Get 与 Multi Get API 提供通过文档 id 获取文档内容的功能,我们已经在 《管理你的数据:文档的基础操作》中已经介绍过其使用示例了,这里不再赘述。
在 《数据持久化:分布式文档的存储流程》 中我们知道,ES 是一个准实时系统,数据通过 refresh 操作后才能被检索,是的这里说的是检索,不是获取操作。那如果我们写入数据后马上使用 Get API 获取数据可以获取到吗?
另外,我们在 《人多好办事:分布式文档搜索机制》提到过路由算法,系统是如何确定该到哪个 Shard 上找文档内容的呢?
ok,今天我们就带着这两个疑问来跟踪 Get 与 Multi Get 的实现,找找答案。 但在跟踪 Get 源码之前我们先来明确几个事情,这样对我们以后自己查看各个 API 源码的时候会很有帮助。
1. REST 与 transport 的区别
我们在配置 ES 的时候会配置两个 HTTP 监听的端口:
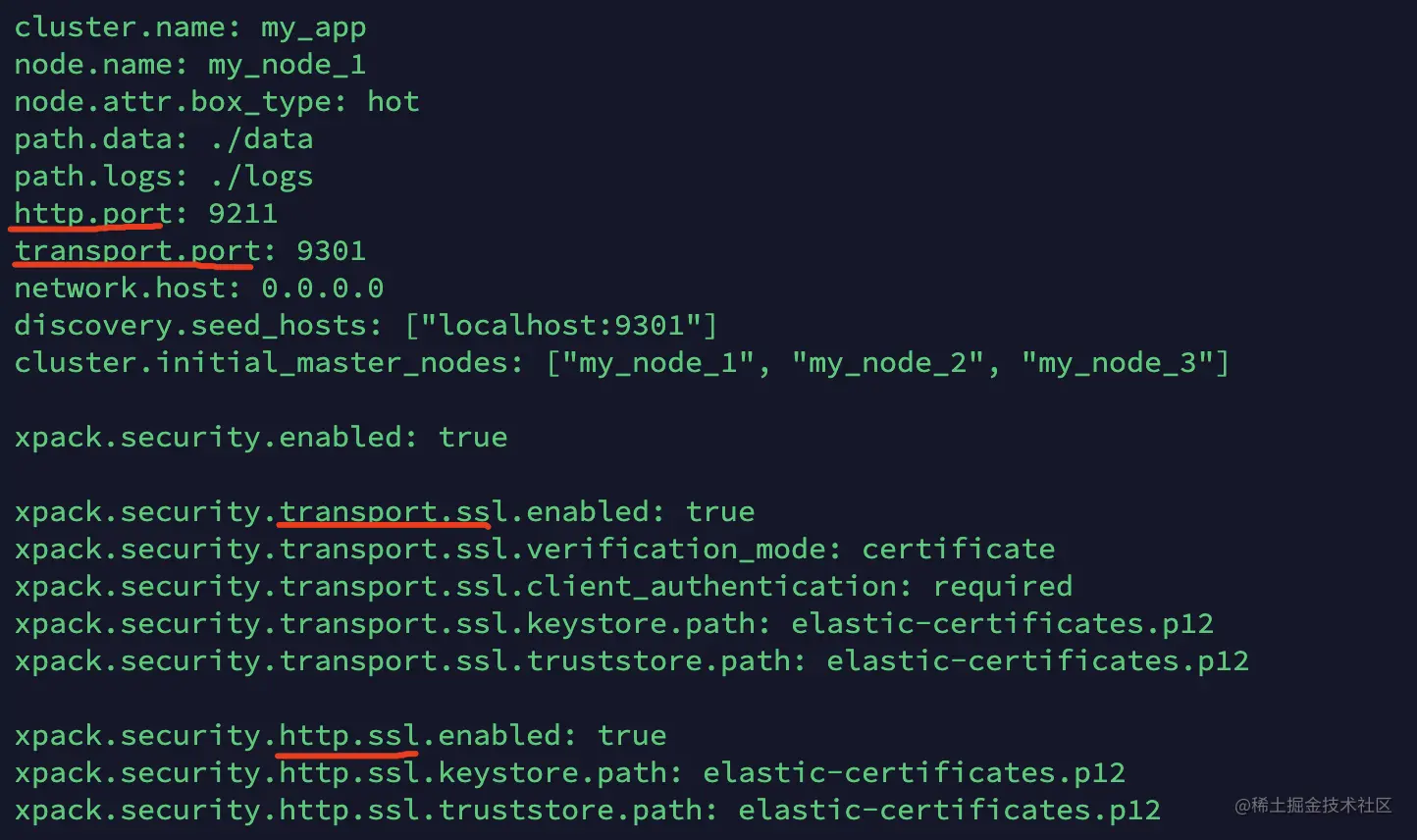
如上图,监听的 http.port 是用来接收客户端请求的,而监听 transport.port 是用来与集群中其他节点通信用的。此处对应的两个服务是我们上一章提到过的:
- HttpServerTransport,提供 REST 接口服务。
- TransportService,负责节点间数据同步。
2. 用于表示 REST 请求的 Action
例如 Get 请求的 Action 为 RestGetAction,其在 org.elasticsearch.rest.action.document 包中。这部分的 Action 继承了 BaseRestHandler 这个抽象类,并且实现了 RestHandler 接口,这个很重要要记住,后面我们会用到。
3. 用于处理请求的 Action 类
如果说实现了 RestHandler 接口的类它们代表着 REST 请求,那么真正处理这些请求内容的类则为形如 Transport*Action 的类,例如处理 Get 请求的类为 TransportGetAction,其在 org.elasticsearch.action.get 包中。Transport*Action 类继承了 TransportAction,最终处理请求的方法为 doExecute()。
4. NodeClient
NodeClient 用于执行本地的 actions 的,并且各个节点间的交互是通过 NodeClient 来进行的。
废话不多讲,下面就正式来看看 Get 与 Multi Get 的源码实现吧!
一、REST 请求的处理流程
我们在《源码阅读:节点启动过程》中提到一个疑问:一个 REST 请求是如何被处理的呢?今天我们在跟踪 Get 源码实现的同时顺便来解答一下这个问题。
1. 注册 RestHandler
在节点初始化的第三阶段会进行 HTTP Handler 初始化(第三阶段第 11 步),在初始化的过程中会注册一堆 RestHandler:
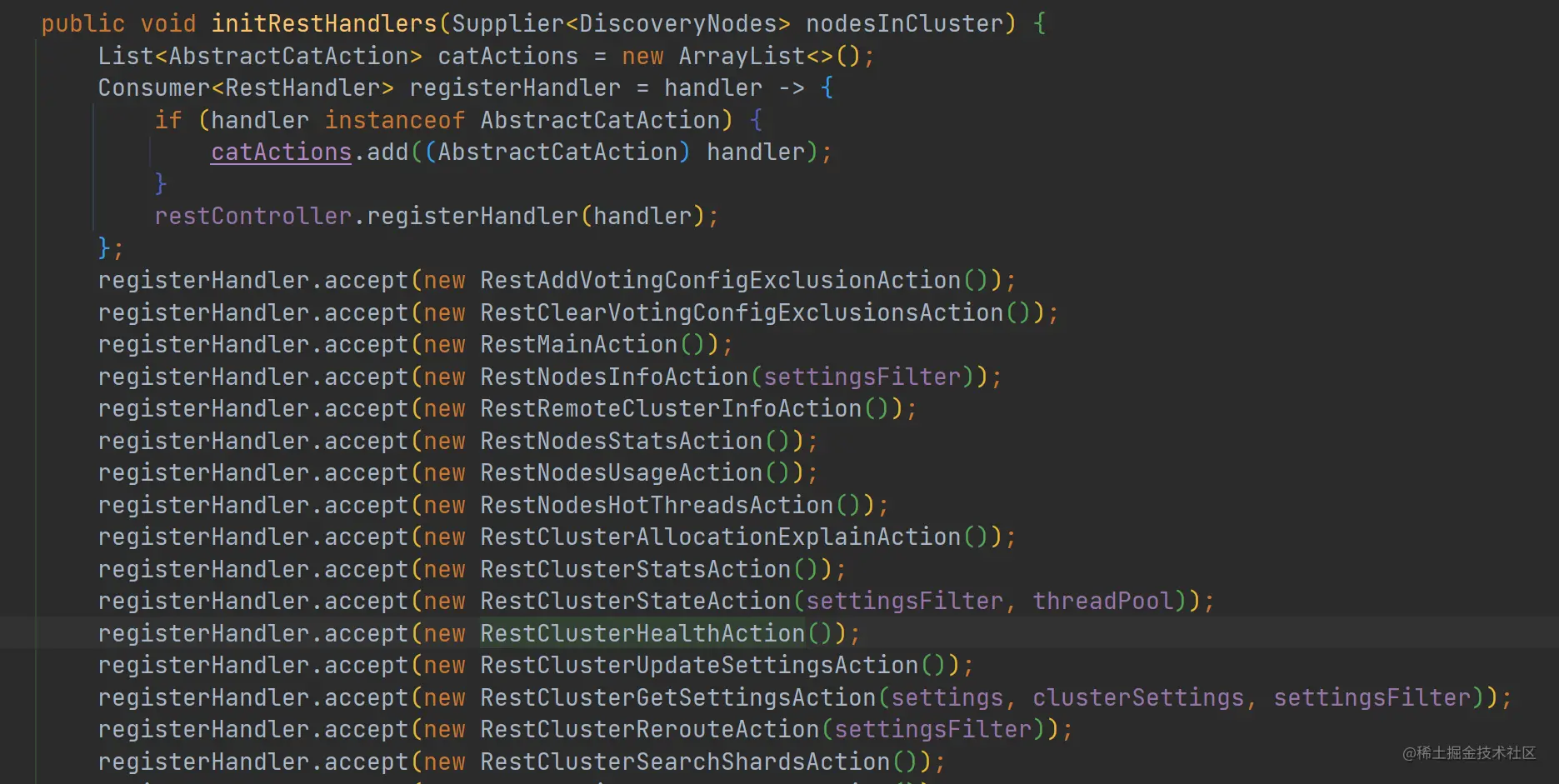
