在介绍聚合 API 的时候,Terms Aggregations 聚合返回的结果中有两个字段我们并没有详细介绍,它们是:doc_count_error_upper_bound 和 sum_other_doc_count。
这两个字段是对聚合结果的评估,其含义是:
- doc_count_error_upper_bound:没有在本次聚合返回的分组中,包含文档数的可能最大值的和。如果是 0,说明聚合结果是准确的。
- sum_other_doc_count:除了返回结果中的 terms 外,其他没有返回的 terms 的文档数量之和。
上述对于这两个字段的描述和解析是很难理解的,但没关系,我们今天就来寻根问题,看看为 Terms 何聚合的结果不一定准确,上述的这两字段到底是什么含义,有什么办法可以解决聚合结果不准确的问题。
一、Terms 聚合的结果不准确的原因
需要注意的是,我们说的聚合结果不准确是发生在分组聚合的 Terms 聚合 API 中的。

如上图,我们知道 ES 把索引的数据分配到一个或多个主分片上进行存储,而这是导致 Terms 聚合结果可能不准确的其中一个元凶。
我们先来搞懂聚合操作在多分片索引下的工作原理,下面 Max 聚合操作的执行流程:

如上图,Max 聚合请求先达到协调节点,协调节点会将请求转发到所有保存主分片(或者主分片的副本)的节点进行处理,然后每个节点在本地分片中求出数据的最大值返回给协调节点,协调节点在各个分片的最大值中得出最大值返回给客户端。
上述 Max 聚合的工作原理是不会产生聚合结果不准确的问题的,下面再来看看 Terms 聚合的执行流程:
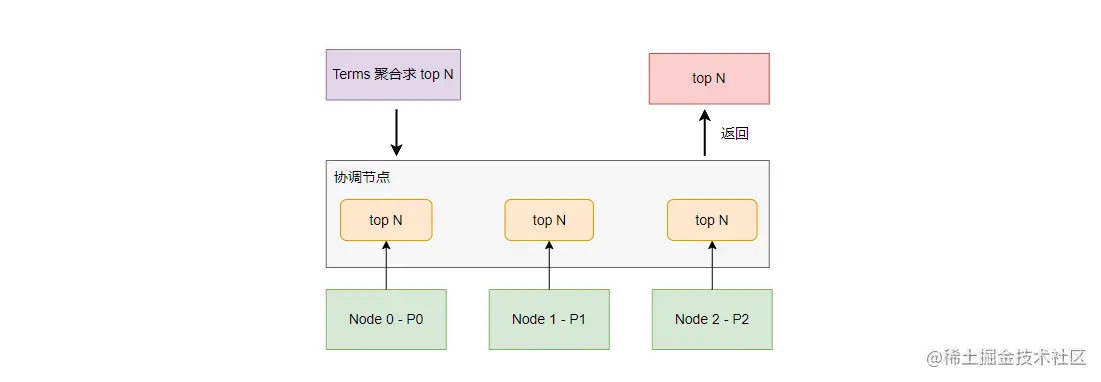
如上图,Terms 聚合的执行流程与 Max 聚合没有本质上的区别,这里不再赘述。
需要注意的是,每个分片返回给协调节点的数据是一个数组(top n),这与 Max 聚合只返回 Max 值不同。而这个不同之处就是导致 Terms 聚合结果可能不准确的元凶之二!协调节点会从每个分片的 top n 数据中最终排序出 top n,但每个分片的 top n 并不一定是全量数据的 top n。
为了更好地理解 “每个分片的 top n 并不一定是全量数据的 top n” 这句话,我们通过一个例子来讲解:
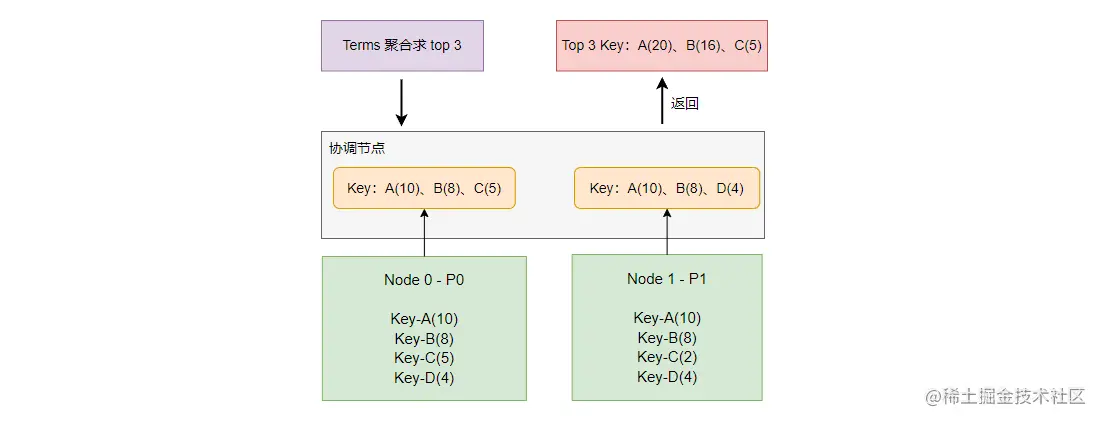
如上图,对于总量数据来说,数据排序为:A(20)、B(16)、D(8)、C(7),top 3 为:A(20)、B(16)、D(8) 。而聚合得出的错误 top 3 为:A(20)、B(16)、C(5) 。因为在 P0 分片的 top 3 丢掉了 D(4), 而 P1 分片中返回 top 3 中丢掉了 C(2),而丢掉的这部分数据恰好会影响最终的结果。
二、doc_count_error_upper_bound 和 sum_other_doc_count 的解析
上面我们通过一个例子介绍了 Terms 聚合产生不准确聚合结果的情况,那在这个例子中 doc_count_error_upper_bound 和 sum_other_doc_count 又是如何计算的呢?它们的计算过程如下:
1. doc_count_error_upper_bound
在 P0 中数据返回了 A(10)、B(8)、C(5) ,因为返回的分组里面数据最小的是 C 分组的值 5,所以遗漏的可能的最大值就是 5,注意这里是可能的最大值,不是实际的最大值。同理, P1 中的可能最大值为 4。所以 doc_count_error_upper_bound = 5 + 4 = 9。
2. sum_other_doc_count
