在 《数据不丢失的奥秘(上):副本策略》 中我为你介绍了 PacificA 算法,也提到 ES 在数据副本模型的实现中参考了 PacificA 算法,所以这一讲我们就“趁热打铁”,接着来了解一下 ES 的数据副本模型。
我们知道,ES 的索引分片分为主分片和副分片(这两种分片我们都称为副本,只不过主分片也叫主副本),由于有多个副本的存在,系统需要同步数据到多个从副本中,那你有没有想过以下的几个问题:
- 多个节点上的主副本和从副本到底要怎么同步数据才能保证数据不会丢失呢?
- 数据恢复时需要复制整个主副本的数据吗?
- 主副本下线了,数据会丢失吗?
- 在从副本读取数据,总能读到最新的数据吗?数据是如何保证一致性的?
- 多个副本存在的情况下,是不是要全部副本都写成功才会返回给客户端?
今天带着这几个问题,我们来学习一下 ES 的数据副本模型,废话不多说,我们直奔主题!
既然 ES 在数据副本模型的实现中参考了 PacificA 算法,那先来看看 PacificA 中的基本术语在 ES 中的实现。
- Master 负责维护索引的元信息,类似于 PacificA 中的配置管理器维护 Configuration。
- 集群状态(使用 GET /_cluster/state 可以查询集群状态)中的 routing_table 保存了所有索引相关的信息,包括索引的分片、分片所在的节点等信息。而其中 Index Metadata 中的 in_sync_allocations 记录了同步的副本,类似于 Replica Group。
- ES 为每次写入操作都分配一个唯一的 ID,也就是 Sequence Number 来记录每个写入操作 ,类似 Serial Number。
- 在每次 Primary 变更的时候都会对主分片做一个标记(变更时自增),叫做 Term(任期) ,类似于Configuration Version 。
- ES 使用 Checkpoint 来保存每次写入操作的位置,类似于 Commit point。
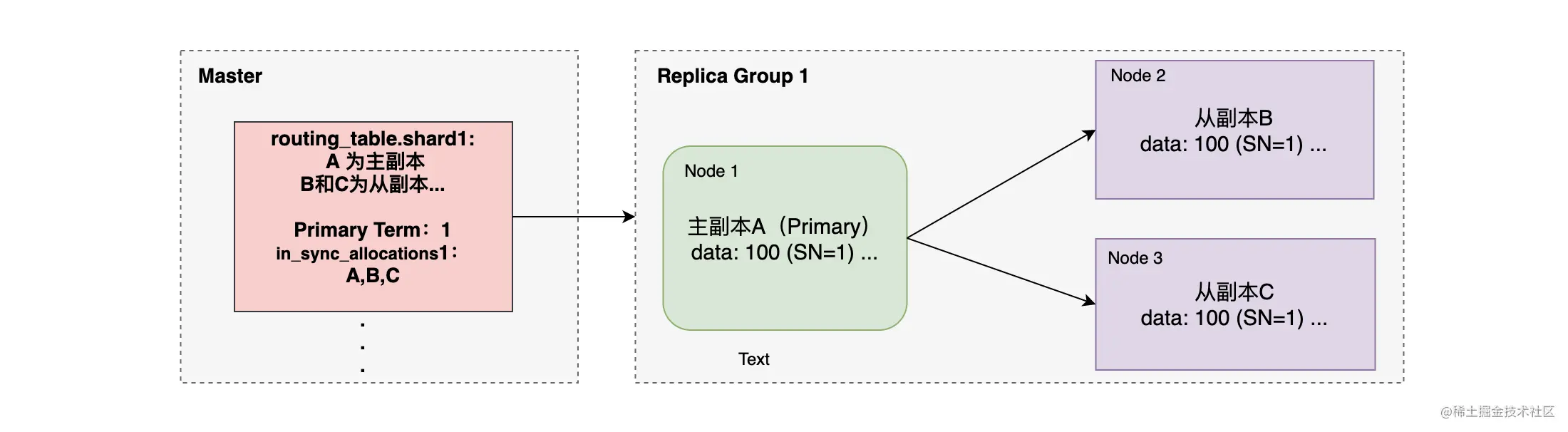
如上图,图中给出了 ES 中相关术语的关系,其中 Checkpoint 没有画出,你也可以使用下面的指令在 Kibana 中查看相关概念的示例:
# 查看 Index Metadata 的信息,其中包含了 in_sync_allocations 相关的信息# 将 your_index 改为你要查看的索引的名字GET /_cluster/state?filter_path=metadata.indices.your_index# 查看索引拥有的分片和每个分片的副本组信息# 将 your_index 改为你要查看的索引的名字GET /_cluster/state?filter_path=routing_table.indices.your_index
了解完这些概念之后,就可以对 ES 的数据副本模型进行讨论了。下面我们将通过:主分片分配、Sequence ID 概念模型、ES 读写故障处理、快速恢复数据这四个部分来介绍 ES 的数据副本模型。
一、主分片的分配
通过对 PacificA 算法的学习,我们知道主副本维护了数据的一致性,如果在集群中出现双主副本的话,对系统来说将会是一场灾难。所以,如何分配主分片并且保证只有一个主分片是非常重要的。
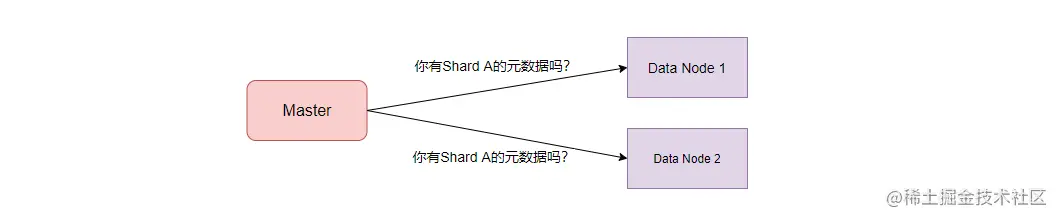
主分片的分配工作是由集群主节点(Master)来负责的,在系统启动的时候,由于没有分片的信息,所以 Master 会向集群中所有数据节点询问这个分片的元信息。在 Master 获取了分片的元信息后,接下来就要在多个符合要求的副本中选取一个作为主副本了。