如上代码,在 initRestHandlers 方法中注册了一堆 RestHandler 到 RestController 中,其中就包括代表 Get 的 RestGetAction。这些已经注册了的 Action 在 RestController 中是如何被处理的呢?下面来跟踪一下 RestController 的实现。
2. 获取处理请求的 RestHandler
RestController 实现了 HttpServerTransport.Dispatcher 接口,其中 HttpServerTransport 使用的工作线程为:http_server_worker,其源码如下:
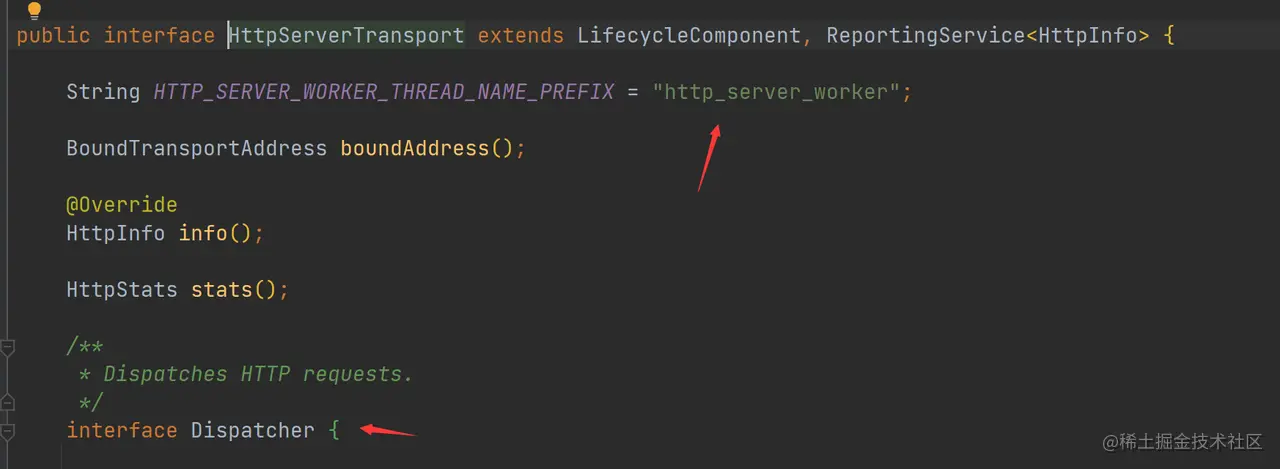
RestController 中的函数不多,处理请求的函数入口为 dispatchRequest,最终调用 tryAllHandlers 函数:
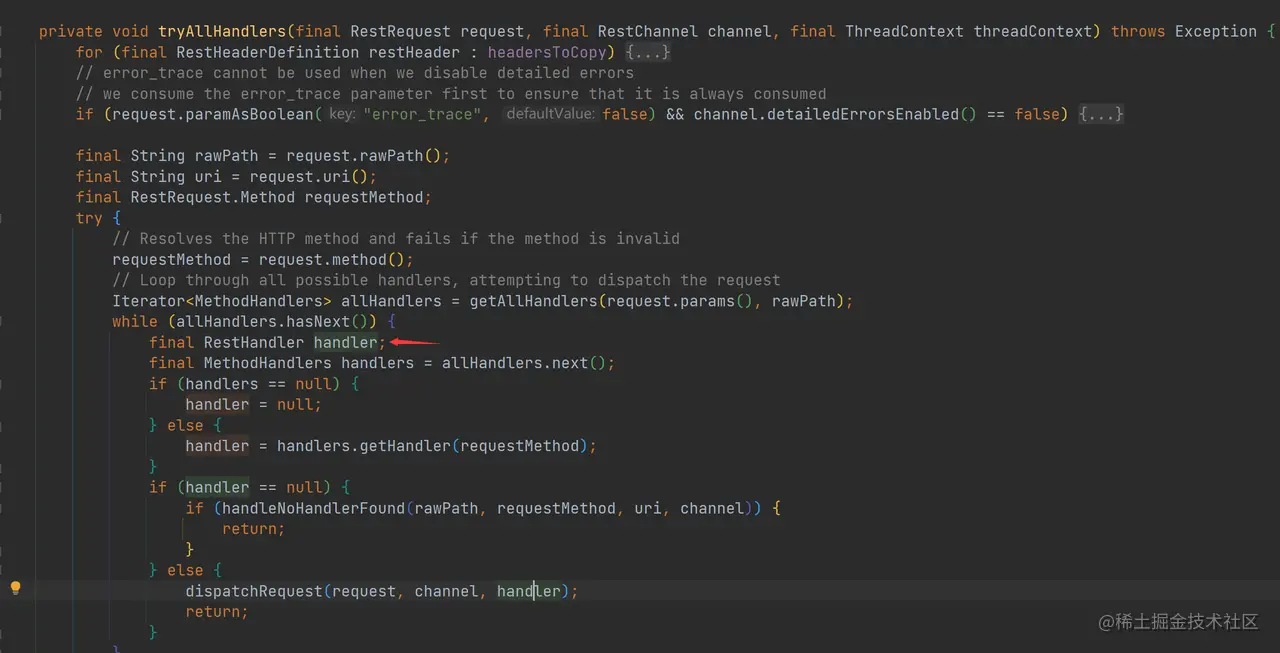
如上图,在 tryAllHandlers 中循环查找出可以处理请求的 RestHandler,然后再调用私有的 dispatchRequest 函数继续理请求:
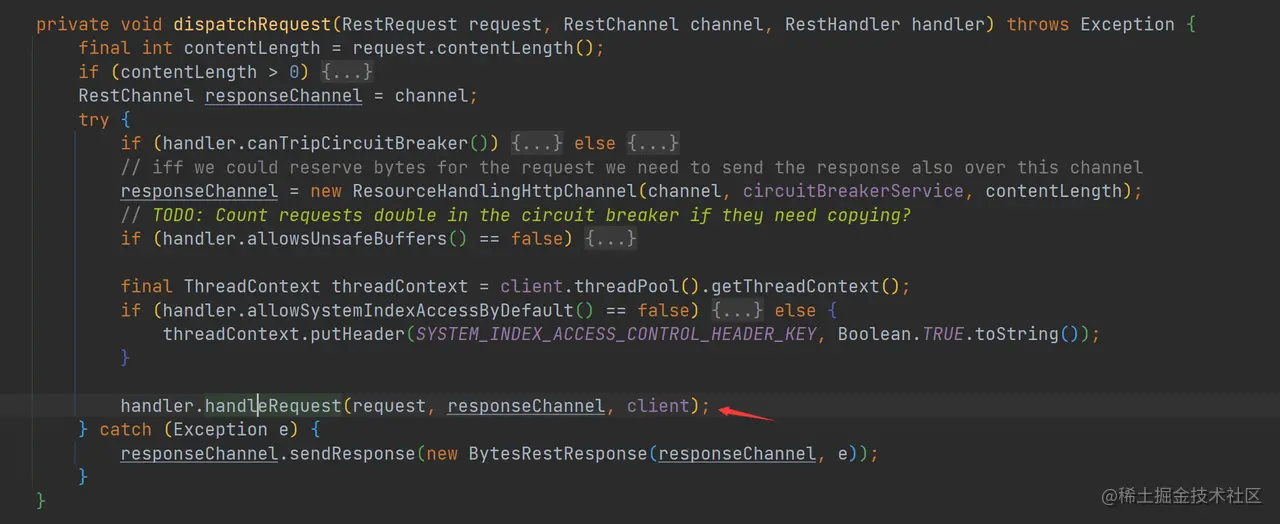
如上代码,handler.handleRequest 方法实际上是 BaseRestHandler.handleRequest 方法,下面来看看 handleRequest 方法都干了些啥:
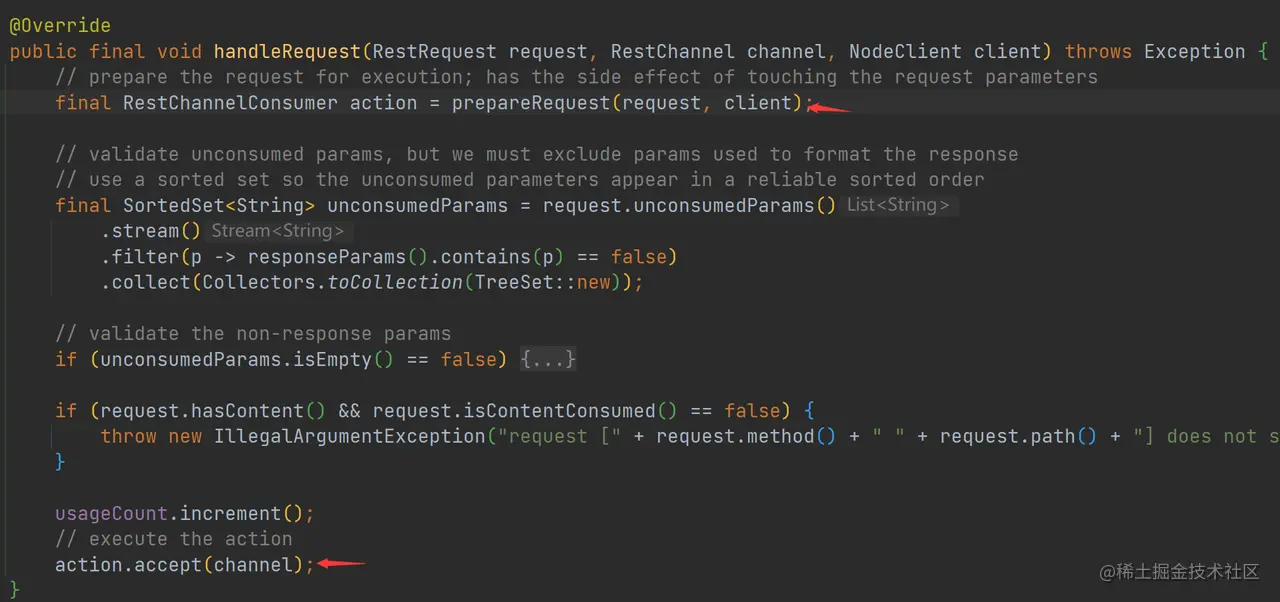
如上代码,handleRequest 首先调用了 prepareRequest,对请求参数进行解析,并且返回了RestChannelConsumer,一个 FunctionalInterface,最后执行了这个返回的 action。
3. 准备请求,处理请求参数等
下面来看看 RestGetAction 中 prepareRequest 方法的实现:
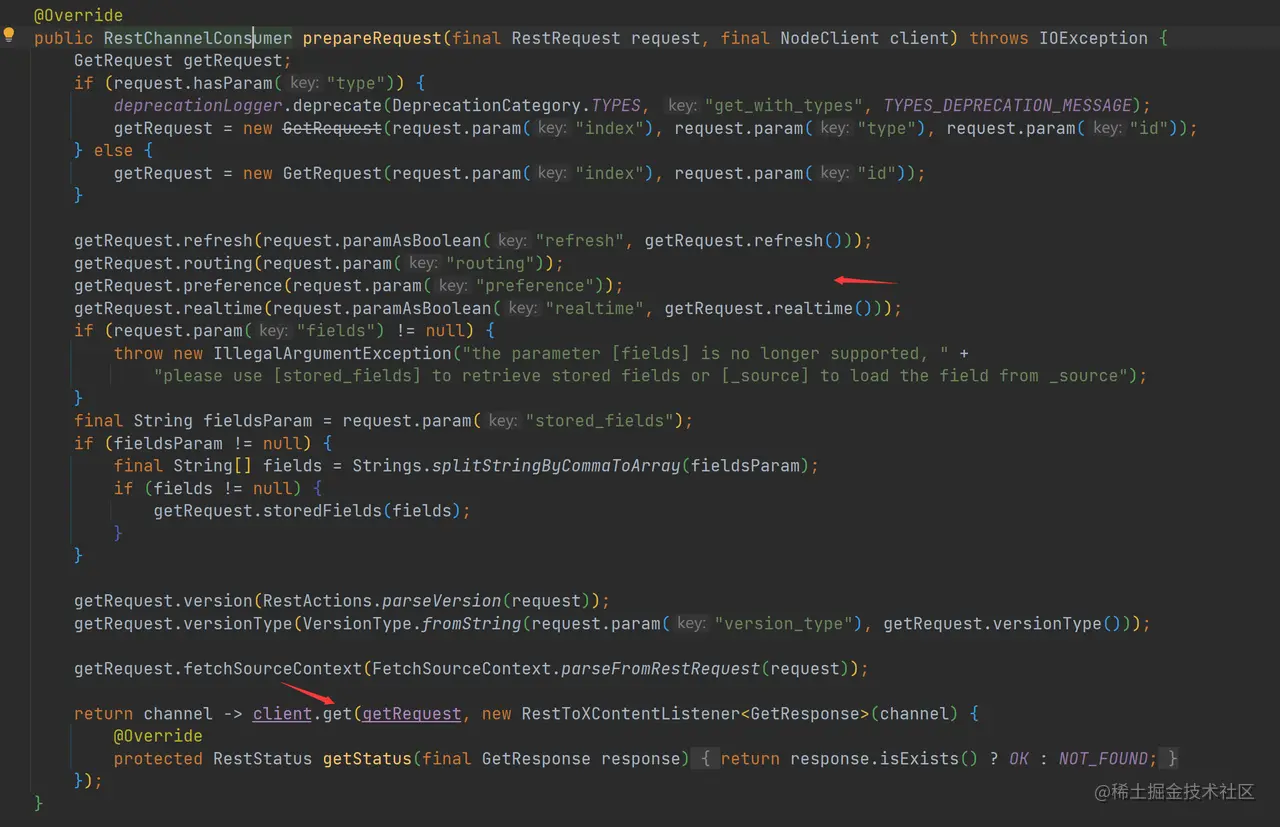
如上代码,RestGetAction.prepareRequest 解析了其接口接受的参数,如 refresh、routing、realtime 等,最后返回了 FunctionalInterface。
4. 获取处理请求的 TransportAction 实例
这个 FunctionalInterface 会调用 client.get 方法,这个方法实际是 NodeClient.get 方法:

最终 get 方法里的 execute 方法会调用 NodeClient 类的 doExecute 方法,而这个 doExecute 最终会调用 NodeClient.executeLocally 方法:
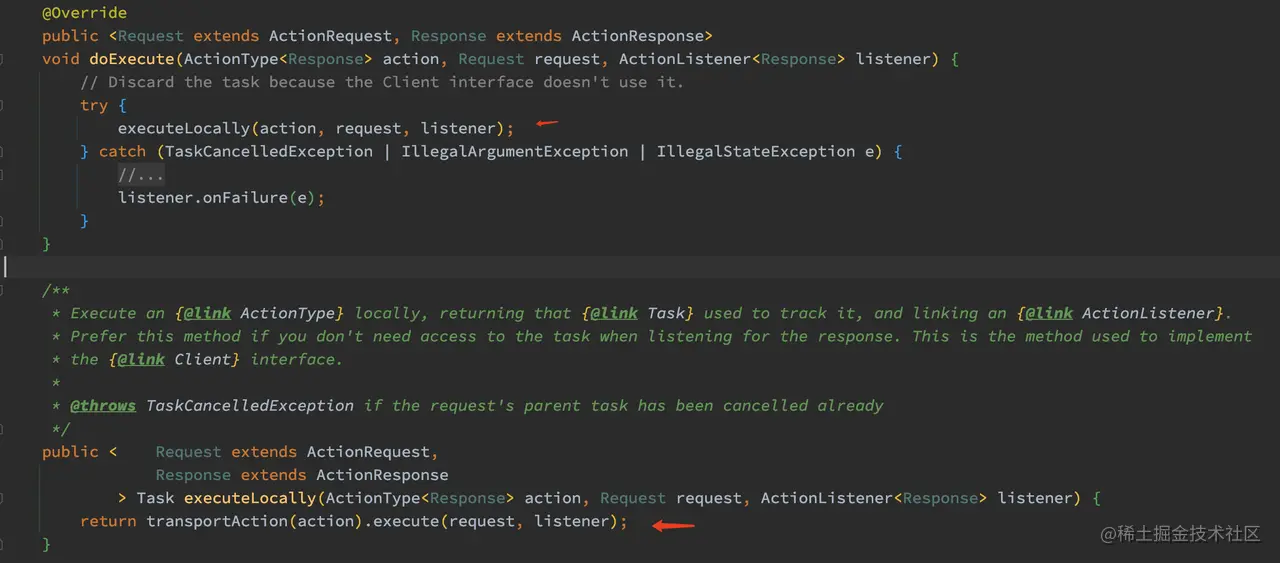
如上代码,transportAction 是这里的重点,其通过 ActionType 在 actions 这个 Map 里获取出对应的 TransportAction 实例,然后执行 TransportAction 的 execute 方法。
