今天我们来跟踪 ES 文档的写入流程,需要说明的是,今天的内容只包含 ES 的内部流程,不涉及 Lucene 处理文档写入时的相关内容。
在跟踪写入模块的源码前,你需要认真阅读 《4 | 管理你的数据:文档的基础操作》、《20 | 数据持久化:分布式文档的存储流程》、《23 | 数据不丢失的奥秘(上):副本策略》、《24 | 数据不丢失的奥秘(下):ES 的数据副本模型》、《31 | 源码阅读:Get 与 Multi Get》这几篇文章。
在阅读写入流程的源码前,我们还是先来明确以下几个事情:
1. 文档写入操作的定义
文档写入的操作有以下几种定义,其实现类为 org.elasticsearch.action.DocWriteRequest.OpType 枚举类:
enum OpType {/*** Index the source. If there an existing document with the id, it will* be replaced.*/INDEX(0),/*** Creates the resource. Simply adds it to the index, if there is an existing* document with the id, then it won't be removed.*/CREATE(1),/** Updates a document */UPDATE(2),/** Deletes a document */DELETE(3);}
- INDEX,索引一个文档,如果文档存在替换它。
- CREATE,创建文档,put 请求时通过 op_type 参数指定类型为 create 即可。如果文档已经存在,请求会失败。
- UPDATE,更新文档。
- DELETE,删除文档。
2. 文档写入操作 API
在 ES 中,单个文档写入可以使用 Index API,而批量的文档写入需要使用 Bulk API。index API 和 Bulk API 可选参数有很多,下面介绍几个与今天内容相关参数:
- wait_for_active_shards,其可选值为 all 或者 正整数,当指定数量的分片副本(包括主分片)可用时才会执行写入操作。默认值为 1,即只要主分片可用就可写入。
- refresh,可选值为 true、false、wait_for。如果设置 wait_for,将等待一次 refresh 时写入的数据可见。
- pipeline,指定已经创建好的 pipeline 的名称。
3. 文档写入的基本流程
单个文档的写入流程我们在 《20 | 数据持久化:分布式文档的存储流程》中以有过介绍,下面我们来简单回顾一下: 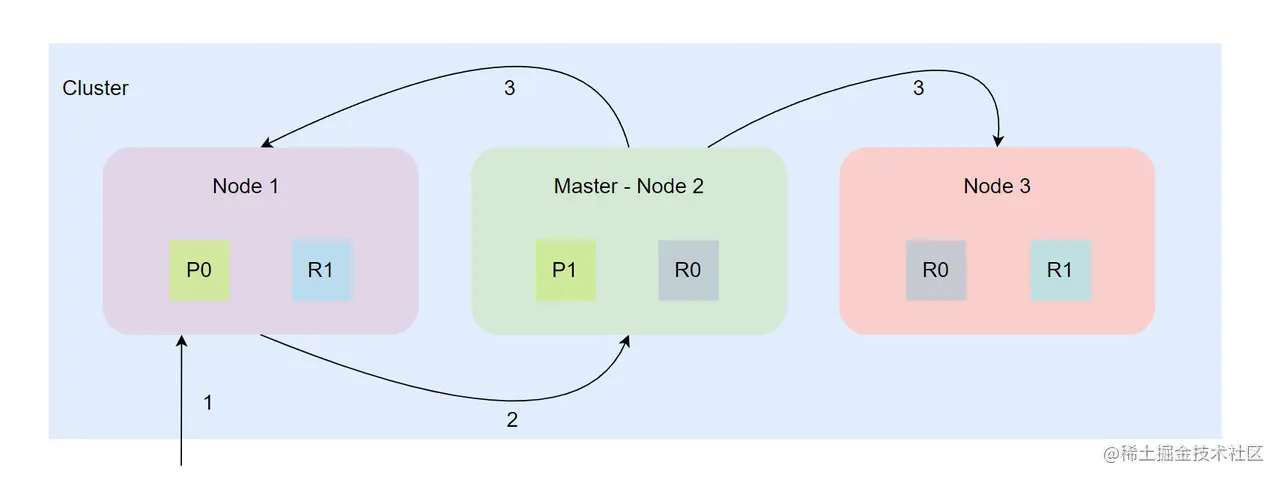
如上图,单个文档的写入流程如下:
- 客户端请求到达协调节点 Node 1。
- 协调节点获取可以处理文档的主分片节点 Node 2,并且转发请求到 Node 2,Node 2 索引文档数据到对应主分片中。
- 主分片写入成功后,Node 2 将请求并行转发到 Node 1 和 Node 3 节点上,进行副本分片的数据索引操作。Node 2 等待各个副本分片写入成功返回后,返回结果给协调节点,协调节点向客户端返回操作结果。
Ok,今天我们目标主要是在代码层面找到以下几个问题的答案:
- wait_for_active_shard 的作用到底是啥?
- ES 写入操作是只需要写入主副本成功就可以返回了,还是需要等到全部副本处理成功才能返回?,或者只需要部分处理成功即可返回?
- 副本写入成功的标准啥?
- Index API 是共用了 Bulk API 的流程吗?
由于在 《31 | 源码阅读:Get 与 Multi Get》已经非常详细地介绍了 REST 请求的处理流程,今天这部分内容就不再赘述了。与 Get 请求的源码跟踪一样,本章也分为协调节点上的流程和数据节点上的流程两部分进行分析,只不过数据节点上的流程在这里分为两部分:主分片节点的处理流程和副分片节点的处理流程。
Ok,下面我们直入主题!
一、代表 Index API 和 Bulk API 的 REST 类
代表 Index API 的 REST 类为 org.elasticsearch.rest.action.document.RestIndexAction 类, 而代表 Bulk API 的 REST 类为 org.elasticsearch.rest.action.document.RestBulkAction 类。在它们的 prepareRequest 方法中都有对参数解析的实现,这里就不展示了。