ES 在 5.x 之后的版本中引入了 Alloction ID 来作为每个副本的唯一标识。在集群的元信息中,in_sync_allocations(同步副本集合) 记录相关分片活跃的、含有最新数据的副本的 Alloction ID。在系统启动时,主节点会检查副本的 Allocation ID 是否在 in_sync_allocation 中,只有存在于这个集合中,这个副本才有可能被选为主副本。
二、每个写操作的标识:Sequence ID
在 PacificA 中使用 Serial Number 来标识每个写入操作,因为 SN 是递增的,所以可以对副本上的操作进行排序。对每个写入进行排序标识,一方面可以识别一些无效的操作,如丢弃一个 SN 更小的过时操作,另一方面可以为数据恢复提供加速的依据。
ES 在 6.0 后引入了 Sequence ID 的概念,通过使用唯一的 Sequence ID 来标记每个写入操作,可以对索引的操作做总排序。Sequence ID 逻辑上由 Primary Term 和 Sequence Number 组成。 如下代码是插入一条数据后返回的结果,其中 “_seq_no “ 字段的值就是 Sequence Number,”_primary_term “ 就是 Primary Term。
{......"_shards" : {"total" : 3,"successful" : 3,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1}
- Sequence Number,由 Primary 分配和管理,每次写入操作后会自加。Sequence Number 既然由 Primary 分配,所以其跟 Primary 的任期(Term)挂钩。
- Primary Term,代表的是主分片的一个版本,由 Master 节点进行分配。当一个分片被提升为主分片时,Primary Term 就会递增,然后会持久化到集群状态中去。
虽然有了 Primary Term 和 Sequence Number,但怎么比较两个写入操作的“大小”呢?每次写操作时,主分片在转发数据时都会带上 Primary Term 和 Sequence Number,那么在比较两个操作 Operation1 和 Operation2 时,可以这样判断:
如果 Operation1.term < Operation2.term 则 Operation1 < Operation2如果 (Operation1.term == Operation2.term && Operation1.seq_id < Operation2.seq_id) 则 Operation1 < Operation2
有了 Primary Term + Sequence Number,系统可以检测出分片副本的差异,可以加速数据恢复的过程。
三、ES 的读写故障处理
关于数据的读写流程,我们在 《人多好办事:分布式文档搜索机制》和《数据持久化:分布式文档的存储流程》 中已经详细介绍过了,这里主要看一下读写流程中会出现的故障和对应的处理方式。
1. 写故障处理
数据写入时主要会发生以下两种故障:写主分片时发生错误和写入其他副分片时发生异常。
如果写主分片发生错误,那么这个主分片所在的节点就会向 Master 汇报。这个时候写入操作会等待(默认 1 分钟)直到 Master 选出一个新的主副本,然后写入操作会被转发到新的副本中进行处理。如果是主副本因为网络异常、宕机离线的话,Master 也会自动监测节点的健康状态,并且会主动降级某个离线主副本。
如果在写入其他从副本时发生异常,主副本节点会通知 Master 将这个异常的副本从同步副本集合(in-sync replica set)中移除。一旦 Master 确认移除这个副本,主副本就会确认这次操作。需要注意的是,Master 会在另一个节点上创建一个新的副本来使集群状态变为健康状态。
这里还需要注意的是,ES 写副本操作和写故障处理跟 PacificA 的模型是有区别的!