5. 调用 TransportAction 的 execute 方法
TransportAction 类中 execute 方法最终会调用其 doExecute 方法来处理对应的请求:
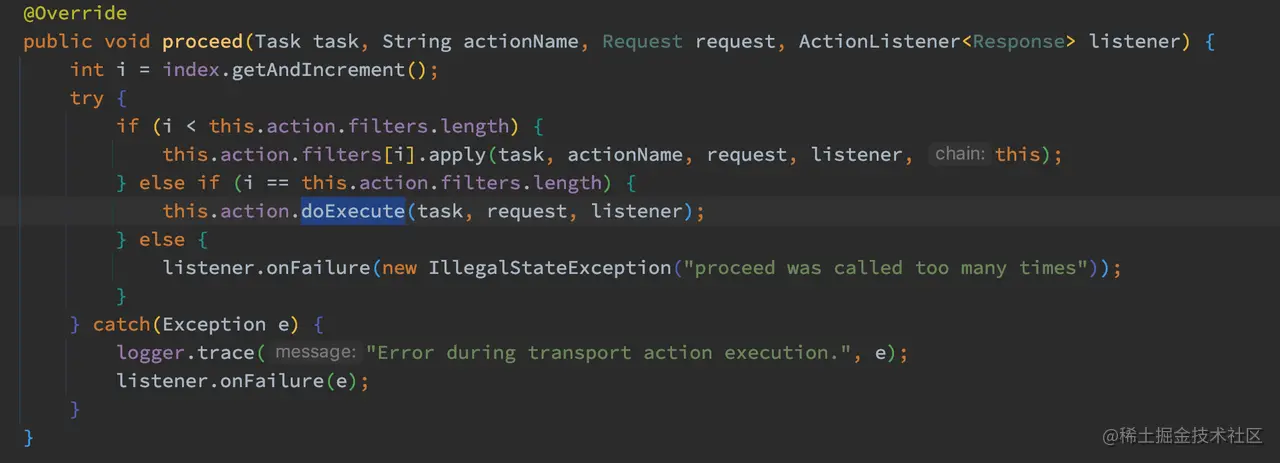
Ok,到此一个 REST 请求的整个流转流程我们已经很清楚了,下面来看看这个 Get 请求是如何被执行的。
二、GET 源码跟踪
在阅读源码前我们先来看看 Get 的基本流程。如果你已经阅读过《人多好办事:分布式文档搜索机制》的话这个流程应该是非常熟悉了。
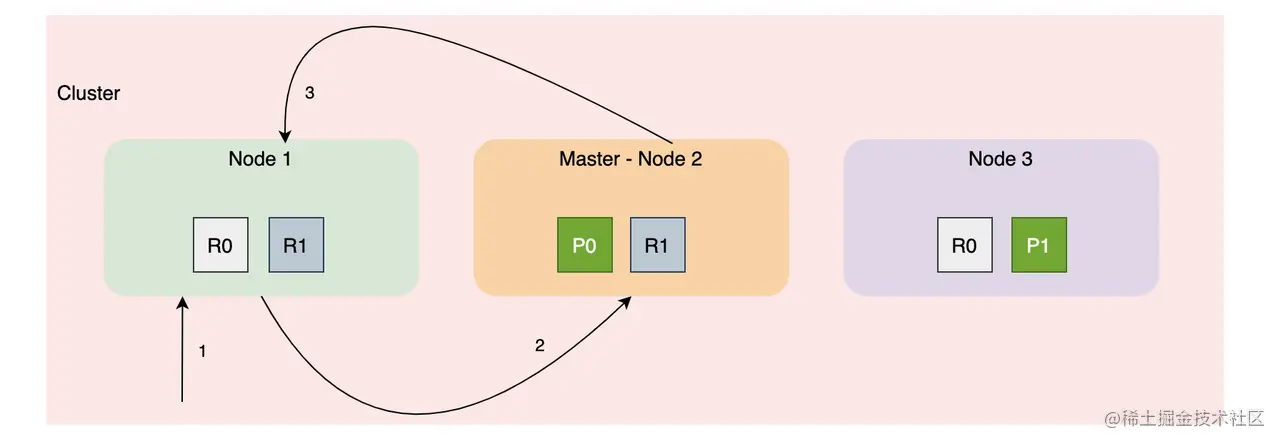 如上图,Get 请求的整体流程如下:
如上图,Get 请求的整体流程如下:
- Get 请求到了协调节点(图中的 Node 1)
- 协调节点根据文档的 id 和 routing key 获取到文档所在的 Shard 和对应的节点,图中的 Node 2。然后转发请求到 Node 2 中获取文档信息。
- 在数据节点 Node 2 中获取完文档信息后,返回给协调节点,协调节点负责把最终的结果返回给客户端。
所以下面处理 Get 请求的源码部分,我将分别从协调节点和数据节点的角度来描述。
1. 协调节点
一个 REST 请求最终会在对应的 Transport*Action 的类中处理,所以真正处理 RestGetAction 请求的类应该是 org.elasticsearch.action.get.TransportGetAction 类。
TransportGetAction 类继承了 TransportSingleShardAction,而 TransportSingleShardAction 继承 TransportAction 抽象类。TransportSingleShardAction 可以处理单个分片(主分片或者副分片)上的读取请求。读取请求会被转发到目标节点中进行处理,如果请求执行失败,会尝试转发到其他候选分片中进行处理。
内容路由
通过跟踪发现正真正处理 Get 请求的函数是在 TransportSingleShardAction 的 doExecute:

如上代码,doExecute 方法中创建了 AsyncSingleAction 实例,并且调用其 start 方法。
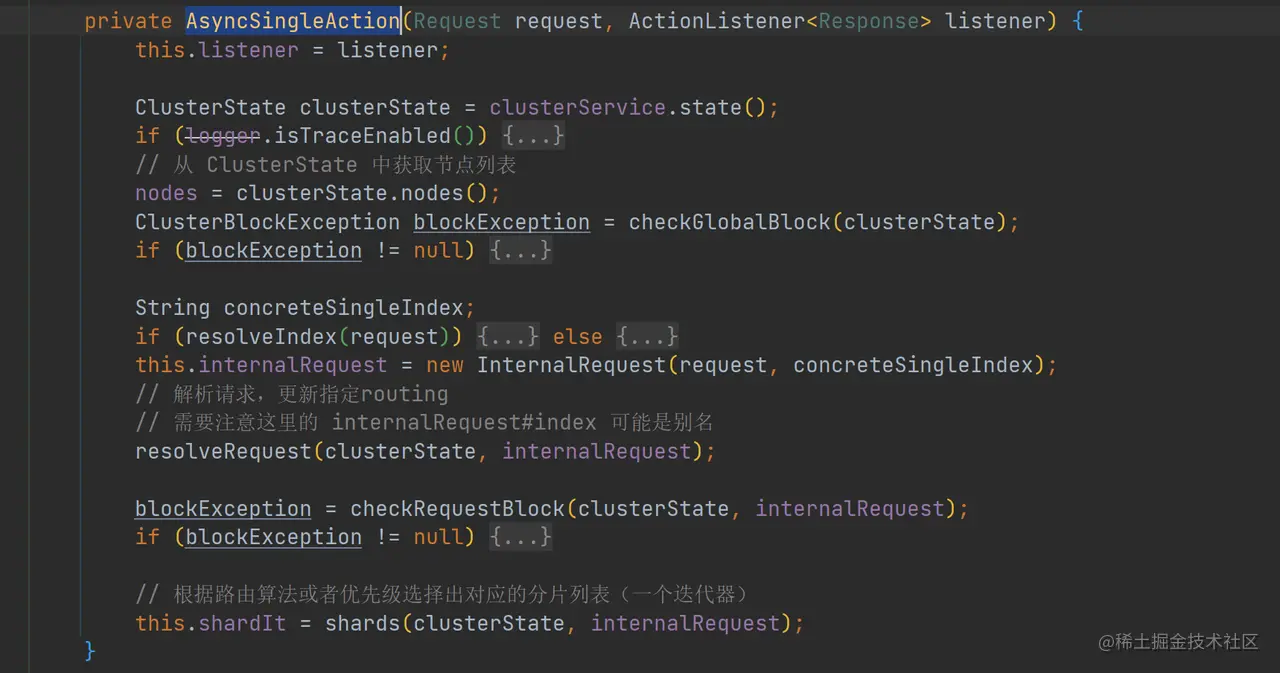
如上代码,在 AsyncSingleAction 的构造函数中,主要完成了一下几件事情:
- 获取了集群状态类,并且从中得到了节点列表的信息。
- 检查是否全局读阻塞,如果是读阻塞则抛出异常。
- 解析请求,更新指定的 routing。
- 再次检查请求是否读阻塞,如果是读阻塞则抛出异常。
- 根据路由算法或者优先级参数(preference)选择出对应的分片列表(一个迭代器)
下面主要来看看如何通过路由算法得到 Shard 列表的,shards 方法具体的实现是在