真正处理 Index 请求和 Bulk 请求的类分别为 org.elasticsearch.action.index.TransportIndexAction 类 和 org.elasticsearch.action.bulk.TransportBulkAction 类。但是通过源码的注释可以发现, TransportIndexAction 类其实是被丢弃的了:
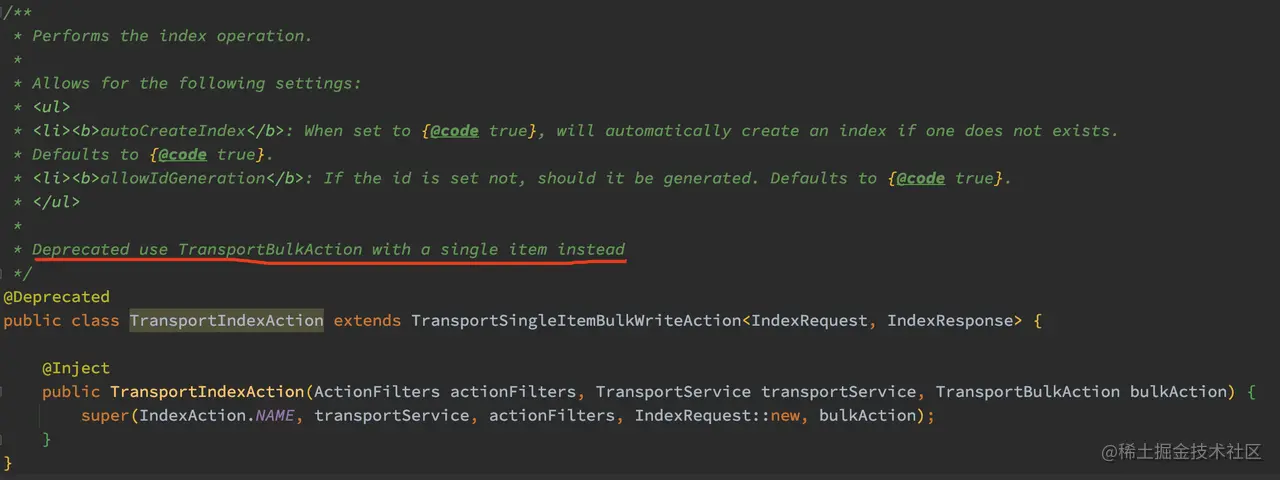
如上代码,TransportIndexAction 其实继承了 TransportSingleItemBulkWriteAction,而 TransportSingleItemBulkWriteAction 中有个成员 bulkAction,其类型为 TransportBulkAction,所以真正处理 Index 请求的其实是 TransportBulkAction 类。
虽然 TransportIndexAction 被丢弃了,但是在 org.elasticsearch.action.ActionModule 处还是注册了这个 Action,所以收到的 Index 请求会转到 TransportIndexAction,最后在 TransportSingleItemBulkWriteAction 中包装为 BulkRequest,然后由 TransportBulkAction 进行处理。
所以,Index API 是共用了 Bulk API 的实现流程的! 既然这样,今天后续的内容就以 Bulk API 的实现流程来做分析啦~
二、协调节点上的流程
Bulk API 处理流程的主要入口在 TransportBulkAction.doExecute 方法中,其最终调用了 TransportBulkAction.doInternalExecute 方法,此方法比较长,我们分多个部分来看。
1、pipeline 预处理
TransportBulkAction.doInternalExecute 方法的第一件事是判断是否有请求项需要执行 pipeline,所以在看代码前我们先来简单介绍一下 pipeline。 更多关于 Ingest pipelines 的使用例子,请参考官方文档。
Ingest pipelines 可让你在索引之前对数据执行常见的转换操作。pipeline 由多个定义的 processors 组成,这些 processor 将会按定义的顺序执行 ,下面是一个简单的 pipeline 例子(官方例子的一部分截取):
PUT _ingest/pipeline/my-pipeline{"description": "My optional pipeline description","processors": [{"set": {"description": "My optional processor description","field": "my-long-field","value": 10}}]}
如上示例,my-pipeline 为用户自定义的 pipeline 名字,在 processors 中定义对应的处理器(processor),但此处只有 set 这一个 processor。
如果在 Bulk API 中指定了 pipeline 参数,系统会处理对应的 pipeline 逻辑。协调节点会找到可以处理 pipeline 的数据预处理节点(Ingest Node)然后将请求转发出去。当需要进行预处理的请求处理完毕后,再继续执行 Bulk 的后续写入逻辑。
简单介绍完 pipeline,下面我们继续来跟踪 TransportBulkAction.doInternalExecute 的源码:
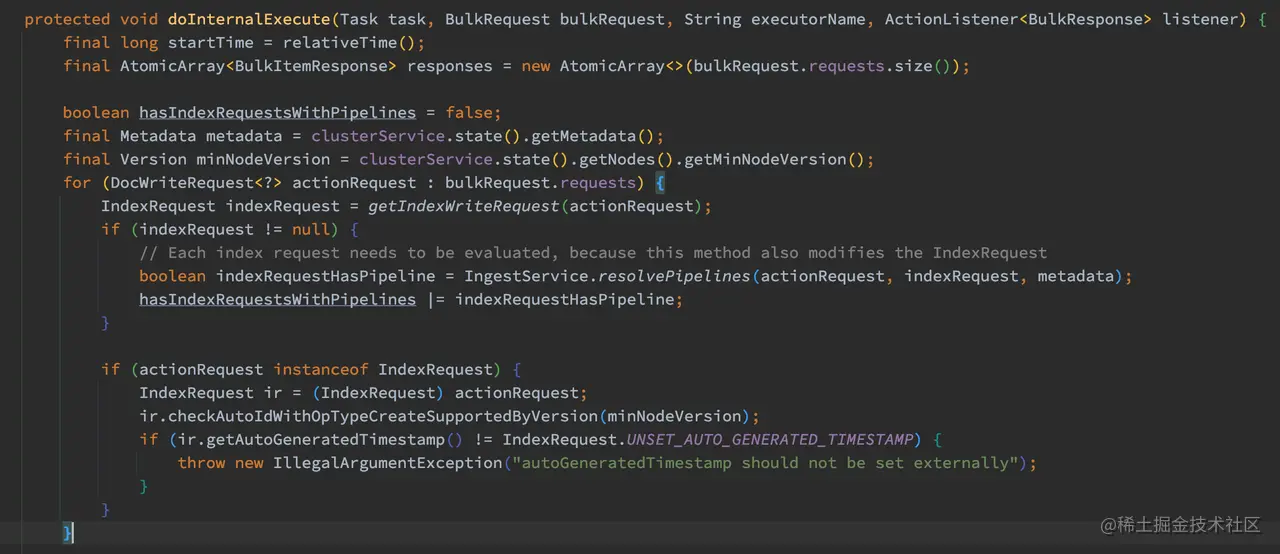
如上代码,首先获取集群的元数据和节点对应的最老的 NodeVersion。遍历所有的请求项判断是否有请求需要执行 pipeline 预处理。
经过计算,如果有需要进行 pipeline 的请求项则执行以下逻辑:
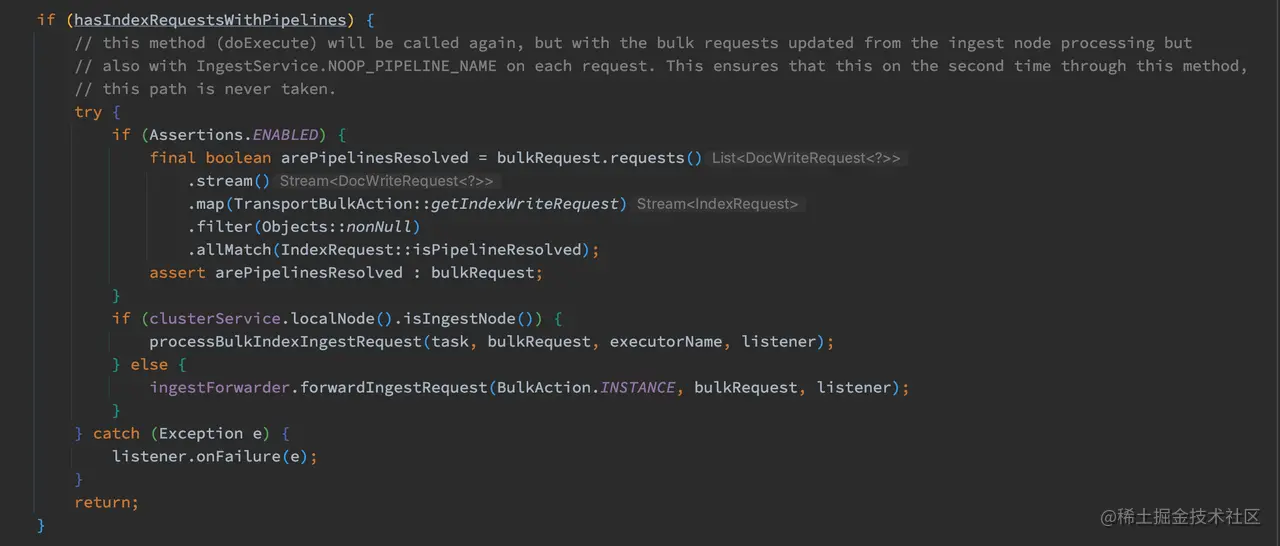
如上代码,如果本节点是 Ingest Node,这将 pipeline 请求项留着本地处理,否则调用 ingestForwarder.forwardIngestRequest 转发 pipeline 请求。
需要注意的是,从这段代码的注释中可以看到,当 pipeline 执行完后将会再次回到 doExecute 方法再次执行,而此段代码的逻辑只会执行一次。所以你会看到这里最后是直接 return 的。