sum_other_doc_count 计算就比较好理解了,将文档总数减去返回的统计总数。所以 sum_other_doc_count = 51 - 41 = 10。
三、聚合结果不准确的解决方案
在解了 Terms 聚合的整个原理后,我们得出了造成 Terms 聚合结果不准确的原因有以下两个:
- 数据进行了分片存储
- 每个分片返回 top n,并且从所有分片的 top n 中排序后最终选出 top n。而每个分片的 top n 并不一定是全量数据的 top n。
那要解决这个问题也很好办,对症下药就可以了:
1. 数据不要分片存储
如果数据都在一个分片上,协调节点获取到的 top n 一定就是全量数据的 top n 了。要设置索引主分片的个数可以在创建 Mapping 的时候用 number_of_shards 指定:
PUT my_index{......"settings": {"number_of_shards": 1 # 指定了 1 个主分片}}
但是这种方案就一定程度上牺牲了 ES 的分布式特性,所以这种方式只能在数据规模小的时候使用。
2. 不要返回 ton n 数据,而是返回 top 1
例如 Max 聚合就不会产生这种问,但这样很多需求无法实现,也不现实。
3. 每个分片返回足够多的分组
例如查询结果要返回 top 3,我们在每个分片上返回 top 20,或者每个分片返回全量的分组数据。可以使用 shard_size 参数来指定每个分片返回的分组数量:
GET /my_index/_search{"aggs": {"products": {"terms": {"field": "product","size": 5,"shard_size": 10}}}}
如上示例,size 为 5,所以我们聚合结果需要返回 top 5,但 shard_size 设置为10,这样每个分片将返回 top 10 给协调节点,最后协调节点排序出最终的 top 5。
shard_size 的默认值为 (size * 1.5 + 10),需要注意的是,shard_size 不能比 size 的值小,否则会使用 size 的值取代。
使用 shard_size 参数只能提升准确率,并且因为增加了运算量,所以会降低效率。shard_size 参数并不能完全解决问题,要保证结果 100% 准确,必须返回全量分组数据才行。
综合上面的解决方案,它们或多或少都有些缺点,但是回头来细想到底是为何呢?其实这里面涉及了 数据量、实时性、准确度这三者的权衡关系。
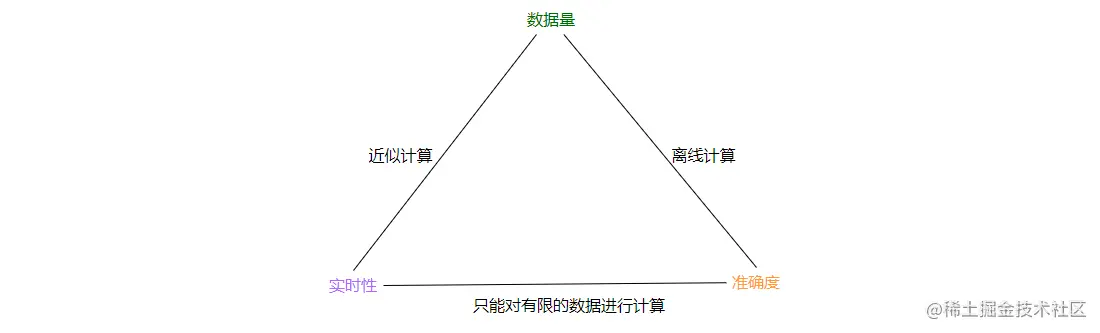
如上图,当数据量巨大的时候,如果想要得到准确结果,需要进行离线计算,这时候就牺牲了实时性。而数据量巨大的时候,想要保证实时性,只能进行近似计算了,通常会利用一些算法和机制快速得到想要的结果。
而要保证实时性和准确度的话,只能对有限的数据进行计算。那我给更多的资源不行吗?理论上是可以的,但很遗憾,资源只能决定有限数据集合的上限,并且资源要钱,控制成本是很重要的,这是重点!
四、总结
今天为你介绍了聚合分析的原理,并且分析了 Terms 聚合的结果不准确的原因,和对应解决方案。
造成 Terms 聚合的结果不准确的原因主要有两个:
- 数据进行了分片存储
- 每个分片的 top n 并不一定是全量数据的 top n
对于第一个原因,可以使用 number_of_shards 参数设置索引的主分片为 1,由于只有一个主分片,所以聚合的结果一定是准确的,但是这个方案只能在数据规模小的时候使用。
对于第二个原因,在聚合查询的时候使用 shard_size 参数来提升准确率,但并不能保证 100% 准确。
最后我们讨论了如何在数据量、实时性、准确度这三者间的权衡,它们间形成了三角关系,无法同时都满足,最多只能同时满足两个。