TransportGetAction 的 shards 中,最终调用了 OperationRouting 类的 getShards 方法:  如上代码,getShards 方法中主要调用了 shards 来获取 shardId,然后再根据计算出来的 shardId 从集群元数据的 routing table 中获取存储此文档的 Shard 路由表信息。最后再调用 preferenceActiveShardIterator 方法根据 preference(优先级) 参数是否存在分别获取对应的 Shard 列表。
如上代码,getShards 方法中主要调用了 shards 来获取 shardId,然后再根据计算出来的 shardId 从集群元数据的 routing table 中获取存储此文档的 Shard 路由表信息。最后再调用 preferenceActiveShardIterator 方法根据 preference(优先级) 参数是否存在分别获取对应的 Shard 列表。
下面来看看 shardId 计算过程:
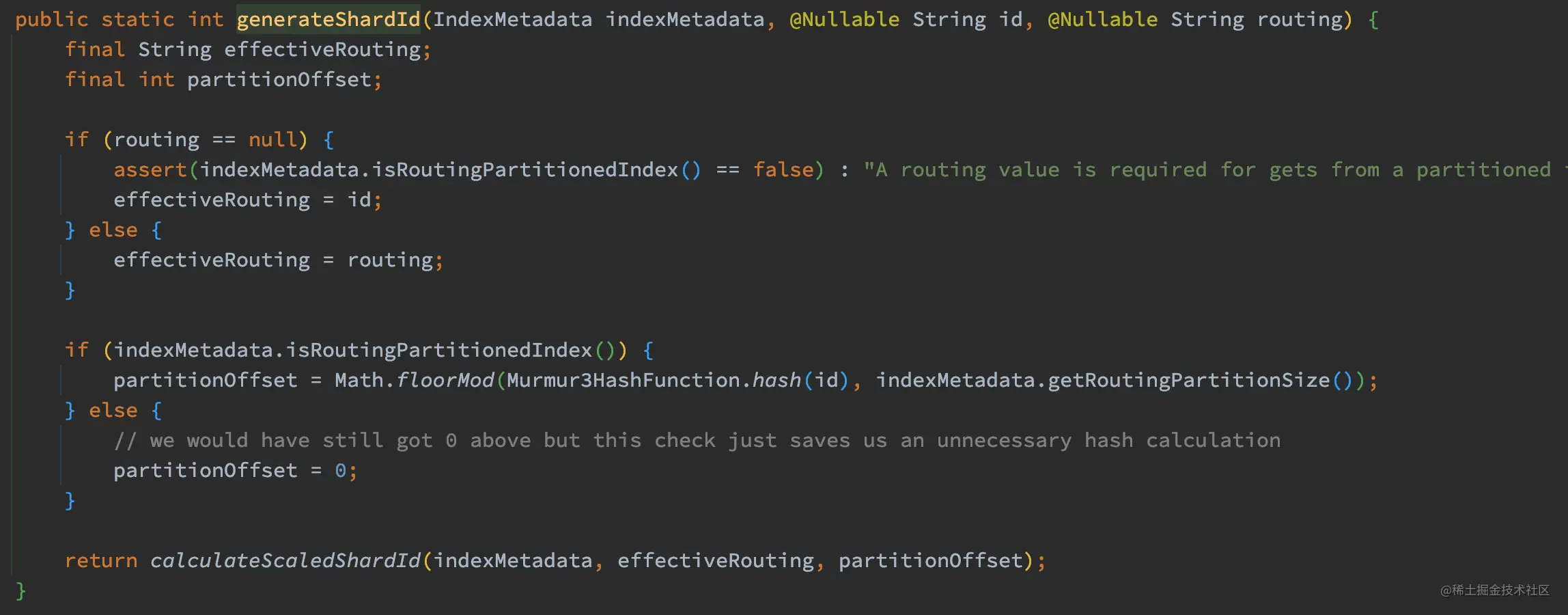
如上代码,当 routing 请求参数没有设置的时候,effectiveRouting 的值为文档 id,否则为 routing。
这里还有一个 partitionOffset 变量需要注意,当我们写入文档的时候,如果使用 ES 的随机 id 和 hash 算法的话,可以保证文档被均匀分配到各个主分片中,避免出现数据倾斜。但如果我们使用自定义的文档 id 或者 routing key 的时候,是没法保证的。这个时候可以使用 index.routing_partition_size 配置来降低出现数据倾斜的风险,其值越大,数据分布就越均匀,更多关于 routing_partition_size 配置信息请参考官方文档。
# index.routing_partition_size 取值应具有大于 1 且小于 index.number_of_shards 的值(请参考文档)partitionOffset = hash(id) % routing_partition_size
最后,shardId 由 calculateScaledShardId 方法计算得出:

如上代码,最终整理成公式如下:
# partitionOffset = 0 的时候# effectiveRouting 为文档id 或者 routing keyshardId = (hash(effectiveRouting) % num_primary_shards) / RoutingFactor# partitionOffset = hash(id) % routing_partition_sizeshardId = ((hash(effectiveRouting) + partitionOffset) % num_primary_shards) / RoutingFactor
所以,实际上 ES 是通过文档 Id 或者 routing key 计算出到底要到哪个Shard 上获取数据的。
这里提出两个个疑问:
- 为什么增加了 partitionOffset 可以降低出现数据倾斜的风险呢?
- partitionOffset 改变了是否会改变计算出的 shardId,或者说
routing_partition_size改变后会改变 shardId 吗?