2、自动创建不存在的索引
在开始进行 Bulk 操作前,系统需要创建所有不存在的索引:
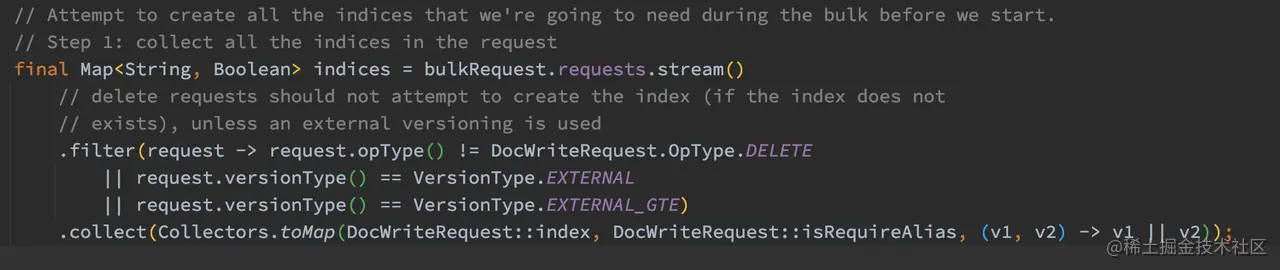
如上代码,过滤出所有索引的名字。这里 opType 参数我们前面已经介绍过了,有 INDEX、CREATE、UPDATE、DELETE 这四种。需要注意的是,DELETE 的请求如果其索引不存在,不应该为其创建索引,除非 external versioning 正在使用。
获取了所有索引名字后,需要过滤出不存在的索引: 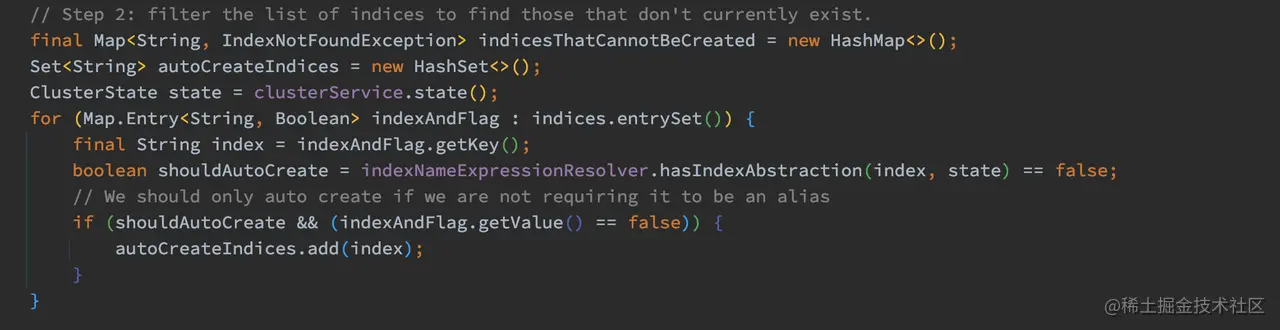 如上代码,在集群元数据中,逐个判断当前索引是否存在,这些不存在的索引存储在 autoCreateIndices 中。
如上代码,在集群元数据中,逐个判断当前索引是否存在,这些不存在的索引存储在 autoCreateIndices 中。
最后,如果不需要创建索引,则直接执行 executeBulk 方法,否则创建这些索引:
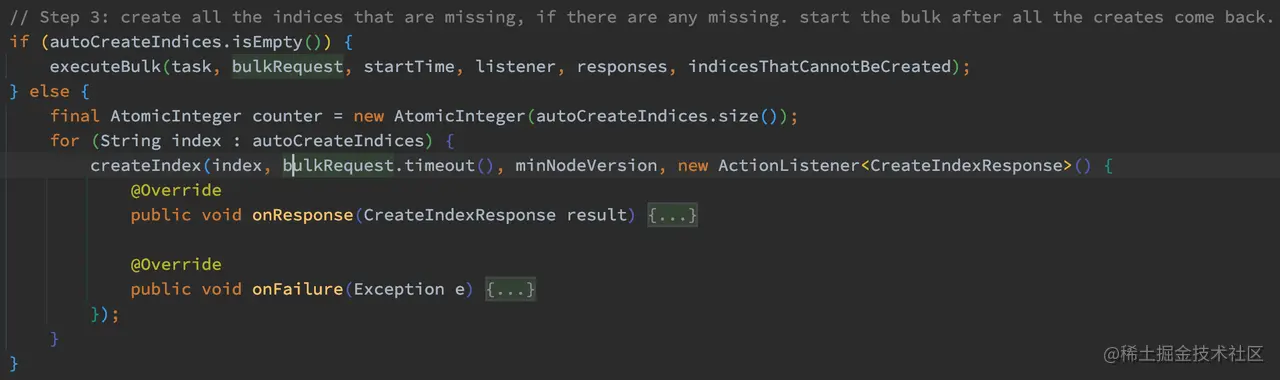
如上代码,如果 autoCreateIndices 不为空,则说明需要创建索引,此时遍历 autoCreateIndices,为各个不存在的索引调用 createIndex 方法进行创建索引。
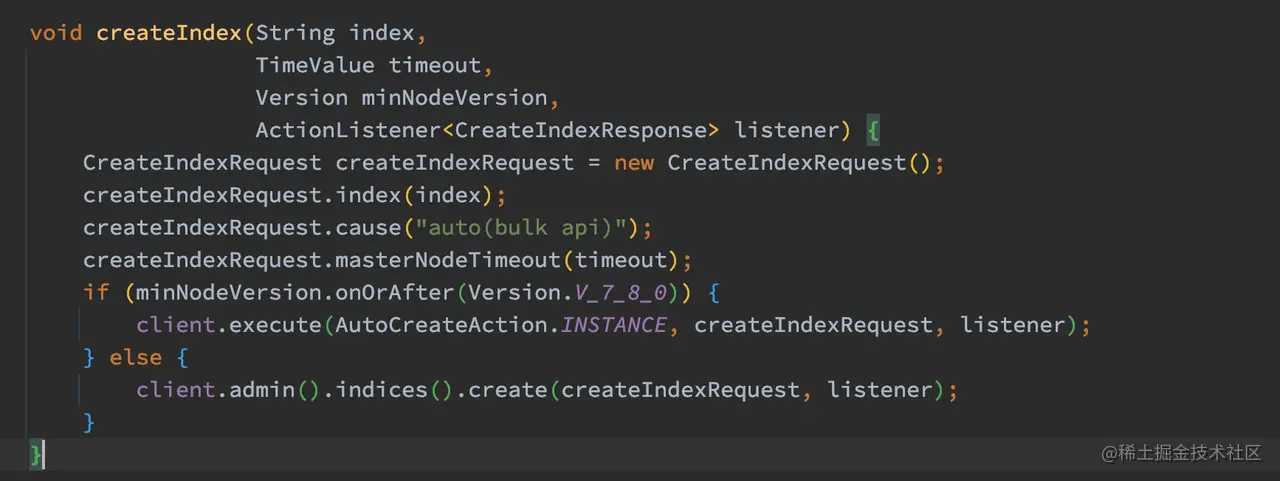
如上代码,创建索引的请求会转发到 Master 节点进行处理,协调节点会等到这些请求都返回后才会执行下一步操作。
那 Master 处理这个创建索引的请求什么时候才会返回结果呢?这里主要有两步,一个是执行完成创建索引的操作流程,另一个是完成新的集群状态发布工作。更多关于 Master 是如何处理创建索引的,你可以后续再进行跟踪,这里先不展开。
那如果创建索引失败,或者全部成功后在哪里处理呢?其实在 ActionListener < CreateIndexResponse > 的 onFailure 和 onResponse 中回调处理。下面先来看看 onResponse:
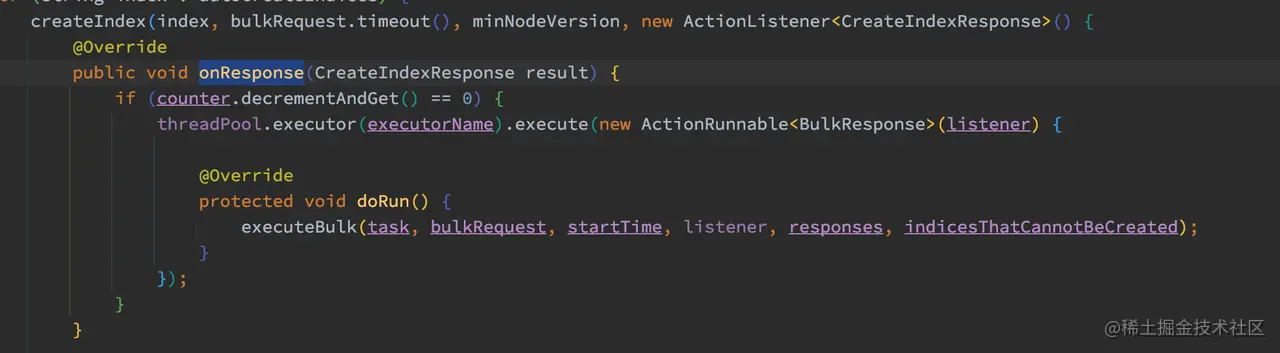
如上代码,onResponse 的流程非常简单,counter 自减后,如果数量等于 0 则执行 executeBulk 进行后续的 Bulk 流程。
onFailure 的流程也不复杂:
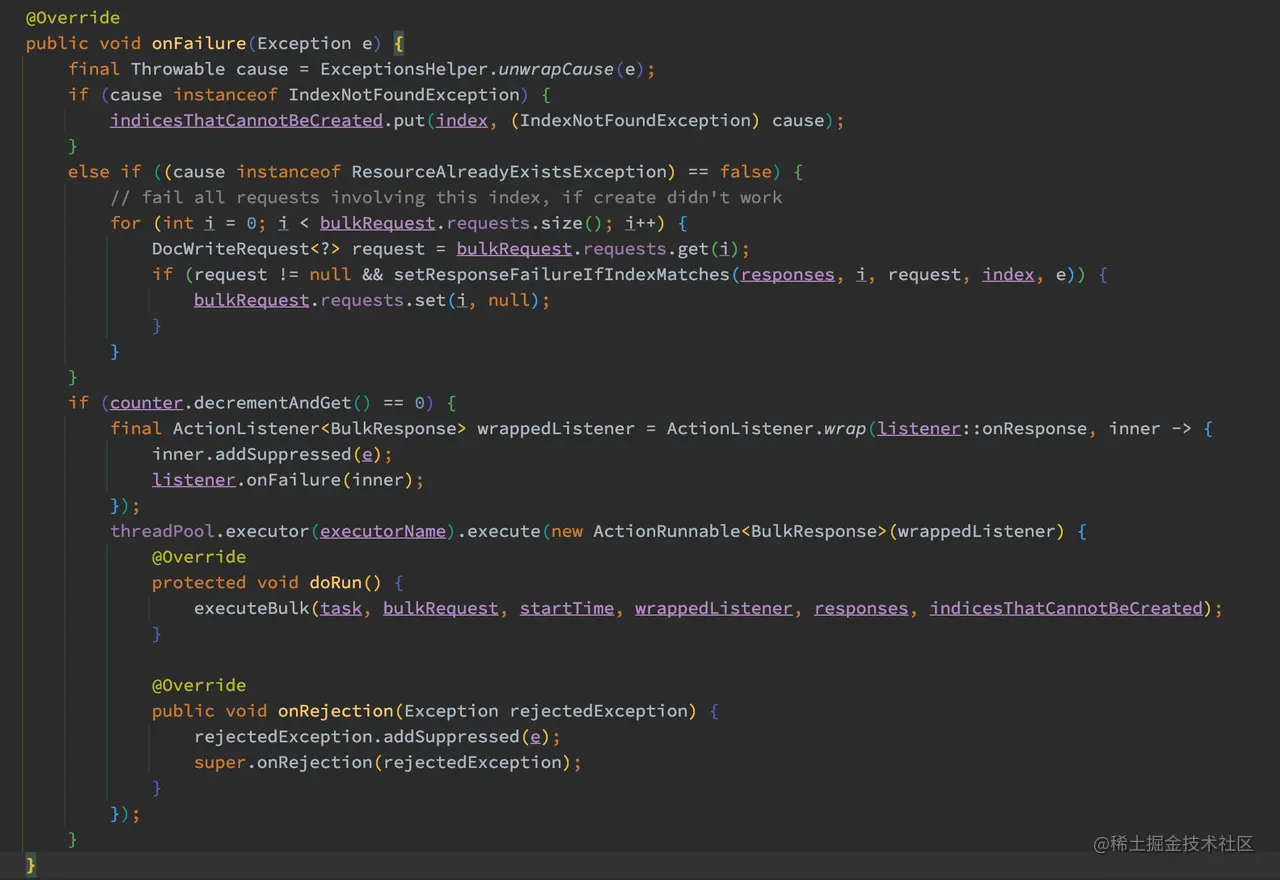
如上代码,如果发送异常,则对应的异常执行对应的业务逻辑,非 IndexNotFoundException 和 ResourceAlreadyExistsException 的情况下,会将对应的 request 项设置为 null。
最后 counter 自减后,如果数量等于 0 则执行 executeBulk 进行后续的 Bulk 流程。所以这里可以看出,某个 request 项失败的情况下是不会影响到其他 request 项的执行的。到此,TransportBulkAction.doInternalExecute 的流程已经看完,下面来看看 executeBulk 方法的流程。
3、协调节点转发请求
通过上述的源码跟踪可以得知,Bulk 操作后续的流程都进到了 executeBulk 方法中:

如上代码,executeBulk 中创建了 BulkOperation 实例,并且调用了其 run 的方法,最终 run 方法调用了 doRun 方法:
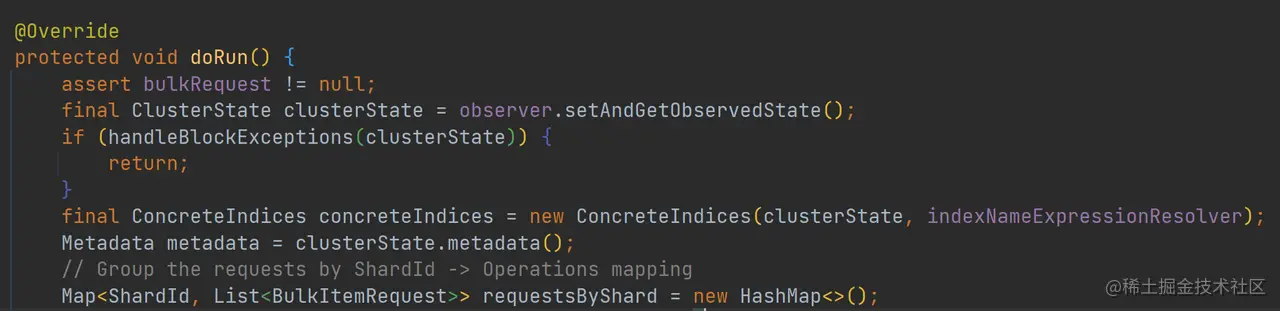
如上代码,首先判断集群是否处于阻塞状态,如果集群处于阻塞状态,将会不断重试直到超时。
如果集群没有处于阻塞状态,遍历每个请求项,以请求项的 ShardId 进行分组,结果存储到 requestsByShard 中:
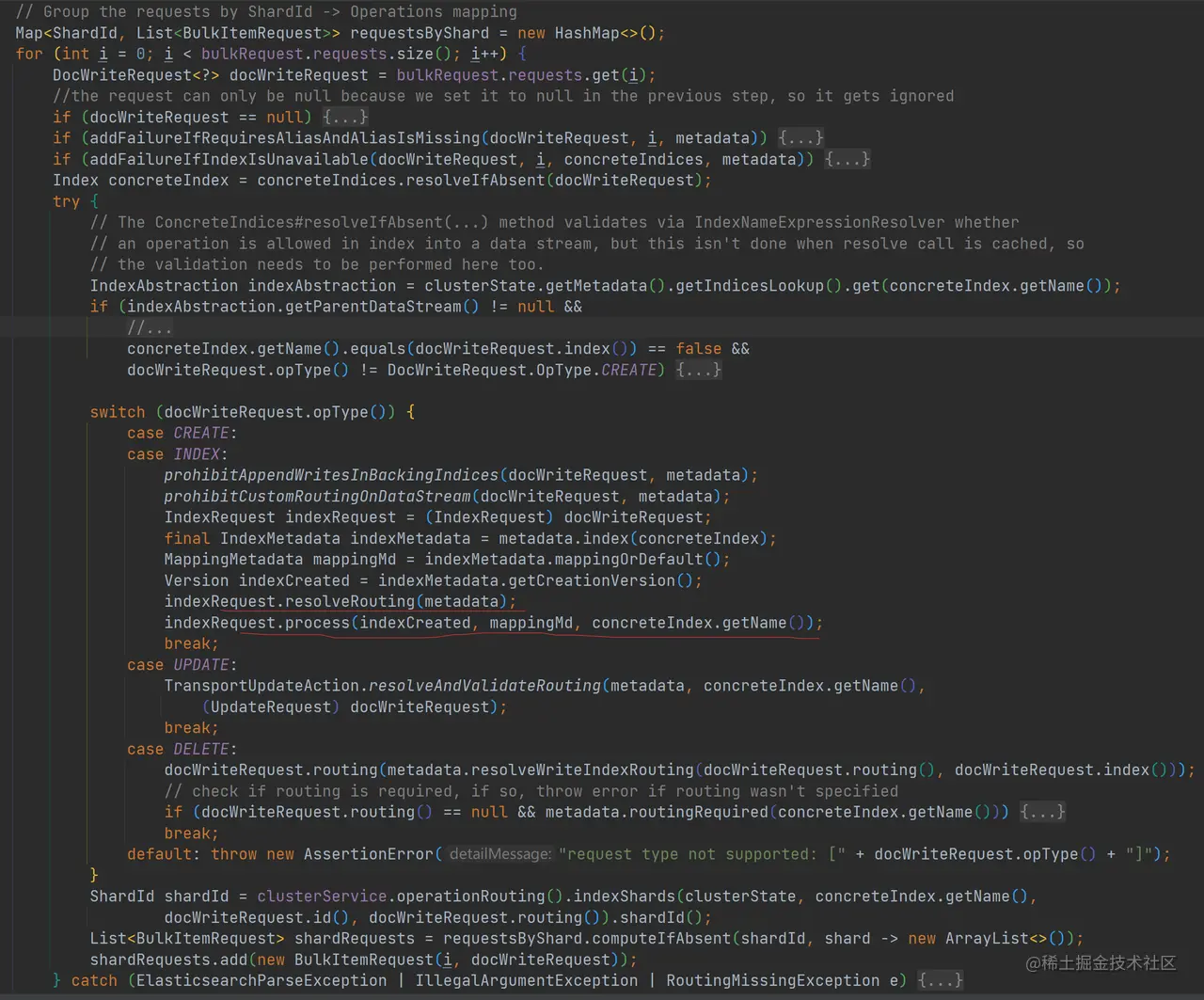
如上代码,对于写入请求,会调用 IndexRequest.resolveRouting 解析和生成路由信息,并且调用 IndexRequest.process 按需生成文档的 ID。对于每个请求项,会调用 OperationRouting.indexShards 生成 ShardId,这个操作我们在 上一章 《31 | 源码阅读:Get 与 Multi Get》已经介绍过了,这里不再赘述。最后以 ShardId 对所有请求项进行分组,并且保存到 requestsByShard 中。