ES 在写入数据时默认只需要保证主副本写入了即可,并在返回结果中返回写入成功和失败的分片数量。从这可以看出在可用性和一致性的取舍上,ES 更倾向于可用性,而 ES 本身就定位为近实时的系统,不去选择强一致性也是合理的。
另一个区别是,当某个副本写入失败后,只是从同步副本集合中移除这个副本,并没有像 PacificA 那样主副本主动降级。 而在数据可靠性方面,系统是通过事务日志(《数据持久化:分布式文档的存储流程》已经讲述过 translog 了)和副本来保证数据安全的。
2. 读故障处理
当一个副本无法响应请求的时候,协调节点会将请求转发给同一个副本组的另一个副本进行处理,重复的失败可能导致副本组中所有的副本都被移除,从而没有副本可用。为了快速响应,像 Search、Multi Search、Bulk、Multi Get 这些接口在发生失败时都只会返回部分结果。是的,这里也是倾向于可用性优先的设计。
另外一个需要注意的是,ES 是没有 PacificA 中 Prepare 阶段的。所以,ES 写入的时候,先在主副本中写入数据到 Lucene 中(内存,Index Buffer),然后再写入数据到磁盘。并且默认的情况下,写入的数据 1 秒后可以被读取,如果这个时候转发到从副本的写入请求还没有返回,但客户端的查询又被转发到主副本,那么是有可能读到没有被 commit 的数据的。
四、快速恢复数据
如果所有从副本都下线了(磁盘挂了,数据无法找回),并且没有在其他节点上进行恢复,那么如果主副本也挂了,就可能造成数据丢失。所以,当系统中有部分从副本下线后,系统需要在其他节点中恢复这个副本。
而当系统需要恢复一个副本的时候,需要保证恢复后的数据跟主分片一致。一般数据恢复有两种方式:数据文件全量复制和增量复制。
对于文件全量复制来说,如果数据量很大的时候,耗时会非常长,在将副本分配给新节点的时候就要进行全量复制。而要实现增量复制必须知道从副本与主副本间的差异,不然两个副本全量数据进行比较也是吃不消的。
ES 使用本地检查点和全局检查点来标记从副本与主副本的差异,而这两个检查点的值就是上述提到的 Sequence ID。
- 全局检查点(GlobalCheckpoint),是所有活跃分片历史都已经对齐、持久化成功的序列号,所以小于全局检查点的操作都已经在所有副本上处理完了。当主副本下线后,系统只需要比较新的主副本与其他从副本间最后一个全局检查点之后的操作即可。
- 本地检查点(LocalCheckpoint),代表着本副本中所有小于这个值的操作都已经处理完毕了(写 Lucene 和 Translog 都成功了)。
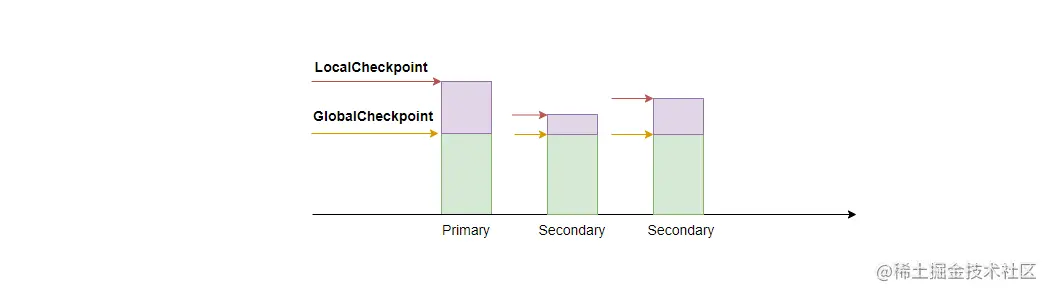
有了全局检查点后,系统就可以实现增量数据复制了,系统只需要比较副本间最后一个全局检查点即可知道差异的数据,并且对其增量复制。由于篇幅的限制,数据恢复的细节内容不在文中的讨论范围内。
但是,如果很不幸系统发生了严重的灾难,集群中只有旧的副本,由于这些旧的副本不在 in-sync-allocation IDs 集合中,所以系统无法自动进行主分片分配,只能进行手工恢复。
这时候该怎么办呢?可以使用 allocate_stale_primary 将一个指定的旧分片分配为主分片! 如下所示:
POST _cluster/reroute{"commands" : [{"allocate_stale_primary" : {"index" : "xxxx","shard" : 2,"node" : "2222","accept_data_loss":true}}]}