请求转发
在协调节点,如果计算出来的目标节点为本节点则直接读取数据,否则转发请求到对应的节点上进行处理。
调用 AsyncSingleAction 实例的 start 方法开始处理请求转发:
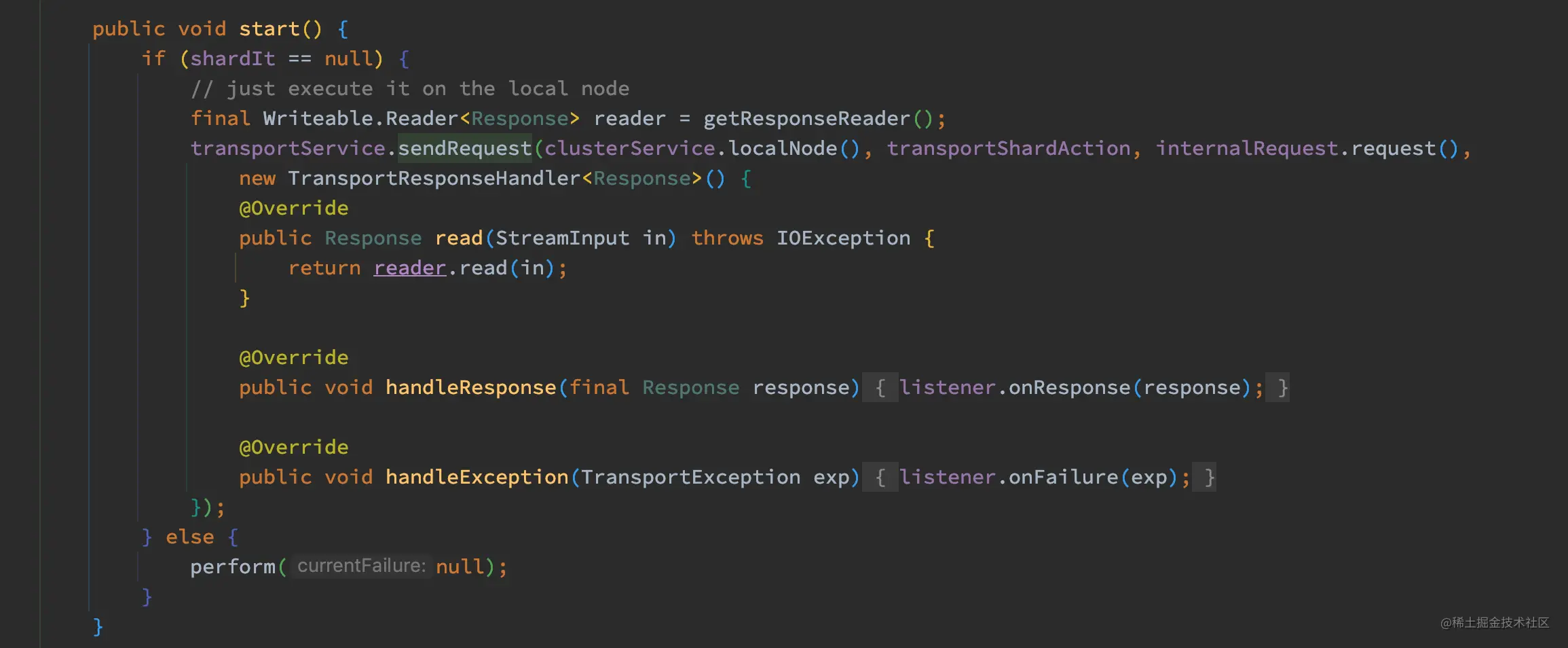
如上代码,如果 shardIt 为空的时候,调用 transportService.sendRequest,并且此时的 node 为 localNode。而当找到 shardIt 的时候,则调用 perform 方法:
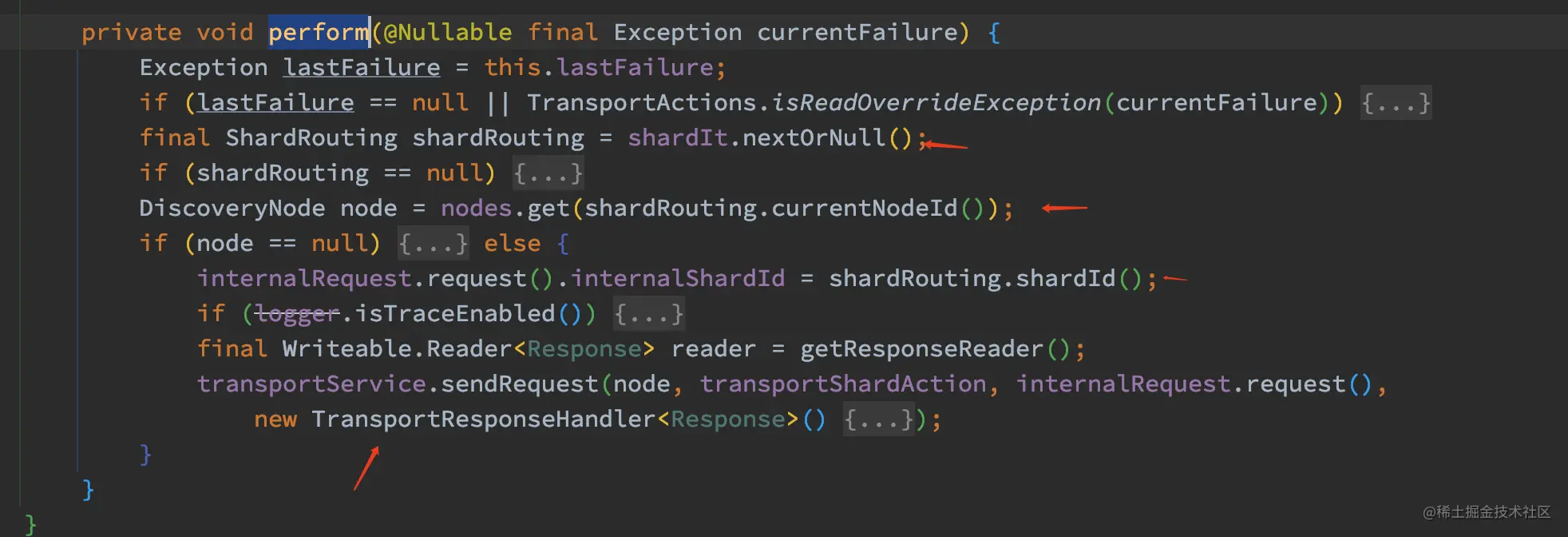
其主要流程为:
- 首先从 shardIt 获取 ShardRouting,并且判断其是否为空。
- 根据 ShardRouting 的当前 node id 获取 DiscoveryNode,并且判断其是否为空。
- 用 shardRouting.shardId 设置 internalShardId。
- 调用 transportService.sendRequest,此时的 node 为计算出来的 DiscoveryNode。
综上所述,最终不管哪种情况都会调用 transportService.sendRequest 方法,并且通过代码发现它们都注册了一个 TransportResponseHandler 来处理返回的内容。下面我们来跟踪一下 transportService.sendRequest 个方法的实现。
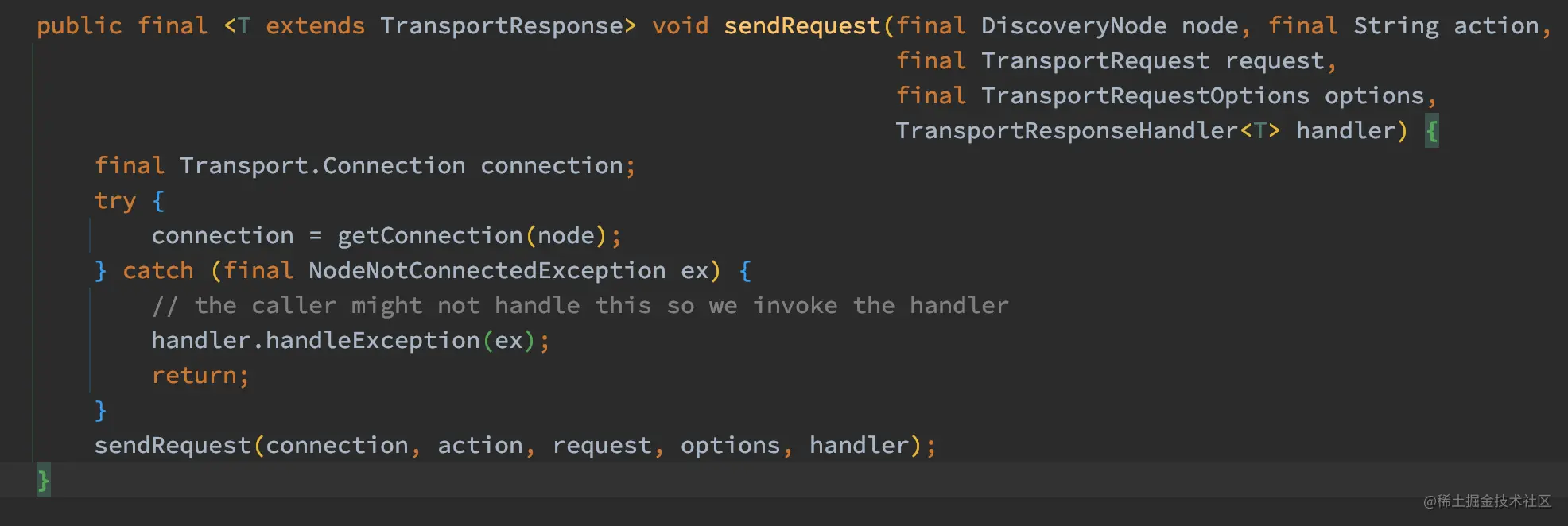
如上代码,getConnection 方法会根据节点是否为本地的区别返回一个 Connection 实例:
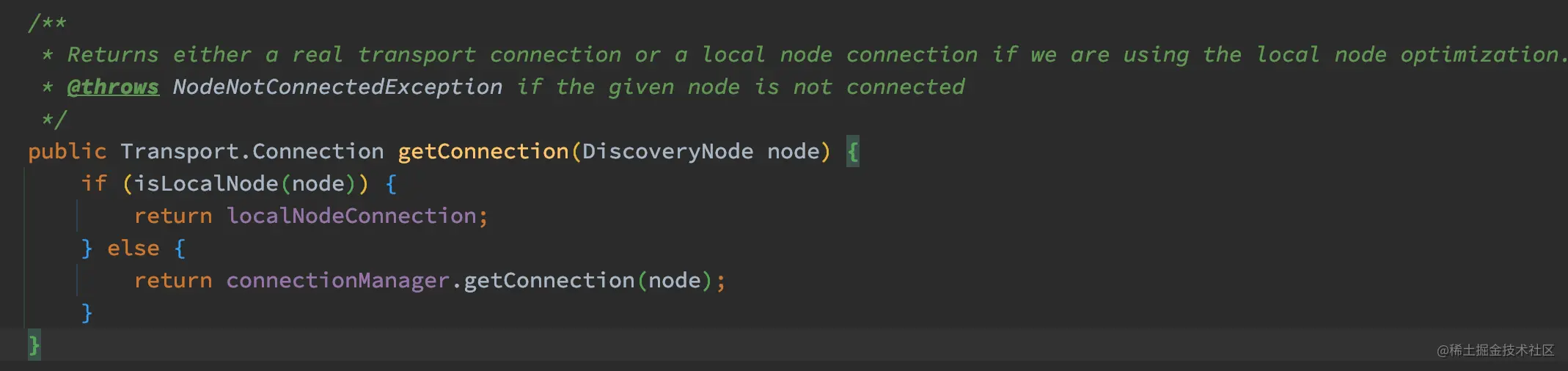
如果为本地节点返回 localNodeConnection,否则在 connectionManager 中获取对应节点的 Connection 实例。
sendRequest 最终调用了 asyncSender.sendRequest:
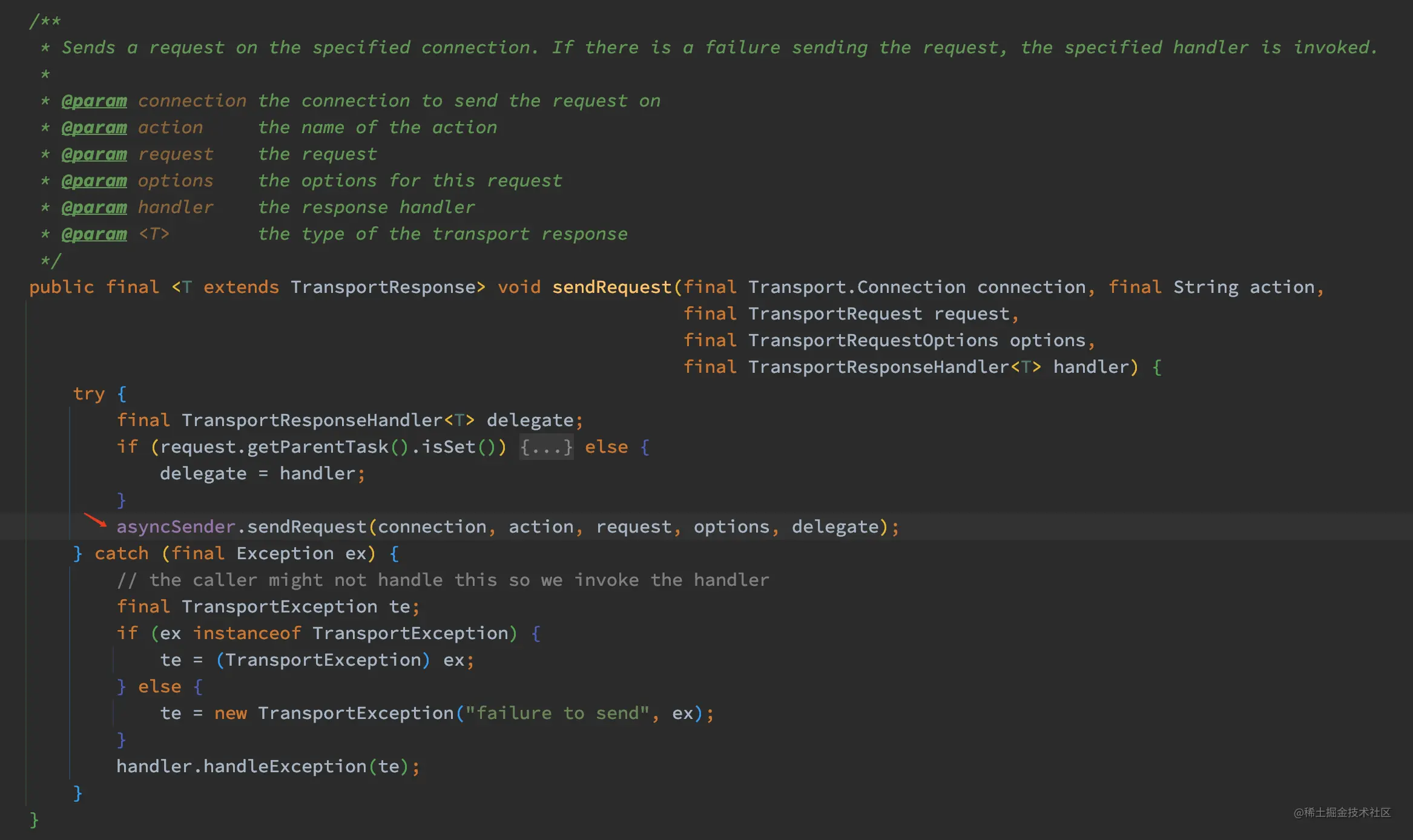
那 asyncSender 是个啥?