有了分组后的请求项,下面就是包装这些请求并且转发到对应的 Shard 所在的节点上进行处理了:
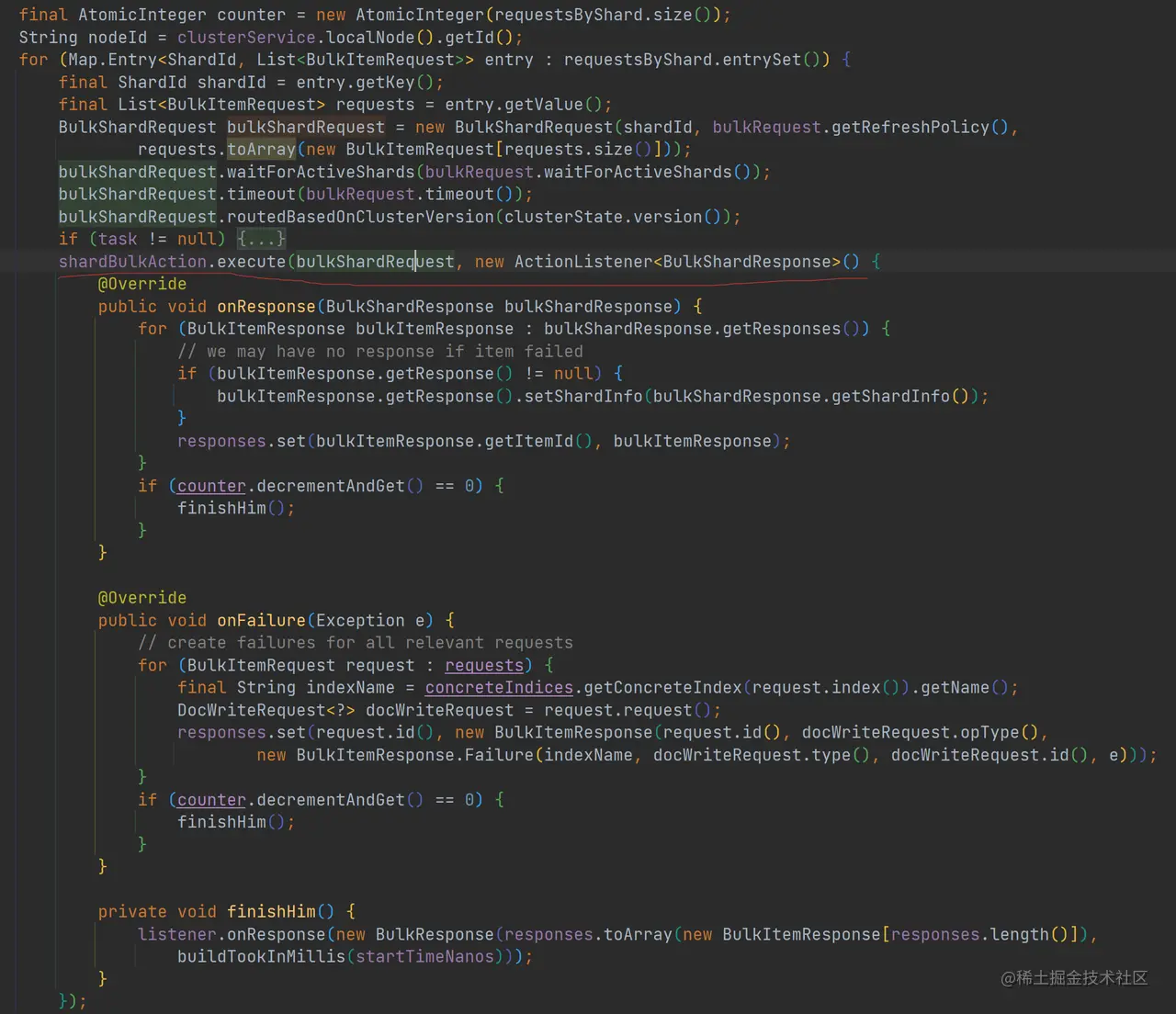
如上代码,每个 Shard 上的请求项列表被封装为 BulkShardRequest,并且调用 shardBulkAction.execute 进行处理。
shardBulkAction 其实是 TransportShardBulkAction 的一个实例,而 TransportShardBulkAction 继承了 TransportReplicationAction,所以 shardBulkAction.execute 最终调用了 TransportReplicationAction.doExecute 方法,而 TransportReplicationAction.doExecute 最终创建了 ReroutePhase 实例,并且调用其 run 方法:
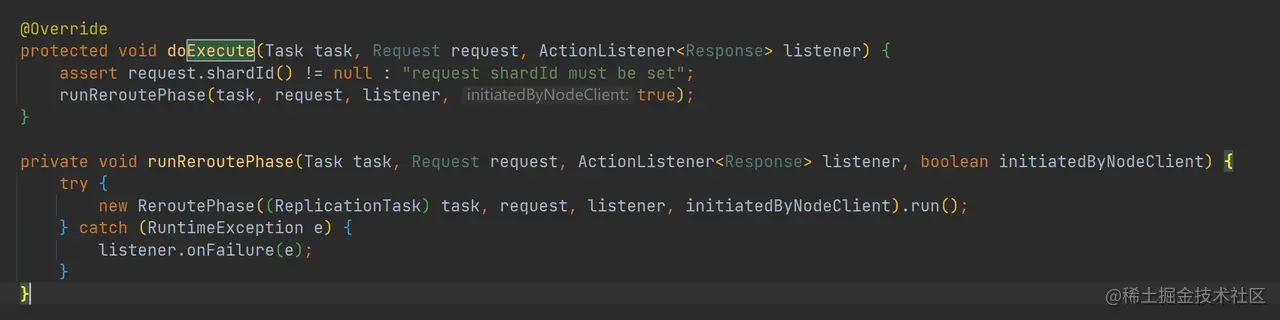
如上代码,ReroutePhase.run 最终调用 ReroutePhase.doRun 方法:
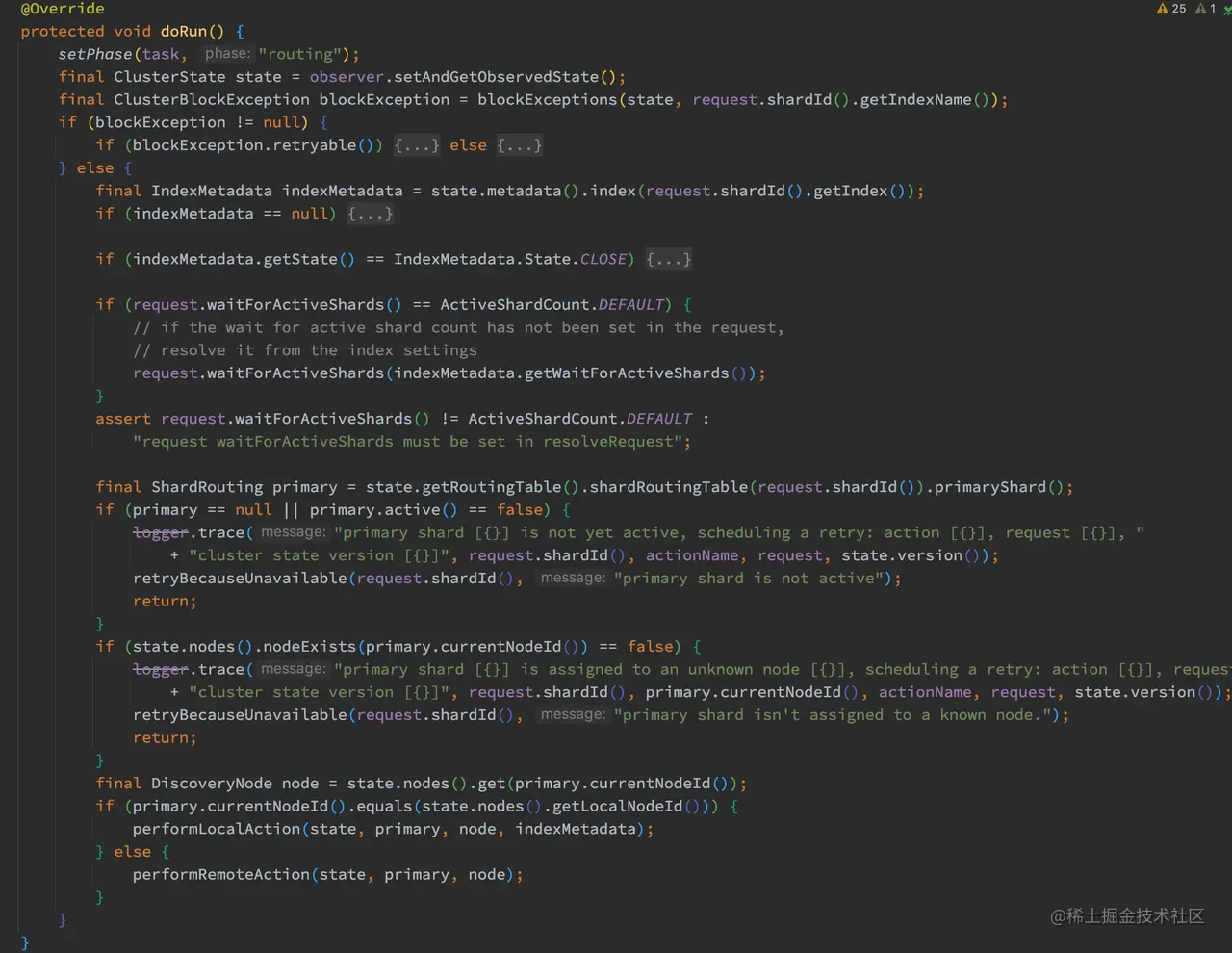 如上代码,ReroutePhase.doRun 主要处理了一下几项事情:
如上代码,ReroutePhase.doRun 主要处理了一下几项事情:
- 获取集群状态,并且判断集群是存在阻塞异常,如果存,则调用 retry 进行等待处理。
- 获取索引元数据,判断其状态是否已经关闭。
- 设置请求的 wait_for_active_shards 的数量。
- 通过 ClusterState 获取主分片的路由信息,然后根据主分片路由信息获取其所在的节点信息。
- 如果节点为本地,调用 performLocalAction 发送请求,否则调用 performRemoteAction 发送到远端。
通过对 performLocalAction 方法和 performRemoteAction 方法对比发现,如果主分片节点为本地,则设置任务的阶段为 “waiting_on_primary” 否则为 “rerouted”,最后这方法都调用了 performAction 方法处理请求:
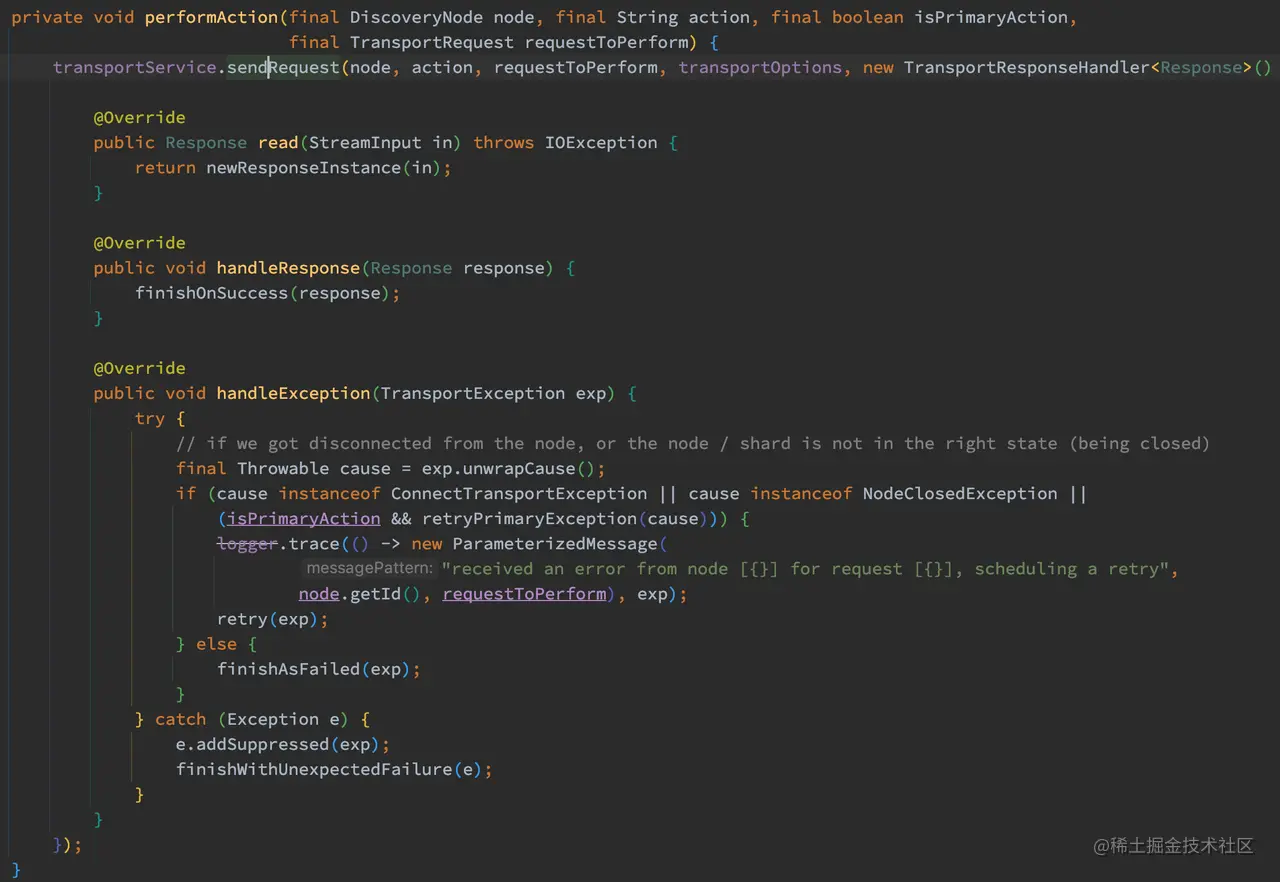
如上代码,performAction 方法最后调用了 transportService.sendRequest 进行转发请求,这方法我们在上一章已经研究过了,此处不在赘述。
当转发的请求发送异常的情况下,会回调 handleException 进行异常处理,当节点连接异常或者节点、主分片状态不正确时,执行 retry 操作:
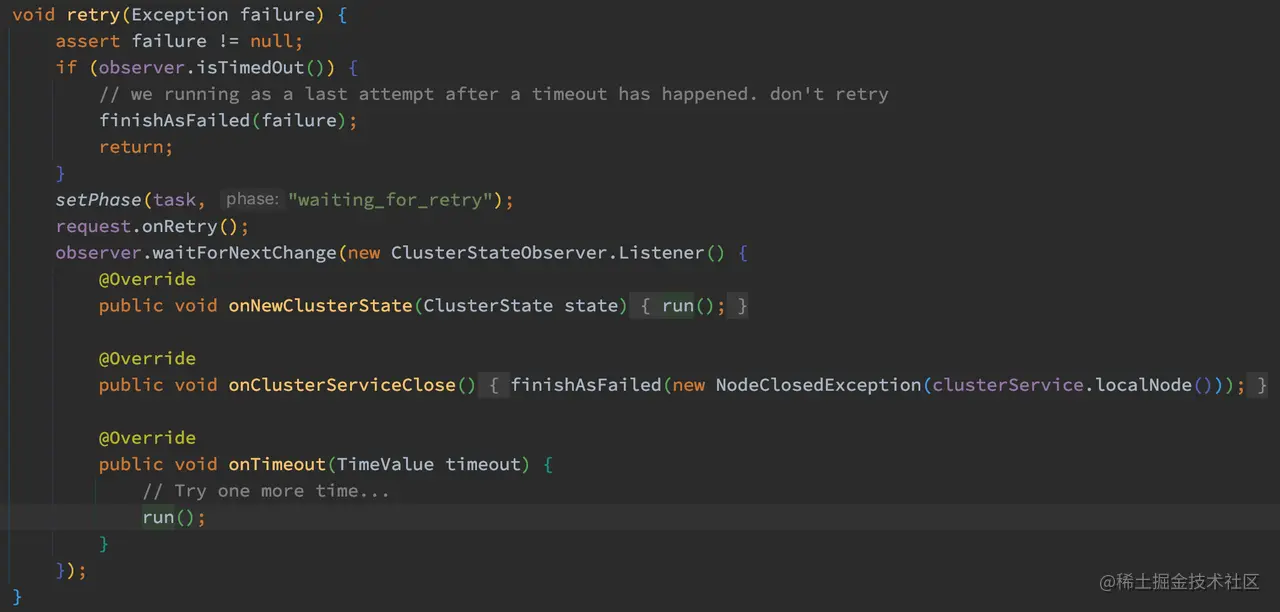
如上代码,重试的逻辑并不复杂,设置任务的阶段为 “waiting_for_retry”,在获取到最新的集群状态后重新执行 doRun 的逻辑。如果等待集群状态超时后,则会最后再重试一次 doRun 逻辑。
协调节点的处理流程比较长,这里简单总结一下协调节点的流程:
- 解析请求与参数检查。
- 找出需要进行 pipeline 处理的请求,转发给预处理节点进行处理,成功后进入下一步。
- 为不存在的索引自动创建索引。
- 将 Bulk 请求以 ShardId 进行分组,每个 ShardId 分组包装成 BulkShardRequest,然后进行转发到对应的主分片节点上进行处理。
ok,到此协调节点上的流程就已经走完了,下面看看主分片节点的处理流程。
三、主分片节点的处理流程
在我们之前介绍的内容中可以得知:主分片的写入流程会先写主分片,主分片写入成功后会并发写各个副分片,然后等待各个副本分片的写入响应,最后回复协调节点。下面我们来跟踪一下主分片写入流程的源码。
照例,我们必须要找到这个处理流程的入口。在 TransportReplicationAction 的构造函数中,分别注册了主分片、副本分片的处理函数:
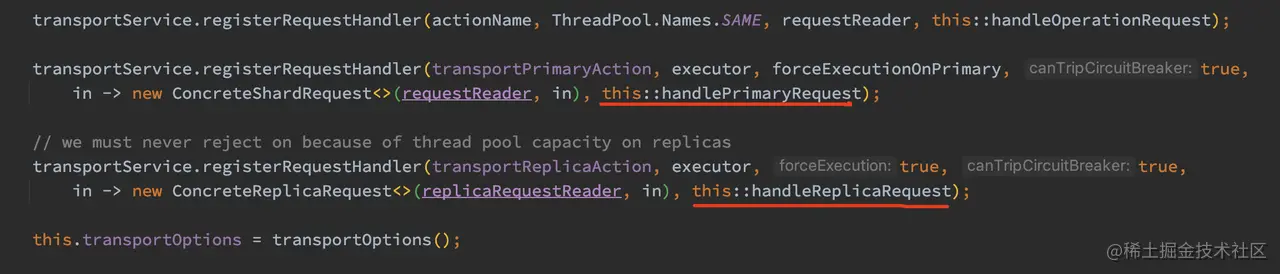
如上代码,主分片的写入操作入口为 handlePrimaryRequest 方法,其主要创建了 AsyncPrimaryAction 实例,并且调用其 run 方法,所以整主分片写入逻辑的实现是在 AsyncPrimaryAction.doRun 方法中实现的。下面我们从 AsyncPrimaryAction.doRun 开始跟踪。
