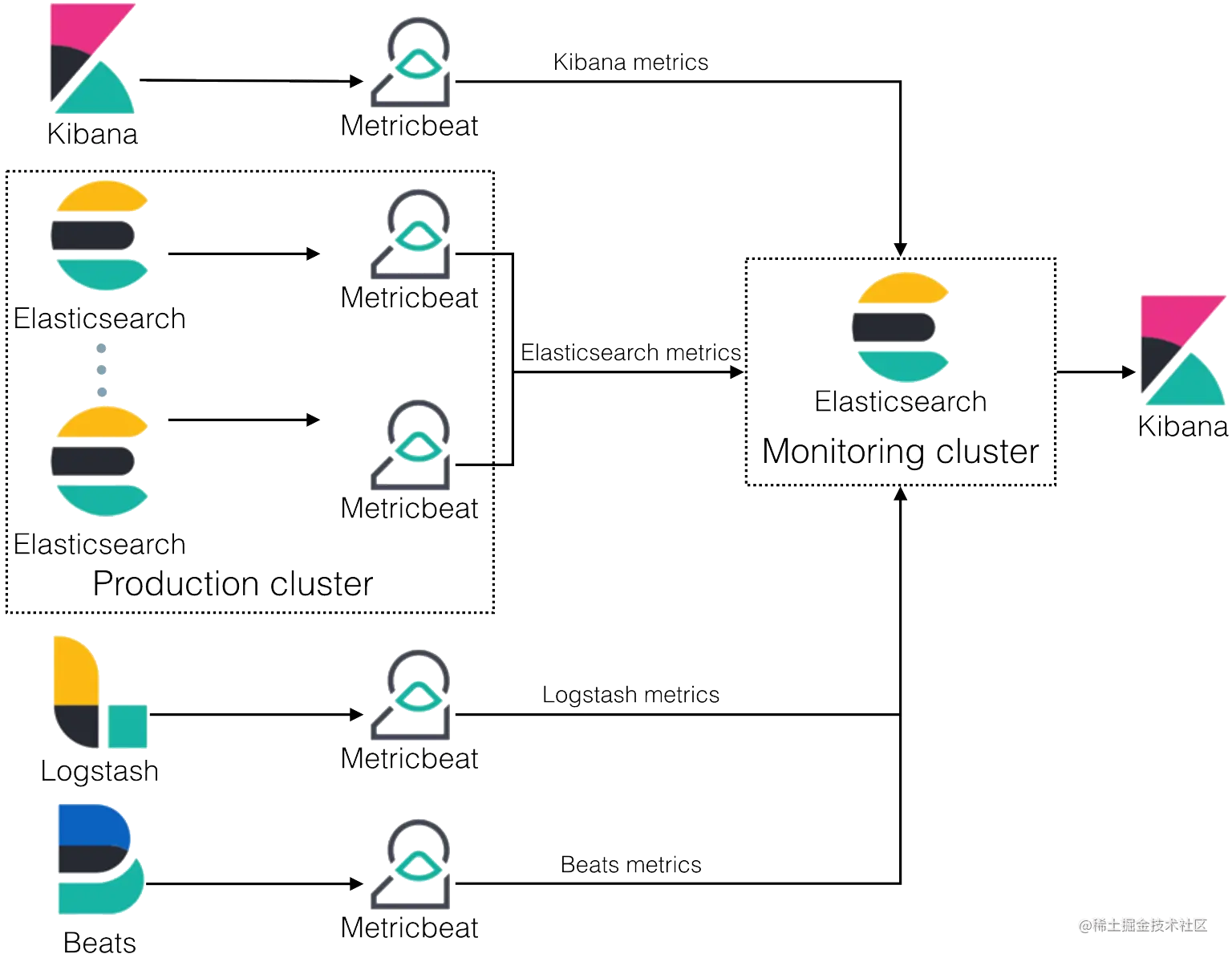
如上图是使用 Metricbeat 采集 Elastic Stack 监控指标的架构图,可以看出我们需要部署一套单独的集群来存储这些采集到的指标数据。分离出监控集群的好处是可以避免因生产集群出现故障而无法访问监控数据,并且还可以防止监控活动影响生产群集的性能。
需要注意的是,在 ES 6.5 版本以上才可以使用 Metricbeat 采集 Elasticsearch 监控指标。至于如何安装和使用 Metricbeat, 你可以根据官方文档进行设置。
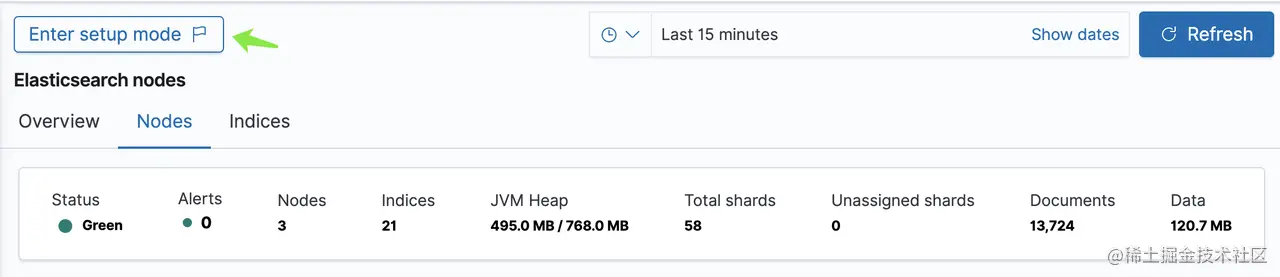
如上图,点击绿色箭头处,进行模式监控切换,出现如下图:
点击绿色箭头处,会出现详细的安装和配置文档。由于篇幅的限制这里就不给出详细的配置教程啦,有需要的同学可以在群里@我。
除了官方的监控方式外,还有其他的监控方式,感兴趣的同学可以参考一下:
- Elasticsearch-HQ
- elasticsearch-exporter + prometheus + grafana,这个方案依赖的组件比较多,我个人觉得是比较重的。
- cerebro github.com/lmenezes/ce…
当然如果上述的方案都无法满足你的需求,你可以根据 ES 提供的接口研发自己的监控工具。
六、总结
今天为你介绍了集群运维中很基础但又很重要的知识点。
当我们进行线上集群部署的时候,应该采取每个节点单一角色的方式来部署。每个节点职责分离我们可以动态增减某种类型的节点来适应业务变更。
线上的部署架构我们介绍了3 种常见的部署方式:
- 基本架构,在协调节点前加一个 LB 实现请求的负载均衡。
- 读写分离架构,基于基本架构衍生出来的架构,将读写请求分别负载到读写 LB 处理。
- 跨机房部署机构,GTM 分发流量,使客户端实现就近读取数据。多个数据中心的集群互备。
在做集群容量规划、分片设计的时候需要考虑的因素比较多,需要根据业务情况、形式、资源等情况来考虑。本文提到的都是些经验规则,更多的是需要你因地制宜地进行规划。
一些重要的系统配置在线上环境一定要去配置,否则会导致系统节点无法启动。
对于集群监控,其方式有很多,如果资源允许的话尽量单独使用一个监控集群来做监控的业务。