如上代码,简单来说 asyncSender 其实是 sendRequestInternal 的一个包装而已,所以最终 sendRequest 的实现逻辑主要在 sendRequestInternal 中处理,下面来看看 sendRequestInternal 的实现:
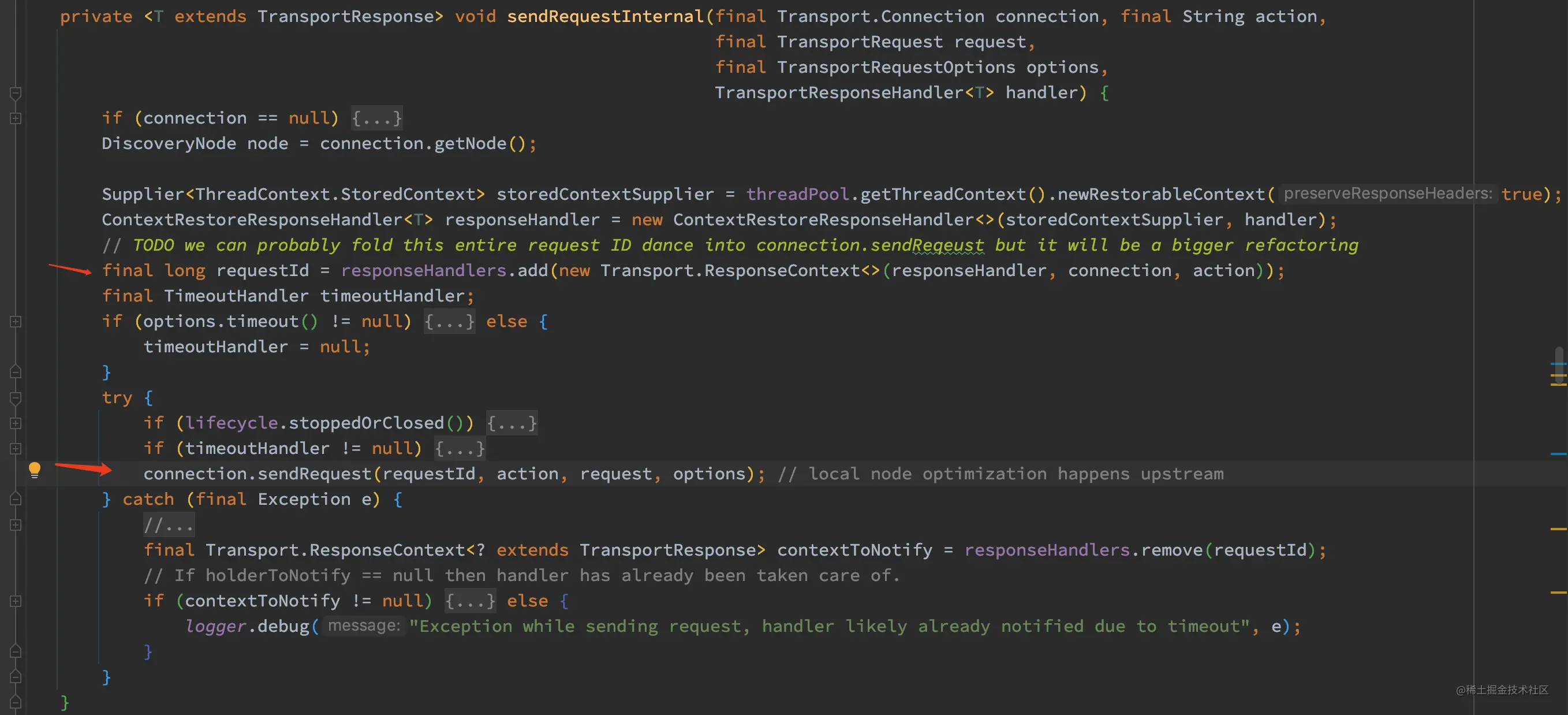
如上代码,sendRequestInternal 方法主要做了以下几件事:
- 创建 ResponseContext 并加入到 responseHandlers 中。
- 产生一个 requestId。
- 调用 connection.sendRequest。
通过跟踪 sendRequestInternal 方法可以知道,最终处理转发请求的是 connection.sendRequest,当节点为本地的时候,connection.sendRequest 调用的是 localNodeConnection 的 sendRequest,而这个方法最终调用的是 sendLocalRequest。而当 node 为非本地节点时, connection.sendRequest 调用的的是 TcpTransport.sendRequest,此时会进行发送网络请求到目标节点进行处理。
下面来看看 sendLocalRequest 的实现:
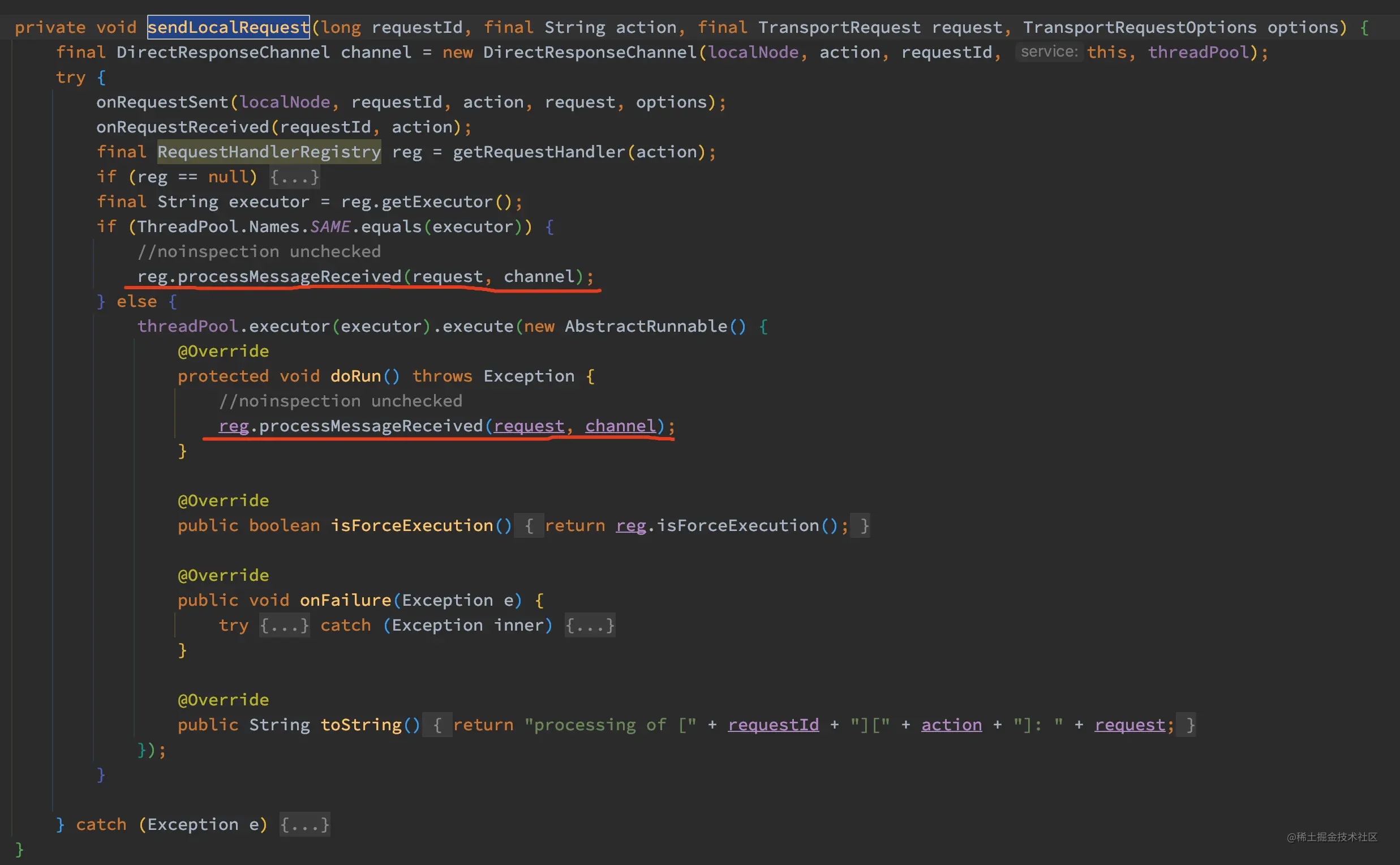
如上代码,sendLocalRequest 先获取了 RequestHandlerRegistry,然后调用其processMessageReceived 方法,在这个方法中最终调用了 handler.messageReceived 方法读取数据,其中 handler 为 TransportRequestHandler 的实例,那这个 RequestHandlerRegistry 和 TransportRequestHandler 在哪里来的呢?这里就要回到 TransportSingleShardAction 查看其构造函数了。
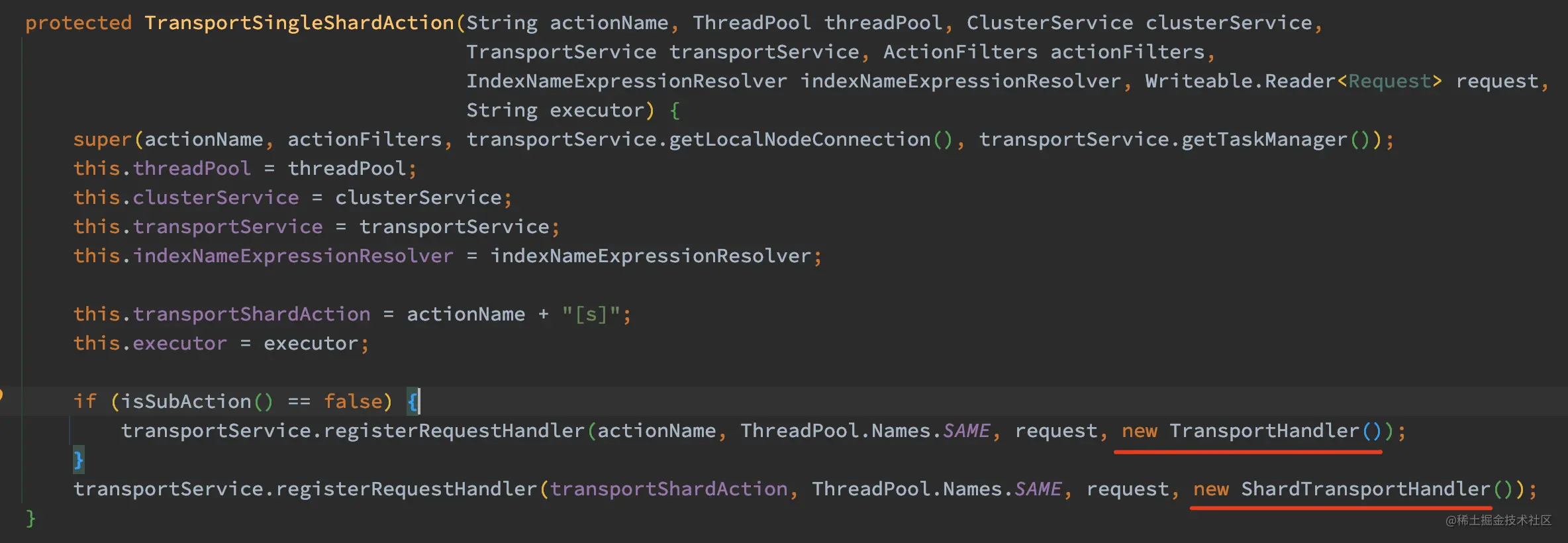
如上代码,在 TransportSingleShardAction 构造函数中调用了transportService.registerRequestHandler 注册了相关的 TransportRequestHandler。所以最终数据节点最终处理数据的方法在 TransportRequestHandler 的 messageReceived 中,也就是 TransportSingleShardAction.TransportHandler 和 TransportSingleShardAction.ShardTransportHandler 中的 messageReceived 方法。
Ok,讲了那么多,可能都被绕晕了,没关系,我们下面来简单总结一下整个请求转发的过程:
- 在 AsyncSingleAction 实例的 start 方法中处理请求转发。