1、写入前的检查
AsyncPrimaryAction.doRun 主要的工作是进行一些写入前的检查工作,并且开启后续的流程,其实现如下:
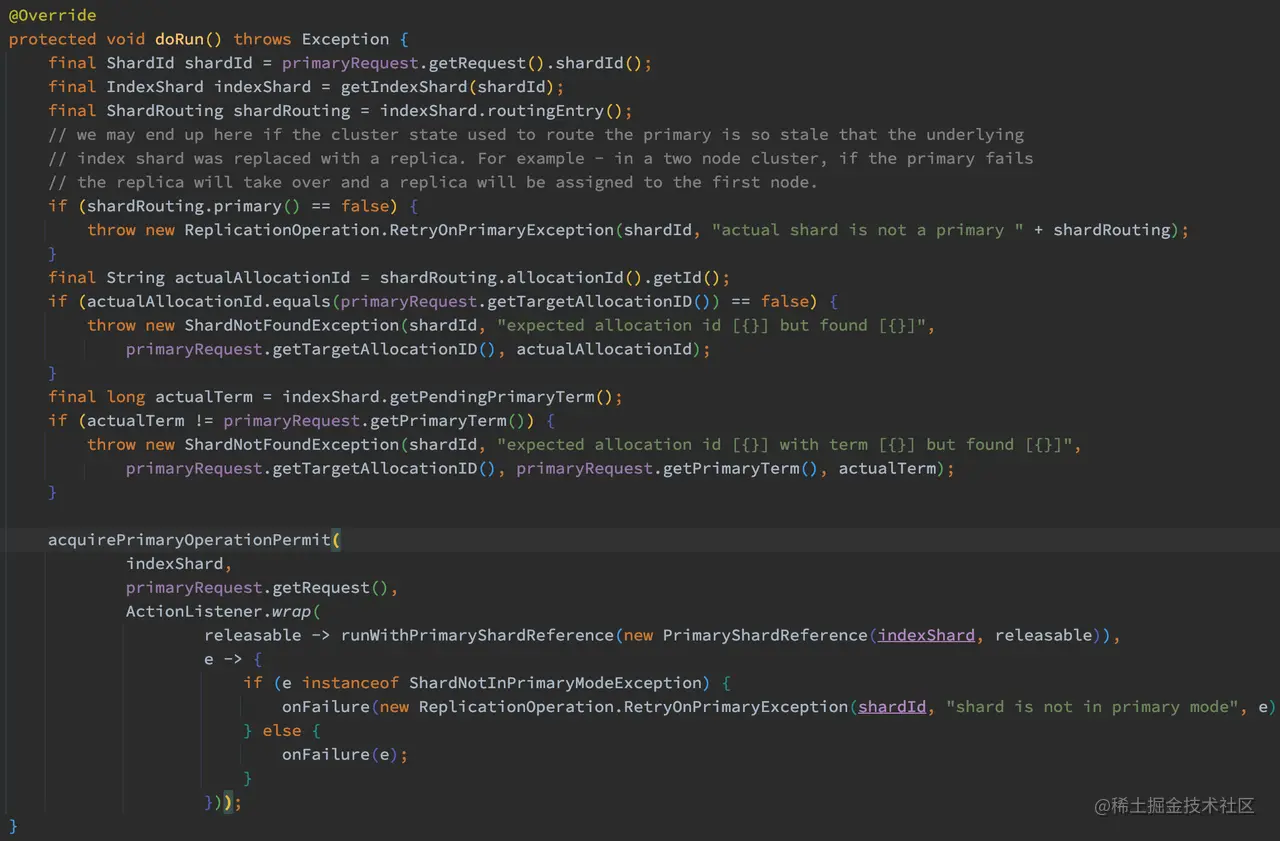
如上代码,AsyncPrimaryAction.doRun 主要做了以下几个操作:
- 执行请求前的检查,在主分片节点收到请求后是要先对请求进行检查的,不是一股脑直接插入数据。主要检查项有:当前分片是否为主分片、AllocationId 是否为期望值、PrimaryTerm 是否为期望值。其中 AllocationId 我们还没有介绍过,这玩意其实跟 Allocation (分片分配)相关。
- 在 runWithPrimaryShardReference 方法中,判断集群是否处于阻塞状态,是的话直接报错。
- 在 runWithPrimaryShardReference 方法中,判断主分片是否已经迁移,如果已经迁移,调用 transportService.sendRequest 将请求转发到对应的节点上进行处理。如果没有迁移,设置任务的阶段为 “primary”,然后创建 ReplicationOperation 实例,并且调用其 execute 方法。
这个 ReplicationOperation.execute 是整个主分片数据写入操作的入口,下面我们来跟踪一下:
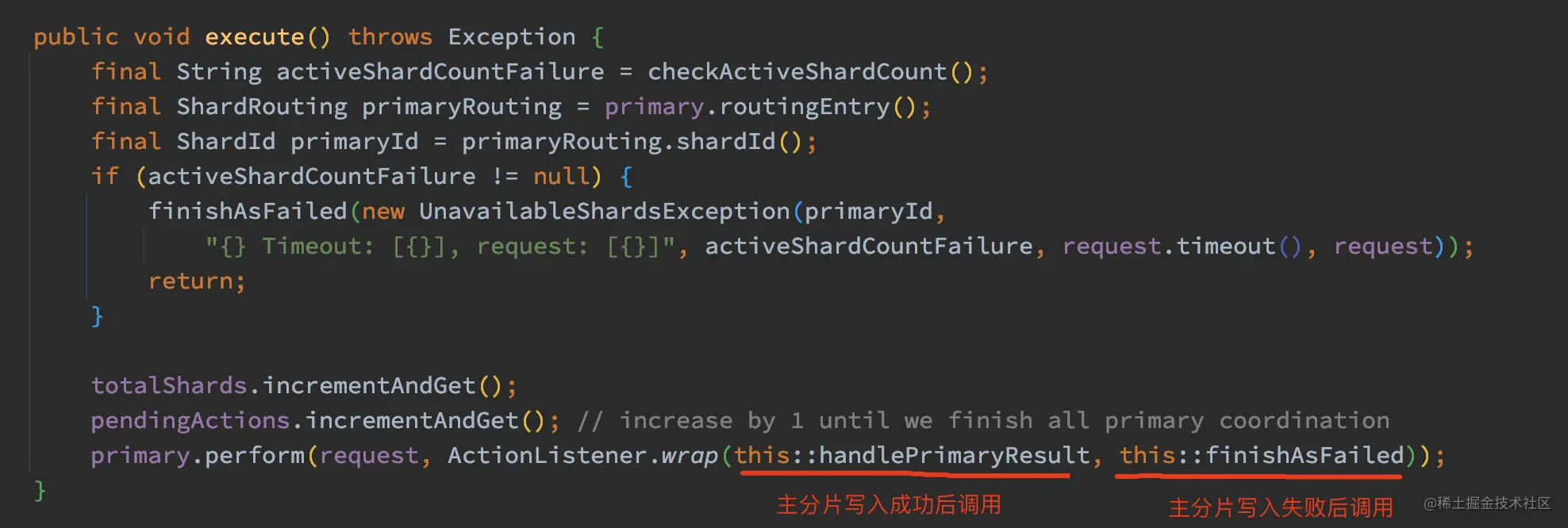
如上代码,ReplicationOperation.execute 方法首先调用 checkActiveShardCount 方法进行写入一致性检查:
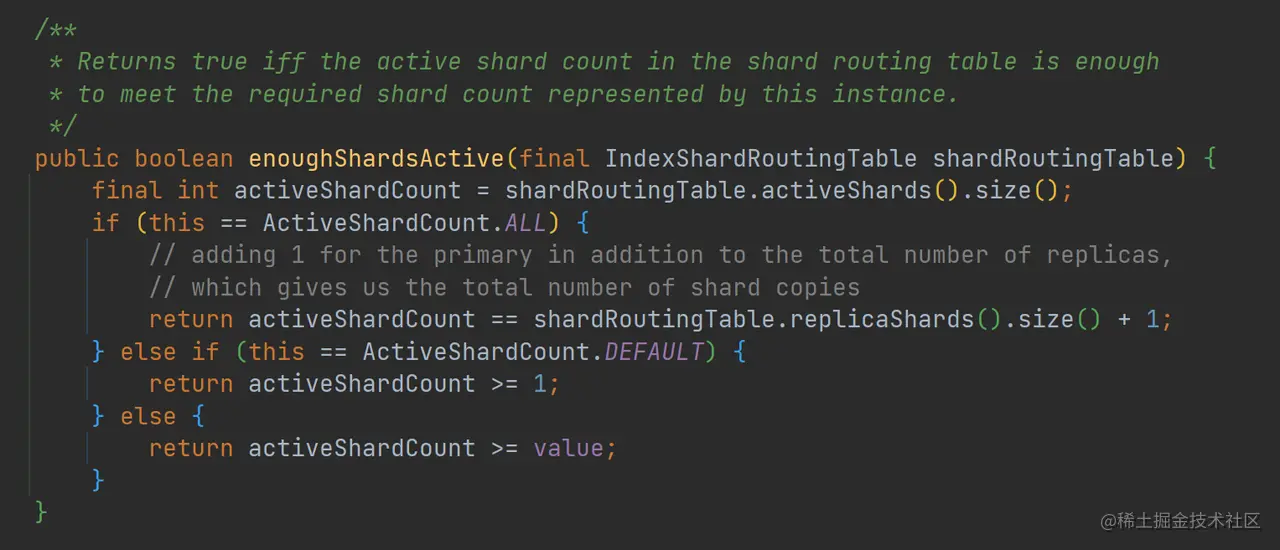
checkActiveShardCount 方法最终调用了 enoughShardsActive 方法,在写入数据前先检查活跃的 Shard 的数量是否足够。默认的情况下,wait_for_active_shards 为 1,也就是默认只需要主分片活跃就可以进行数据写入。需要注意的是,wait_for_active_shards 它只代表当前活跃的分片的数量,并不是代表一定可以写入数据到 wait_for_active_shards 个分片中。
2、写入主分片
做完检查后,可以将数据写入主分片了。在 ReplicationOperation.execute 方法最后调用了 primary.perform 方法,其实际为 PrimaryShardReference.perform。但由于这里的调用链有点长,并且不都是重点,所以我这里直接给出整个调用链的关系:
ReplicationOperation.execute ---调用--->primary.perform --实际为--> PrimaryShardReference.perform --调用-->TransportWriteAction.shardOperationOnPrimary --调用-->// TransportShardBulkAction 继承了 TransportWriteActionTransportShardBulkAction.dispatchedShardOperationOnPrimary --调用-->TransportShardBulkAction.performOnPrimary --调用-->TransportShardBulkAction.executeBulkItemRequest
这里需要注意 primary.perform 中的两个回调函数, 其中 handlePrimaryResult 方法,在主分片写入操作成功后会调用这个方法,而失败会调用 finishAsFailed 方法。
ok,这里我们把重点放在这条调用链的 TransportShardBulkAction.performOnPrimary 方法上:
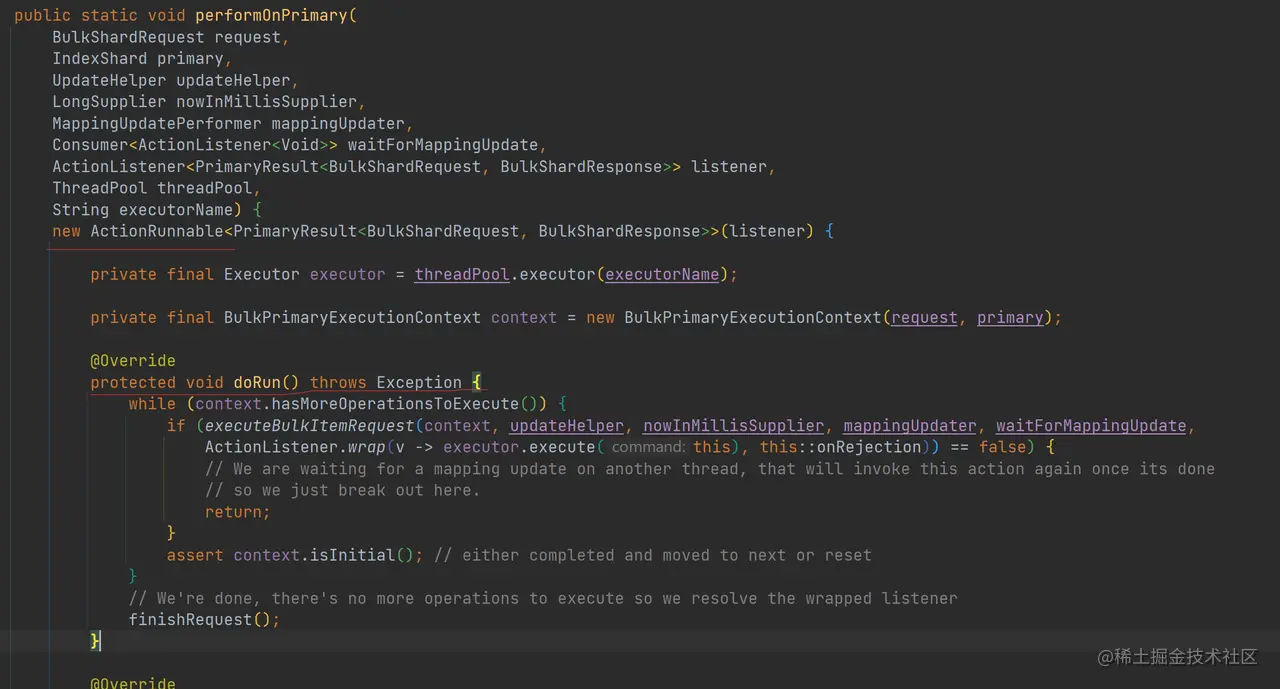
如上代码,performOnPrimary 方法创建了 ActionRunnable 实例,并且调用其 run 方法。可以发现在 doRun 中会遍历 BulkShardRequest 中的 BulkItemRequest,并且调用 executeBulkItemRequest 方法。
其中 executeBulkItemRequest 方法就比较简单了,它会根据 BulkItemRequest 类型的不同进行不同的逻辑处理,并且处理单个请求的异常。