但是,需要强调的是:将旧数据的分片分配为主分片,会造成部分数据丢失!如果 in_sync_allocations 中的同步分片只是暂时不可用的话,对于这条命令请谨慎使用。
五、总结
在这一章中,我为你介绍了 ES 的数据副本模型。ES 的数据副本模型在实现上参考了 PacificA 算法,借鉴了其中部分的思想,所以我们还简单介绍了 PacificA 中的基本术语在 ES 中的实现。
然后,我们对主分片分配进行了讲解,ES 用 in_sync_allocations 来记录同步副本的 Alloction ID,并且分配主分片的时候,只有在 in_sync_allocations 中的副本才有可能被选为主分片。
为了标识每个写入操作,ES 引入了 Sequence ID 的概念,Sequence ID 由 Primary Term 和 Sequence Number 组成。在比较两个操作的大小时,可以先比较 Primary Term,如果相等,再比较 Sequence Number 大小。Sequence ID 的引入使得系统可以丢弃一些过期的操作,也可以为数据恢复提供加速的依据。
默认的情况下,ES 的数据写入只需要保证主副本写入了即可,ES 在写上选择的是可用性优先,而并不是像 PacificA 协议那样的强一致性。而数据读取方面,ES 可能会读取到没有 commit 的数据,所以 ES 的数据读取可能产生不一致的情况。
在数据恢复方面,系统可以借助 GlobalCheckpoint 和 LocalCheckpoint 来加速数据恢复的过程。如果集群中只有旧的副本可用,那么可以使用 allocate_stale_primary 将一个指定的旧分片分配为主分片,但会造成数据丢失,慎用!
通过 《数据不丢失的奥秘》上、下两篇文章的学习,相信对于本文开头提出的几个问题,你已经找到答案了。
- 多个节点上的主副本和从副本到底要怎么同步数据才能保证数据不会丢失呢?
答:数据写入时,先写主副本,然后再写从副本,等所有从副本都写入成功了,主副本 commit 数据,最后再通知各个从副本 commit 数据。
- 数据恢复时需要复制整个主副本的数据吗?
答:如果节点上有对应分片的数据,可以根据全局检查点之后的数据来进行恢复;如果节点上没有对应分片的数据,只能进行全量数据的复制。
- 主副本下线了,数据会丢失吗?
答:这个看情况!如果系统中没有副本了,主副本的数据没法恢复,那么所有数据丢失。如果有陈旧的副本,那么恢复后会造成部分数据丢失。如果有同步的副本,则不会丢失数据。
- 在从副本读取数据,总能读到最新的数据吗?数据是如何保证一致性的?
答:由于主副本写入成功后,其数据可能会在 commit 前被读取,从而可能会导致在主副本和从副本中读取的数据不一致的情况出现,所以 ES 的数据一致性是弱一致性的。
- 多个副本存在的情况下,是不是要全部副本都写成功才会返回给客户端?
答:ES 默认只需要主副本写入成功即可。如果从副本写入失败,主副本节点会通知 Master 把这个从副本从 in_sync_allocations 中移除。
通过 《全文搜索背后的支撑:倒排索引的实现》《数据持久化:分布式文档的存储流程》《数据不丢失的奥秘》 这几篇文章,我相信你对 ES 的数据模型有了进一步的认识,对于 ES 这个复杂的系统来说,这几篇文章的内容只是冰山一角,很多的细节没法深入,但希望这几篇文章的内容对你后面进行源码阅读的时候有所帮助!