- 在 TransportService.sendRequest 方法中通过 getConnection 区别了目标节点是否是本地节点。
- 当节点为本地节点的时候,执行 TransportServicel.sendLocalRequest,其会从注册了的 RequestHandlerRegistry 中获取对应的处理请求的 TransportRequestHandler,并且执行 messageReceived 处理请求。
- 如果非本地节点,则调用 TcpTransport.sendRequest,此时会进行发送网络请求到目标节点进行处理。如果等待目标节点的回复超时或者数据节点发生其他失败的情况,则选择下一个 Shard 进行重试操作,重试的方法为 AsyncSingleAction.onFailure:

2. 数据节点
在数据节点,处理 Get 请求的入口为:TransportSingleShardAction.ShardTransportHandler.messageReceived 方法。其负责读取数据并且包装结果进行返回:

通过跟踪,asyncShardOperation 最终调用了 TransportGetAction.shardOperation 方法:
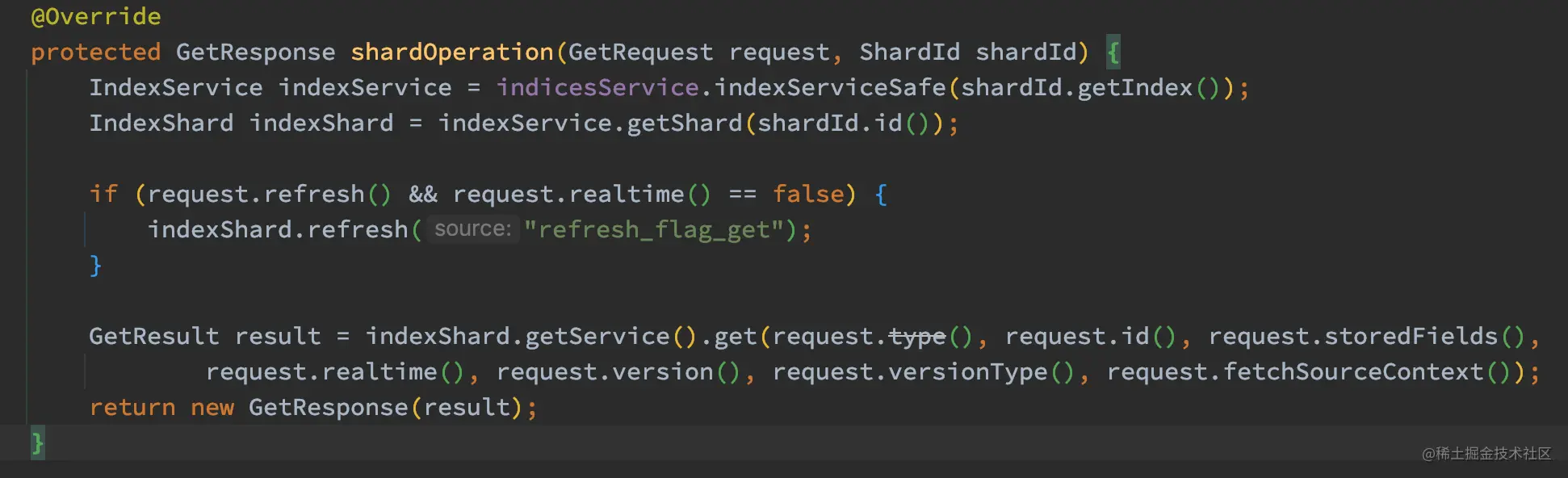
如上代码, shardOperation 先获取了对应的 IndexShard,然后检查是否需要进行 refresh 操作,这里需要注意的是,默认的情况下,Get 请求的 refresh 参数是 false 的,而 realtime 参数则为 true,更多的信息请参考官方文档,最后调用 indexShard.getService().get 方法获取数据。
indexShard.getService().get 最终调用了 ShardGetService.innerGet 方法:
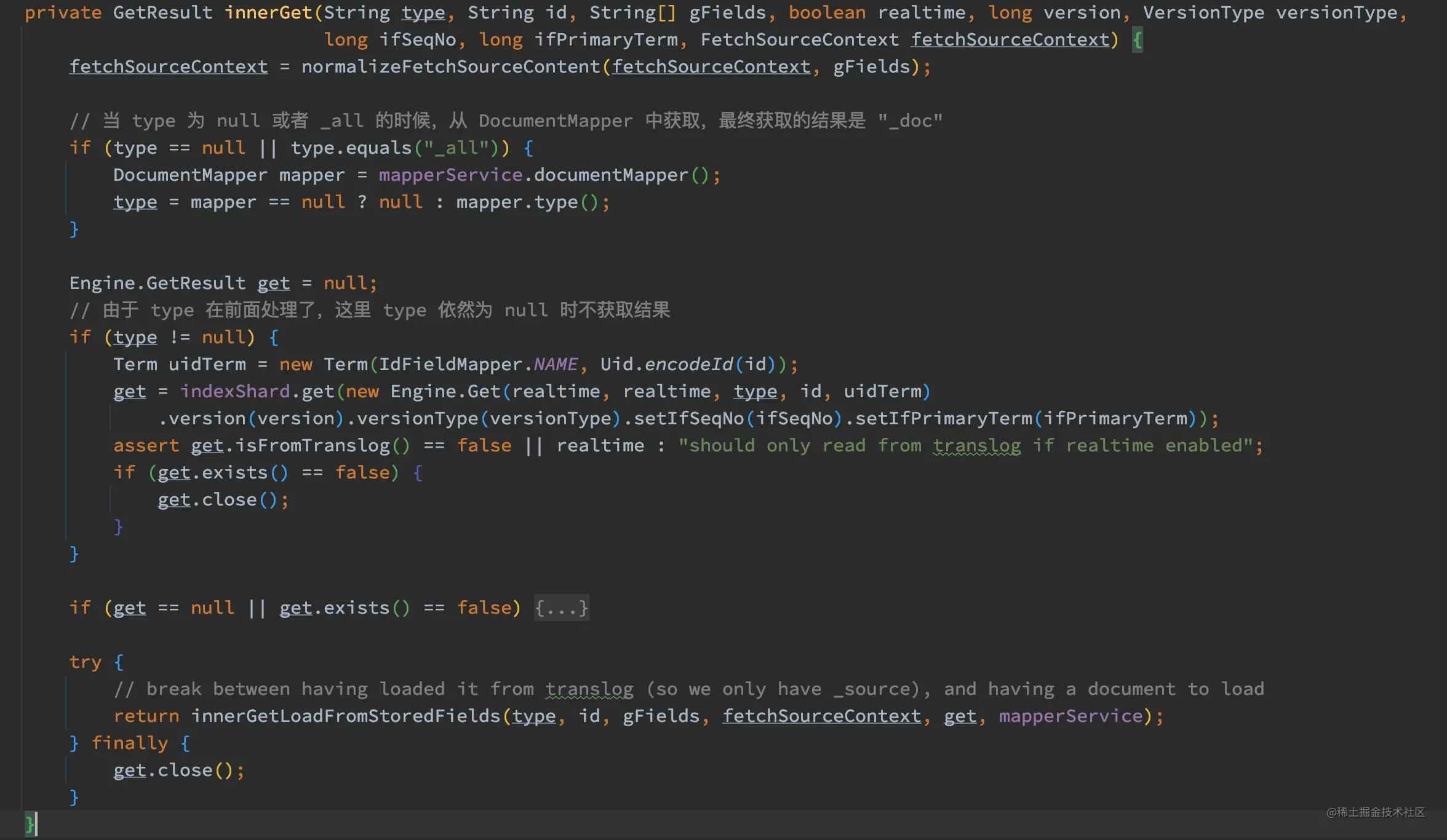
如上代码,innerGet 主要流程如下:
- innerGet 先处理了 type,在 ES 7 之后的版本里,type 统一为 “_doc” 了。
- 构造 uidTerm,这里要注意 Term 构造跟文档的 id 相关,这个 uidTerm 我们后面会用到。
- 通过调用 indexShard.get 方法获取文档内容,此处的 version、SeqNo、PrimaryTerm 我们在之前的章节中都有提到的。indexShard.get 方法最终调用了 InternalEngine.get 方法。
- 如果结果为 null 返回一个空结果,否则调用 innerGetLoadFromStoredFields 方法从返回的 Engine.GetResult 实例中获取结果并且过滤相关的字段,并且将结果保存在 org.elasticsearch.index.get.GetResult 实例中(注意这是两个同名的 GetResult 类,但 实现不同)。
综上所述,核心数据的读取最终调用的是 InternalEngine.get 方法:
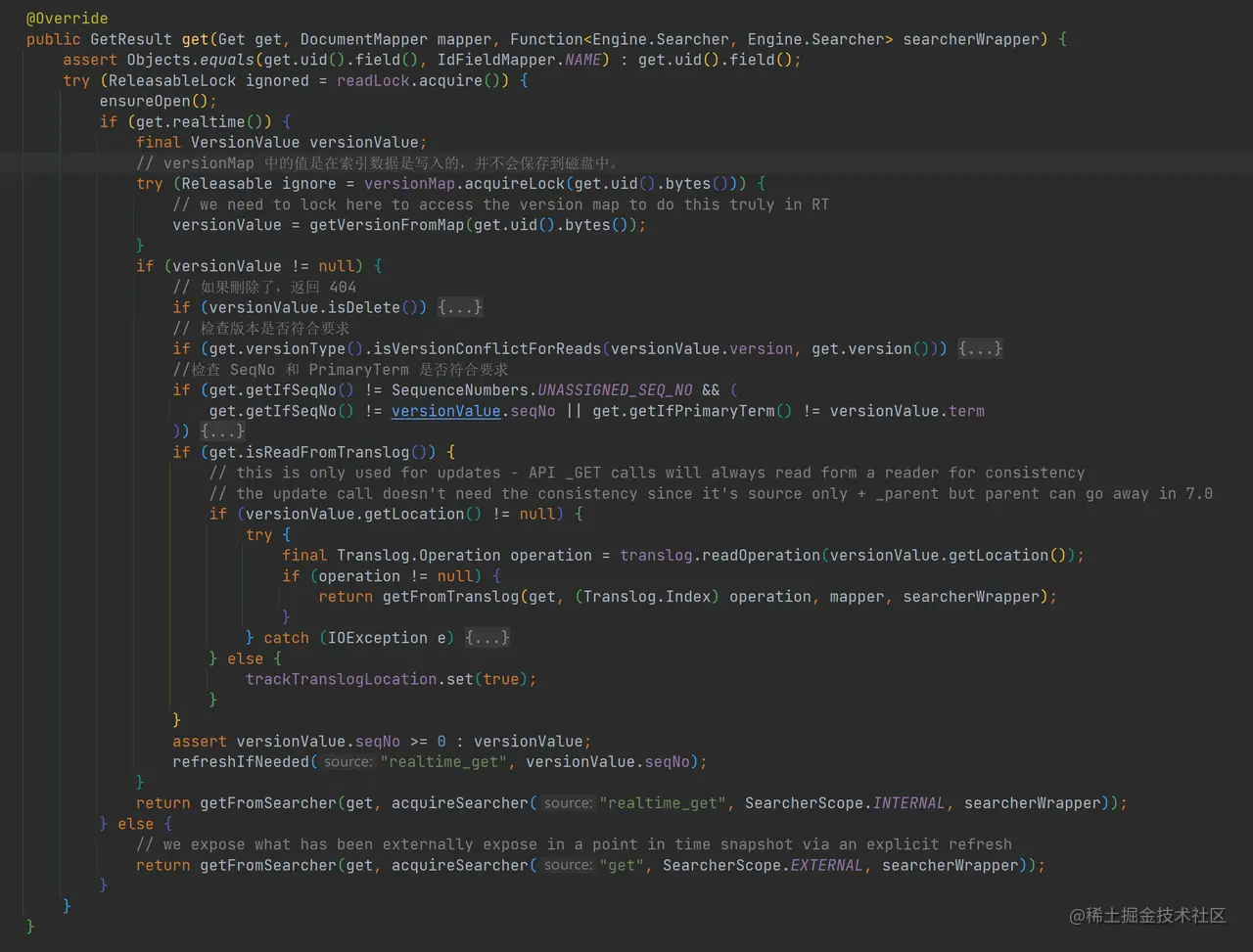