在 executeBulkItemRequest 中也有一条非常长的调用链(这里列出插入、更新操作的调用链,删除的逻辑可以自己跟踪):
IndexShard.applyIndexOperationOnPrimary --调用-->IndexShard.applyIndexOperation --调用-->IndexShard.Index --调用-->InternalEngine.Index --调用-->InternalEngine.indexIntoLucene
这里我们重点关注 InternalEngine.index 方法,此方法为写入数据的主要逻辑。通过 Index 参数构造plan(索引数据的策略),然后通过 plan 执行相应的操作。如果要写入数据,则调 InternalEngine.indexIntoLucene 写入数据,完成后再写 translog,最后根据配置的 flush translog 策略进行刷盘。下图为 index 方法的主要部分:
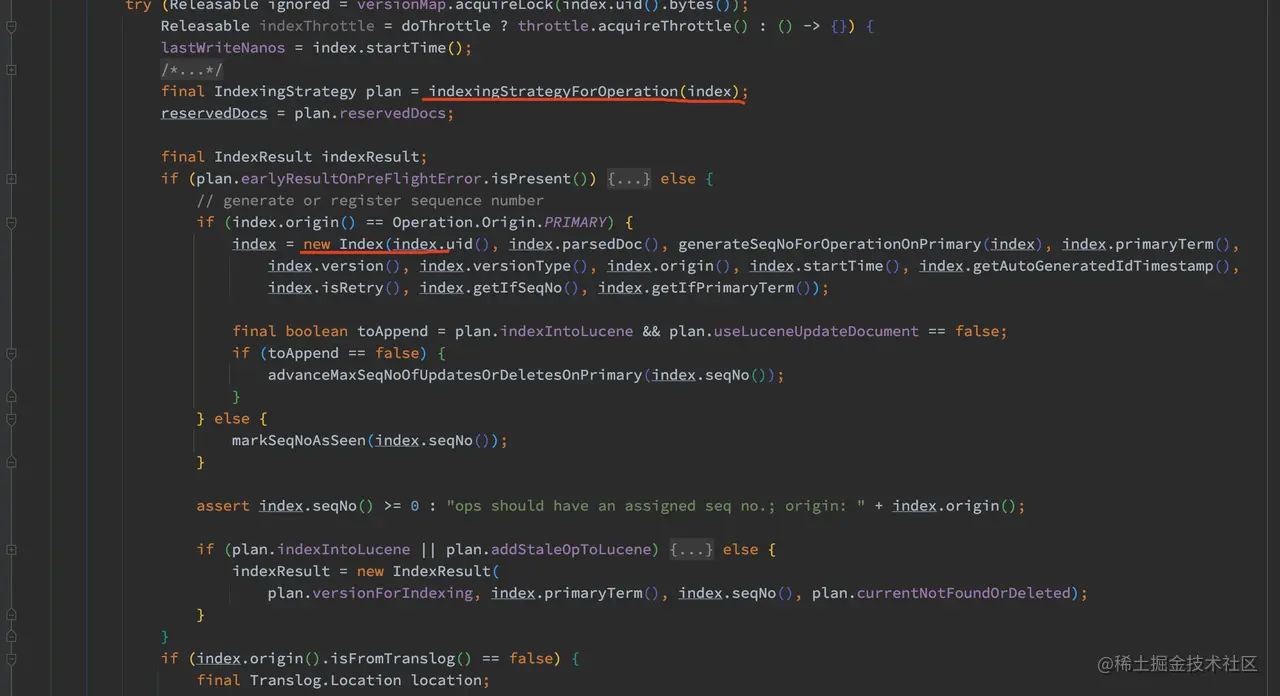
如上代码,在写数据的时候,我们需要知道这个数据是否已经存在,这个逻辑在 indexingStrategyForOperation 方法里进行了处理。需要注意的是,在添加一个文档的时候,如果 id 是非用户自定义的话,可以直接 add 文档,否则需要进行 update 操作。而 update 比 add 开销要高得多,因为要先做查询,具体的原因可以看看这个部分的注释。
indexingStrategyForOperation 方法会调用 planIndexingAsPrimary 方法:
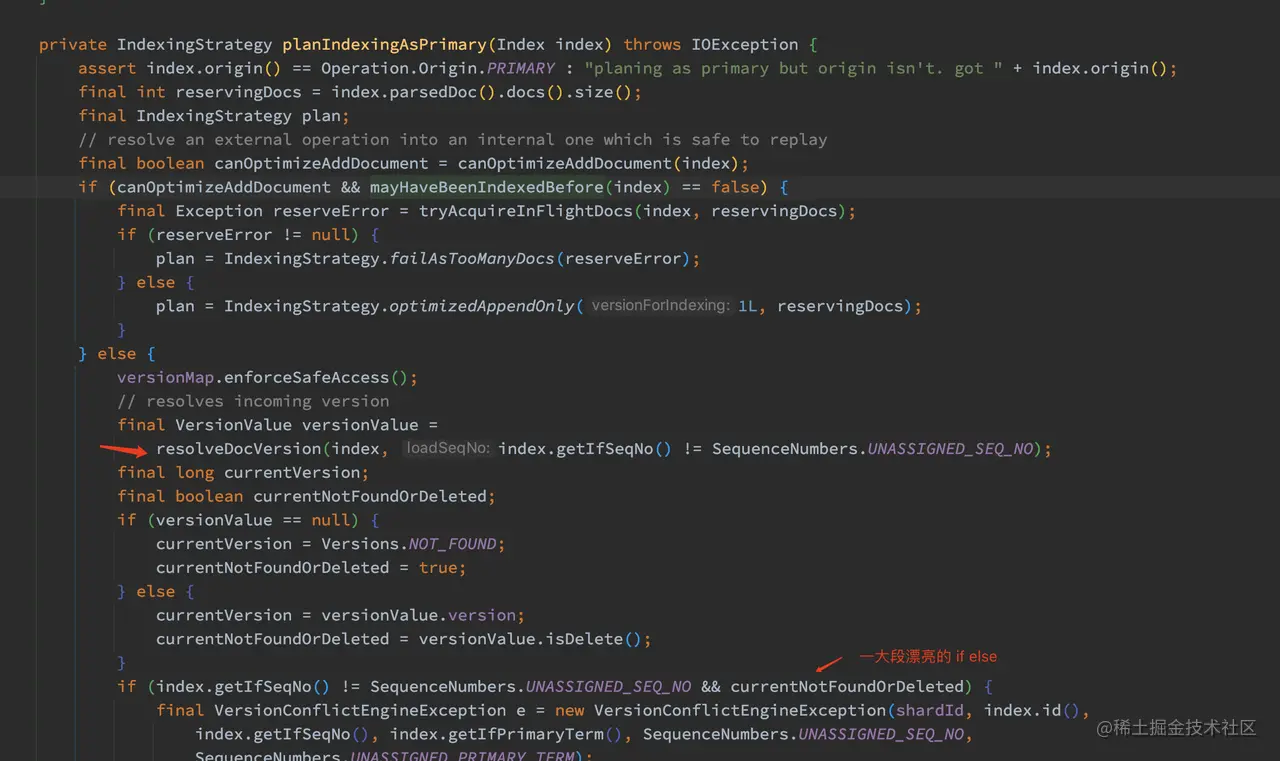
如上代码,planIndexingAsPrimary 方法判断了 Index 是否可以直接 add document,这个结果保存在 canOptimizeAddDocument 里。
另外还需要判断版本号是否冲突了,调用 resolveDocVersion 获取 VersionValue,这个简单,就是从 LiveVersionMap 中获取数据,这个机制我们在上一章已经介绍过了。如果在 LiveVersionMap 中找不到,那就去磁盘文件中获取,此处在 VersionsAndSeqNoResolver.loadDocIdAndVersion 中进行实现,从名字也可以看出,只获取了 id 和 version,而不是获取整个文档的信息。
最后,一堆感人的 if else 来判断是否有版本冲突。
下面简单总结一下写主分片的特点:
- 可以发现 ES 在写入数据时候是先写 Lucene,然后再写 translog 的,先写 Lucene 的好处是可以对数据进行非常多的检查,并且此时失败不需要回滚。如果先写 translog,然后再写 Lucene,一旦 Lucene 写入出错,就需要回滚操作,这个处理起来就复杂了。
- 在索引数据的时候,应尽量用系统分配的随机 id,除了可以避免上一章提到的数据倾斜的问题,还可以提高写入的效率。
- 主分片写入失败是没有重试的!
ok,在写 Primary 成功后,下面看看 ES 如何将数据同步给副本节点的。
3、同步数据到副本节点
Primary 成功写入后的处理回调方法为 ReplicationOperation.handlePrimaryResult ,此方法主要调用 ReplicationOperation.performOnReplicas 请求转发到副本节点上进行处理:
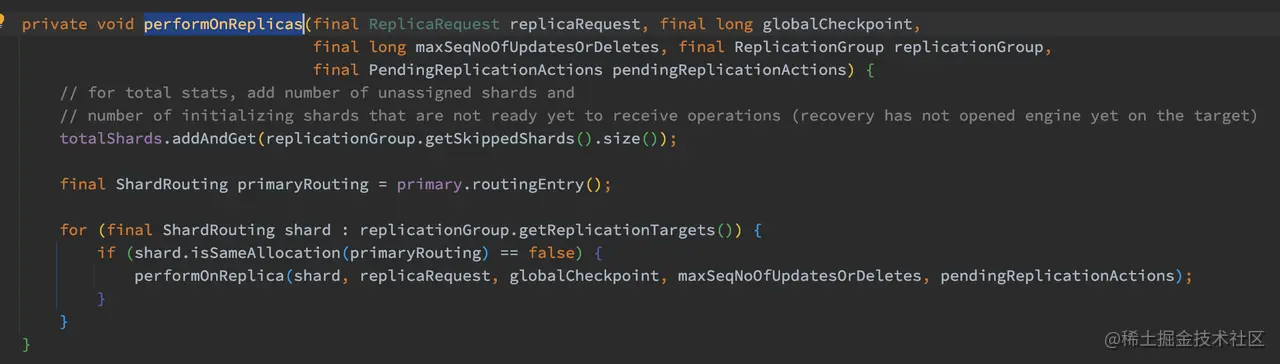
如上代码,迭代每一个副本分片,将 replicaRequest 发送到对应的副本节点上,注意这个操作是并行的、异步的。但如果副本节点和主分片节点为同一个,则忽略操作。
调用的 performOnReplica 方法会将请求转发到对应的副本节点上进行处理,如果某个副本出现异常,主分片节点会将此报告给 Master 节点,Master 节点会执行移除此副本的操作:
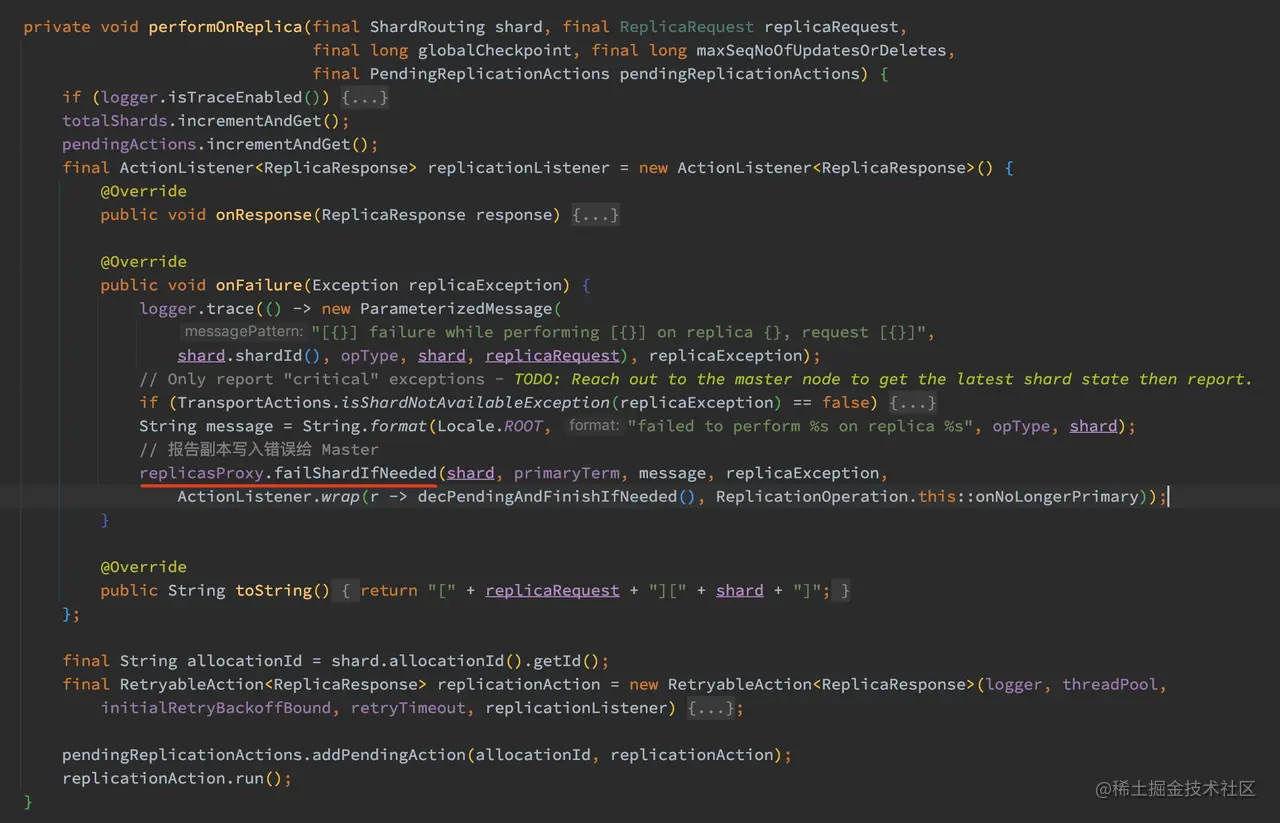
在主分片写入的流程中,replicasProxy 具体实现为 WriteActionReplicasProxy 类,failShardIfNeeded 方法会将发生错误的副本分片报告给 Master 进行处理。Master 收到请求后会从 in_sync_allocations 中把对应的副本删除,然后将集群元数据同步到集群所有节点中去。
所以从这里可以看出,数据写入的时候是需要等到所有副本写操作完成后再返回,即使在部分副本上操作失败。
ok, 主分片的流程已经好了,下面看来看看副分片节点的处理流程。
四、副分片节点的处理流程
在 TransportReplicationAction 的构造函数中,注册了副本分片的处理函数:handleReplicaRequest。所以副本分片的处理流程的入口在 TransportReplicationAction.AsyncReplicaAction.doRun 中处理:
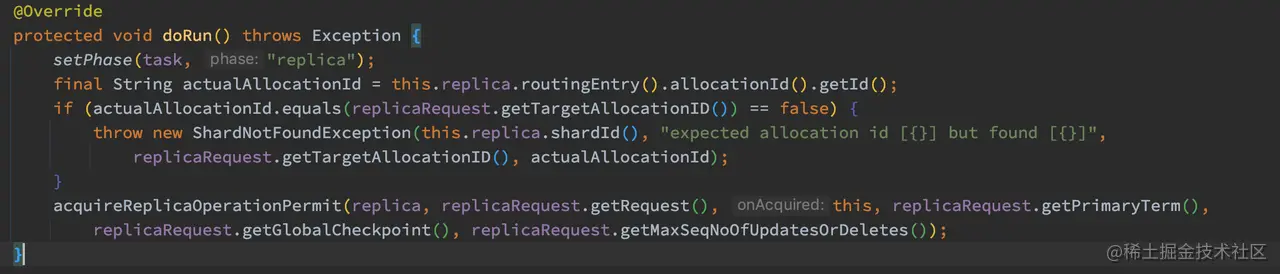
副本节点执行的写入流程与主分片写入流程基本相同,在副本写入操作完成后会回复主分片节点写入的结果。既然副本的写入操作与主分片写入流程相似,那么副本在写入数据到 translog 后就可以返回了。
五、更新 Checkpoints
在数据写入的流程里,有一个非常重要的操作,那就是更新 Checkpoints。在看源码前我们先来复习一下以下几个概念。
1. 每个写操作的标识:Sequence ID
ES 在 6.0 后引入了 Sequence ID 的概念,通过使用唯一的 Sequence ID 来标记每个写入操作,可以对索引的操作做总排序。
Sequence ID 逻辑上由 Primary Term 和 Sequence Number 组成, 主分片在向副本转发写入请求的时候都会带上这两个值:
- Sequence Number,标识某个分片上的每次写入操作,由 Primary 分配和管理,每次写入操作后会递增。Sequence Number 既然由 Primary 分配,所以其跟 Primary 的任期(Term)挂钩。
- Primary Term,代表的是主分片的一个版本,由 Master 节点进行分配。当一个分片被提升为主分片时,Primary Term 就会递增,然后会持久化到集群状态中去。
2. 用于快速恢复数据的 Checkpoints
ES 使用本地检查点和全局检查点来标记从副本与主副本的差异,而这两个检查点的值就是上述提到的 Sequence ID。利用 CheckPoints 可以实现加快数据的恢复过程,它们的定义如下:
- 全局检查点(GlobalCheckpoint), 是所有活跃分片历史都已经对齐、持久化成功的序列号,所以小于全局检查点的操作都已经在所有副本上处理完了。当主副本下线后,系统只需要比较新的主副本与其他从副本间最后一个全局检查点之后的操作即可。
- 本地检查点(LocalCheckpoint), 代表着此副本中所有小于这个值的操作都已经处理完毕了(写 Lucene 和 Translog 都成功了)。
如果你对上面这些概念还很陌生,那么我建议你再阅读一次 《数据不丢失的奥秘(上):副本策略》和 《数据不丢失的奥秘(下):ES 的数据副本模型》。下面来看看更新 Checkpoints 的源码实现。
1、更新 Checkpoints 的时机
在主分片写入成功后,会向各个副本同步数据,这个时候需要带上 GlobalCheckpoint 和 SequenceNumbers,这个操作在 ReplicationOperation.handlePrimaryResult 方法中进行处理:
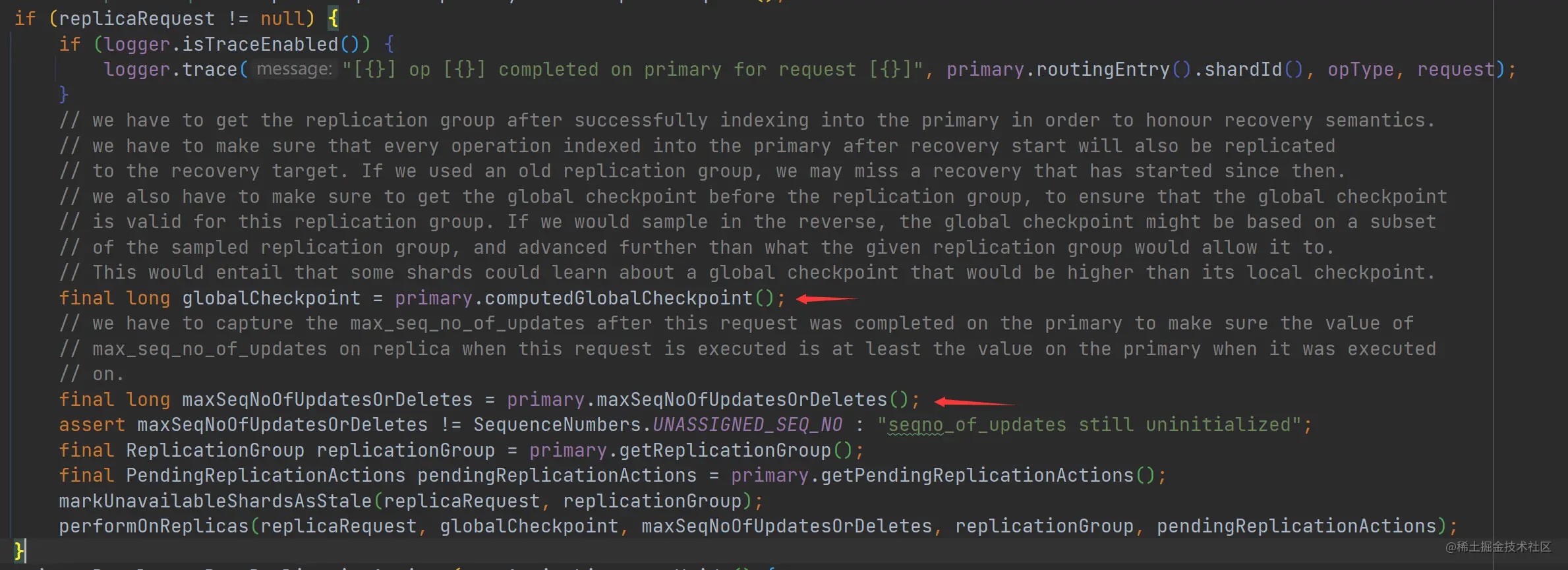
如上代码,这里只有 GlobalCheckpoint 和 Sequence Number,而 Primary Term 其实在 ReplicationOperation.performOnReplica 方法中调用 replicasProxy.performOn 方法时传递过去了。
在主分片写入成功后,主分片会更新 Checkpoints,同样这个操作也在 ReplicationOperation.handlePrimaryResult 方法中进行处理:
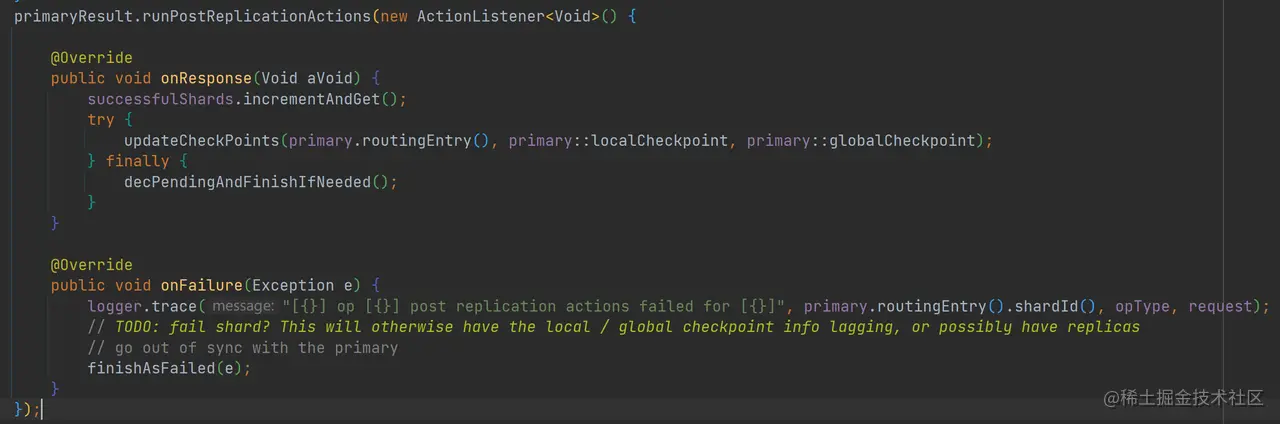
如上代码,在异步发送同步数据请求后,执行更新 Checkpoints 操作。
除了写入主分片成功后会更新 Checkpoints 外,在副本节点执行请求返回成功后,也会执行更新 Checkpoints 的操作:
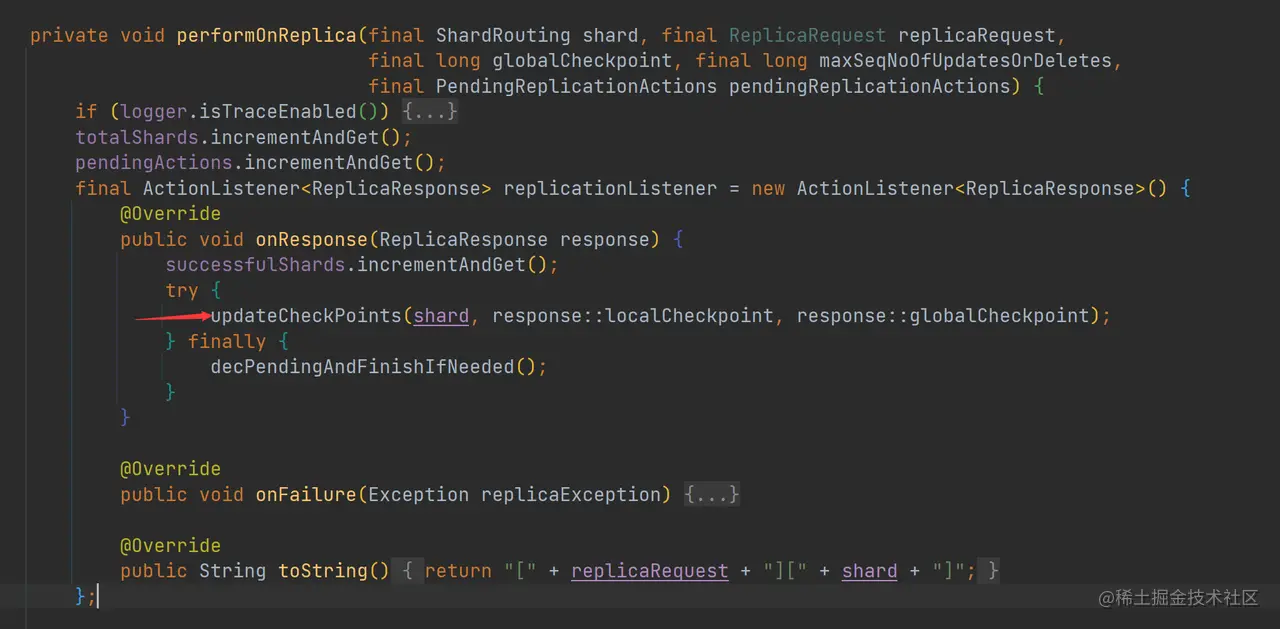
updateCheckPoints 方法调用了 Primary.updateLocalCheckpointForShard 方法更新 LocalCheckpoint 和调用 Primary.updateGlobalCheckpointForShard 更新 GlobalCheckpoint。
2、更新 Checkpoints 的具体实现
我们先来看看 LocalCheckpoint 的更新流程,Primary.updateLocalCheckpointForShard 方法最终调用了 ReplicationTracker.updateLocalCheckpoint:
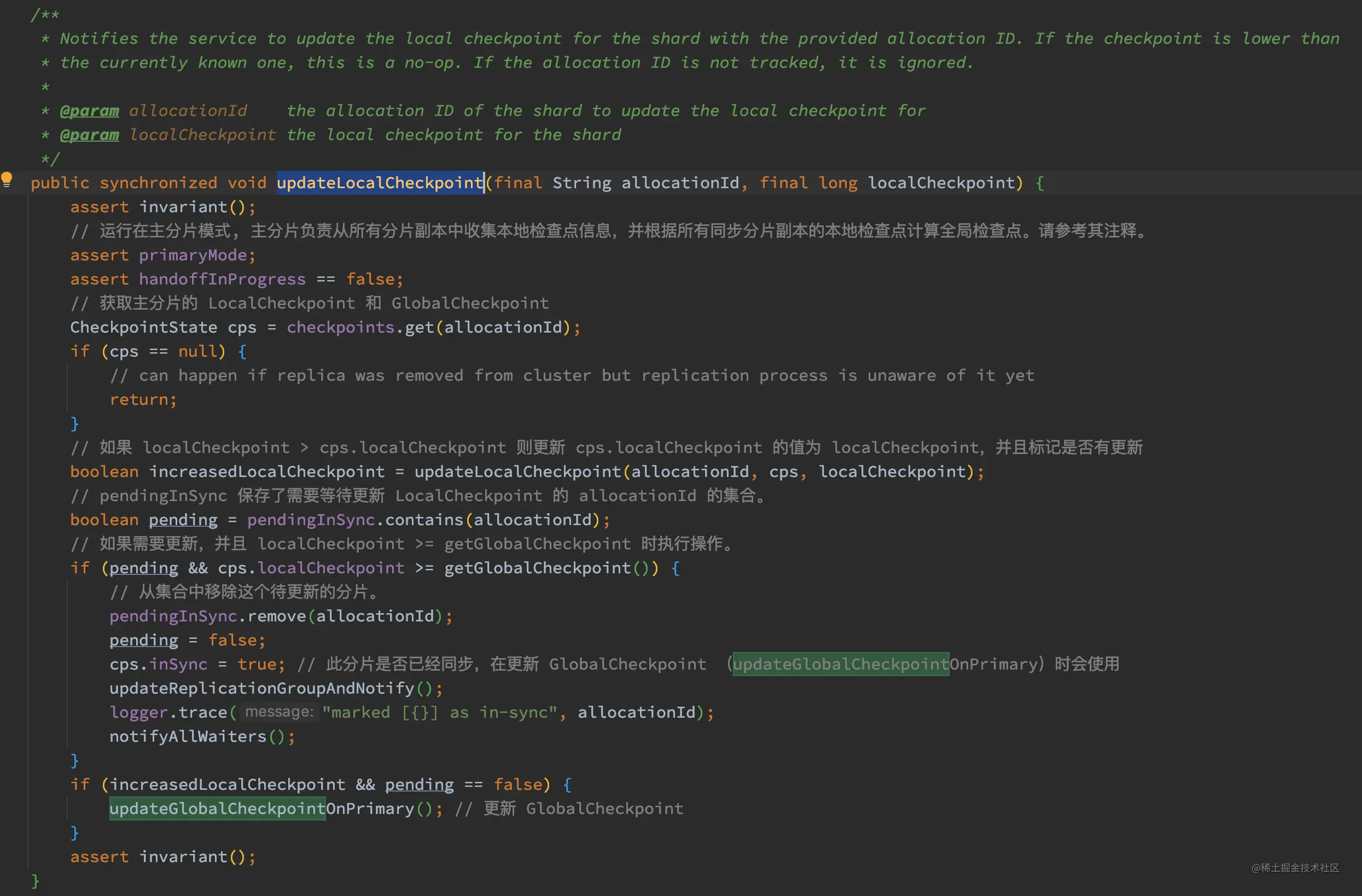
如上代码,其注释已经比较清楚了,这里不在赘述。
下面来看看 updateGlobalCheckpointOnPrimary 方法的实现:
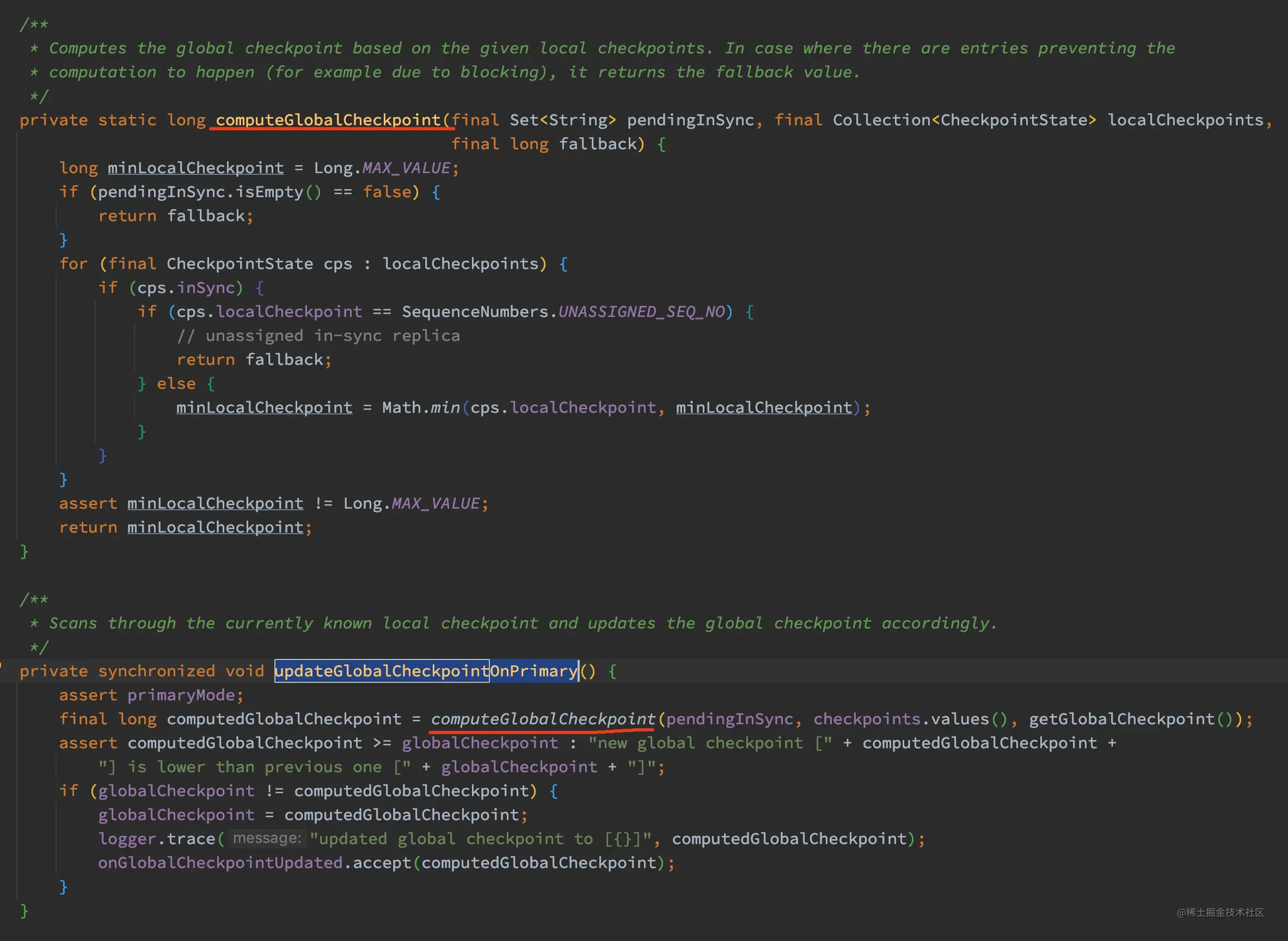
如上代码,updateGlobalCheckpointOnPrimary 方法先调用 computeGlobalCheckpoint 获取一个计算出来的 GlobalCheckpoint,如果这个计算出来的 GlobalCheckpoint 大于当前的 globalCheckpoint,则更新当前的 globalCheckpoint 的值为计算出来的 GlobalCheckpoint。
那为啥要在这里以这个方式更新 GlobalCheckpoint 呢?参考 computeGlobalCheckpoint 的实现,这个计算出来的 GlobalCheckpoint 其实是分片副本组中最小的那个 localCheckpoint。所以这里操作的意义是将 GlobalCheckpoint 向前推,毕竟在最小的 localCheckpoint 那个点,数据都已经在所有副本中持久化了。
完成了 LocalCheckpoint 的更新,下面我们来看看 Primary.updateGlobalCheckpointForShard 的实现,此方法最终调用了 ReplicationTracker.updateGlobalCheckpointForShard:
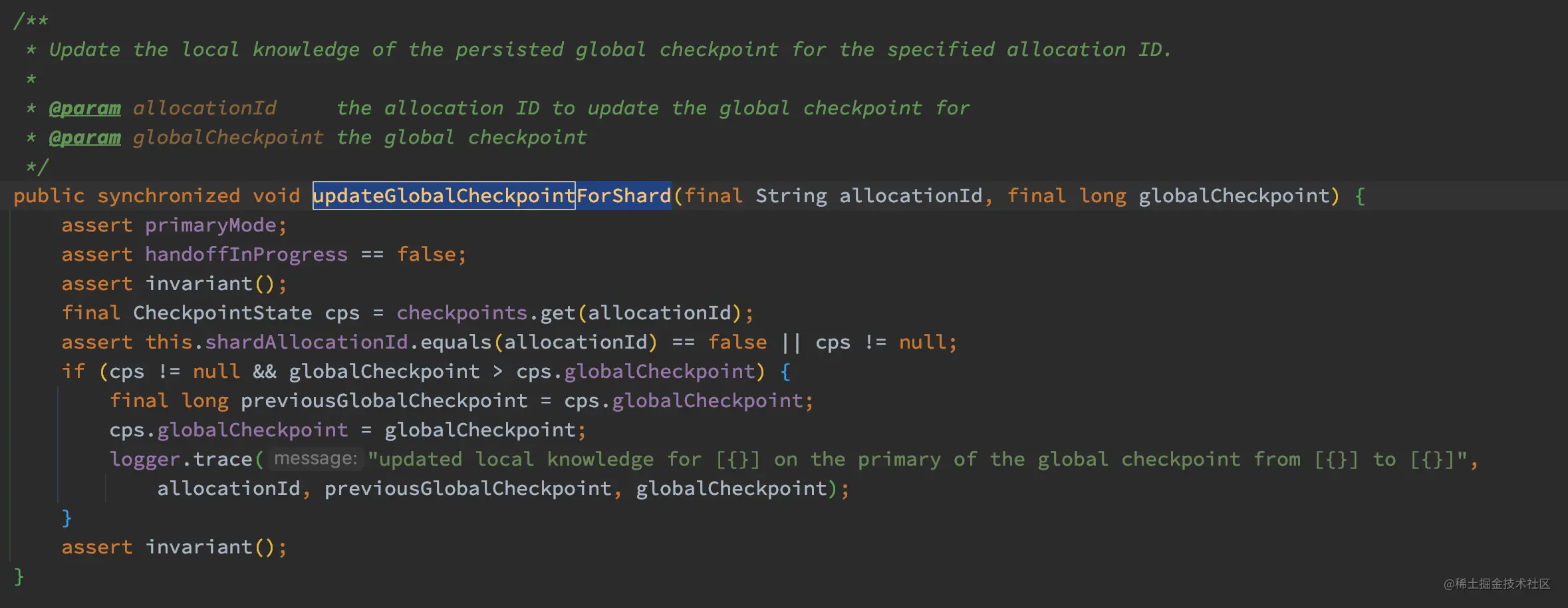
如上代码,updateGlobalCheckpointForShard 的逻辑比较简单,如果 globalCheckpoint > 当前的 cps.globalCheckpoint,则设置 cps.globalCheckpoint 的值为 globalCheckpoint。
这里需要注意的是,updateLocalCheckpointForShard 和 updateGlobalCheckpointForShard 的调用其实在主分片写入完成后调用了一次,然后每个副本分片写入成功返回后都会调用一次。
六、总结
今天我与你阅读、跟踪了 Index API 和 Bulk API 的源码。因为 Index API 最终会转化为 Bulk 来进行操作,所以我们今天主要是学习了 Bulk API 的实现。
文档写入的流程是非常复杂了,涉及的节点也很多,主要有:
- 协调节点,主要负责接受请求、参数解析与校验,请求转发等工作
- 预处理节点,主要负责数据预处理。
- 主分片节点(数据节点),主要负责数据写入,同步数据到副本分片节点。
- 副本分片节点,备份的数据写入。
- Master 节点,处理异常的分片。
通过阅读源码,我整理了下图来对 Bulk API 源码流程做一个简单总结:
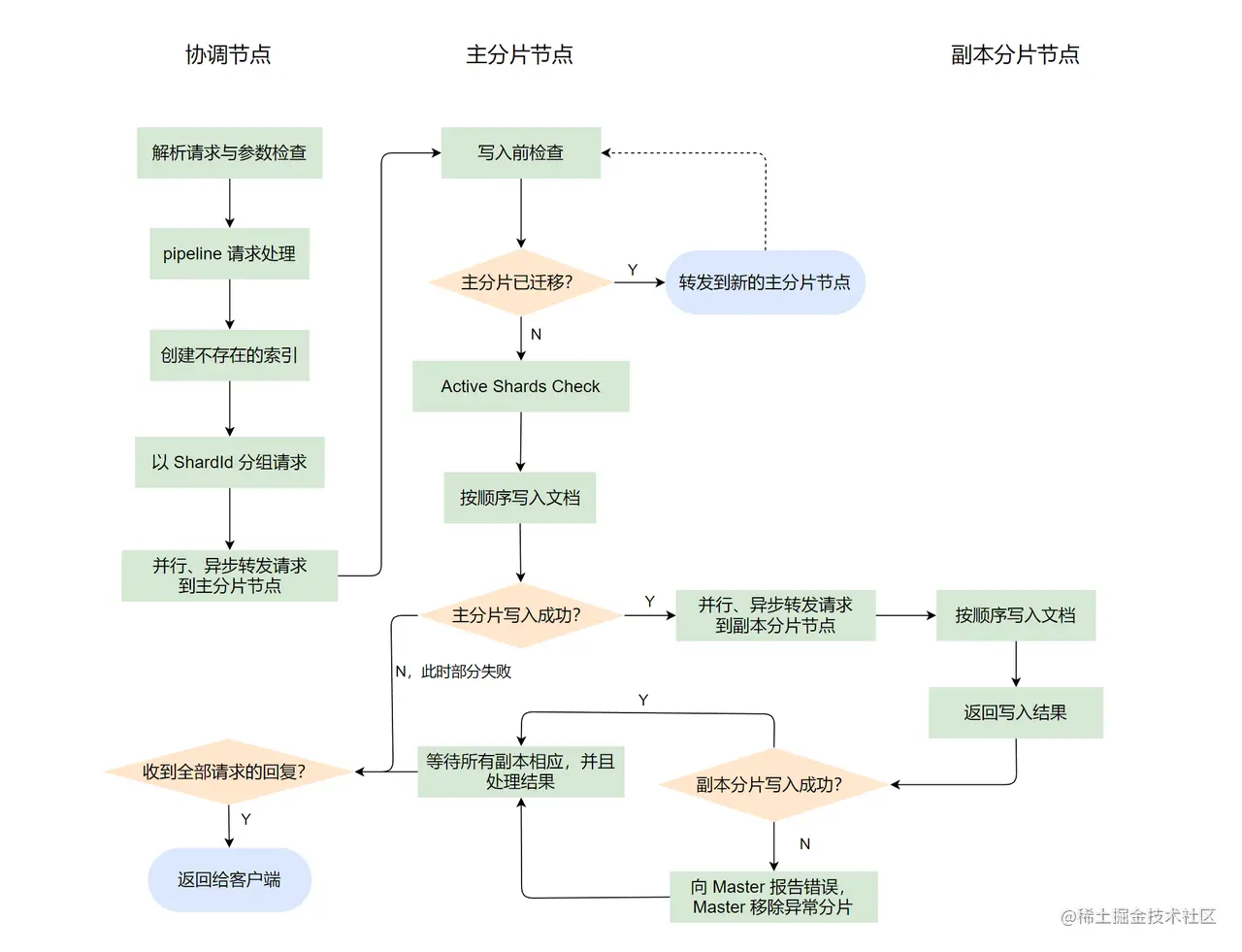
最后我们来回答最开始提出的几个疑问,虽然这些问题都在对应的部分有所回答了。
- wait_for_active_shard 的作用到底是啥?
在写入数据前先检查活跃的 Shard 的数量是否足够。默认的情况下,wait_for_active_shards 为 1,也就是默认只需要主分片活跃就可以进行数据写入。需要注意的是,wait_for_active_shards 它只代表当前活跃的分片的数量,并不是代表一定可以写入数据到 wait_for_active_shards 个分片中。
- ES 写入操作是只需要写入主副本成功就可以返回了,还是需要等到全部副本处理成功才能返回?,或者只需要部分处理成功即可返回?
只要数据写入到主分片就可以认为写入成功了,至于什么时候可以返回,当然是需要等待所有副本分片写入成功后才返回了。
- 副本写入成功的标准啥?
副本的写入操作与主分片写入流程相似,所以副本在写入数据到 translog 后就是成功写入了,然后可以返回给主分片节点了。
- Index API 是共用了 Bulk API 的流程吗?
Index API 是共用了 Bulk API 的流程。