如上代码,get 方法先获取读锁 readLock,然后判断是否为实时获取文档内容,最后调用
getFromSearcher 获取文档数据,其中 Engine.Searcher 为 IndexSearcher 的子类。
这里我们把重点转到 realtime 为 true 时的流程。首先对 versionMap 加锁,然后从 versionMap 中文档的 versionValue,其中获取 versionValue 时使用的 key 为 get.uid(),其为上面提到过的 uidTerm。versionMap 你可以简单的认为是文档 id 与 VersionValue 组成的 Map,其保存在内存中,不会写入到磁盘上,当执行 refresh 成功后会被清理。
那为什么 versionMap 不需要保存到磁盘上呢?其实很好理解,当 refresh 成功后,这些数据都已经持久化了,此时如果 Get 一个文档,那么其 versionValue 是空的,说明这个文档的数据已经持久化了,直接读磁盘即可,此时就已经是实时的了。所以 refresh 成功后 versionMap 可以清空,也可以避免消耗过多的内存。而当系统启动时会进行恢复的流程,需要持久化的数据也会持久化到磁盘中,所以系统启动后(此文档还没有写操作),此时发生 Get 请求获取文档数据也是实时的。
当获取到的 versionValue 不为空的情况下,会检查文档的 version、SeqNo、PrimaryTerm 是否符合要求(需要注意的是 Get 的 version 和 versionType 是从传入的参数中进行解析的)。
最后调用 refreshIfNeeded 执行 refresh 操作:
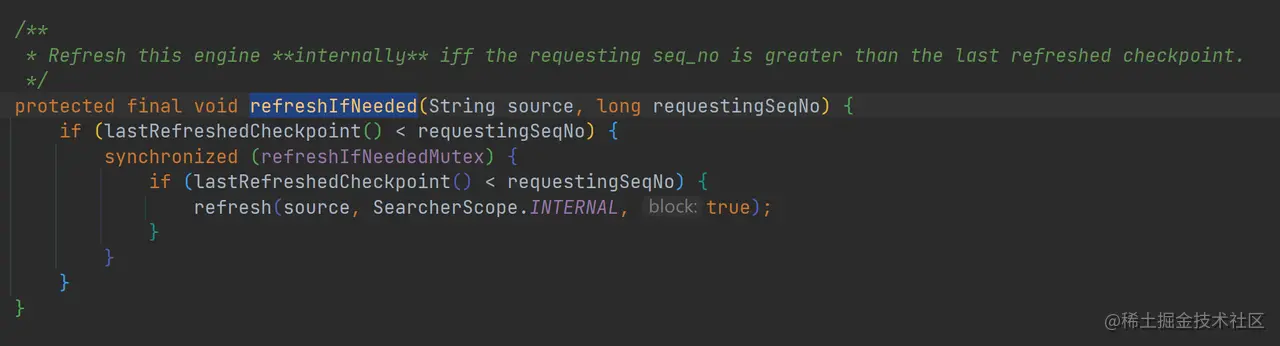
如上代码,并不是每次都执行 refresh 操作的,只有 lastRefreshedCheckpoint < requestingSeqNo 才会执行 refresh 操作,所以这个 lastRefreshedCheckpoint 其实应该与 SeqNo 相关的,大家可以再往里挖,这里就不展开了。
那为什么要判断 lastRefreshedCheckpoint < requestingSeqNo 这个条件两次,并且加锁呢?其实跟多线程操作有关,细想一下就知道,在加锁后再次判断条件时有可能不成立了,因为可能有其它线程已经执行了 refresh,所以需要再判断一次。那不做第一次判断可以吗?我个人觉得可以,我觉得这里应该是为了提高效率才这样做的。
所以,Get API 默认的情况下是实时的,系统通过进行 refresh 操作来保证 Get API 的实时性。
Ok,到这里数据节点的数据读取流程也走完了,当然我们没有深入到很多分支的细节中,例如读取数据的细节、Result 是如何封装起来的,这些你都可以自己再慢慢研究。
下面我整理了一下 Get 的整体流程:
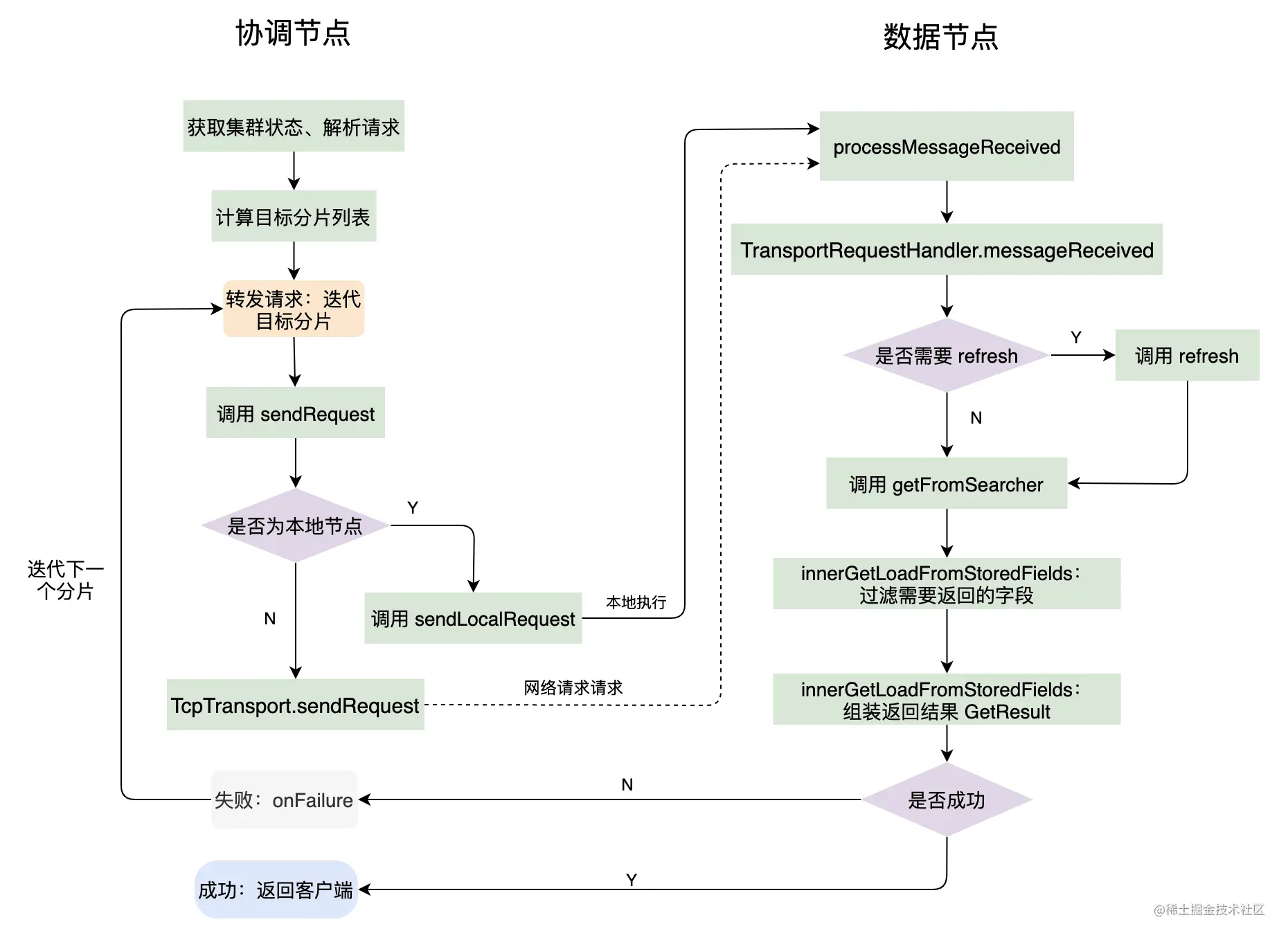
三、MGet 源码跟踪
MGet 的基本流程与 Get 差别不大,协调节点会将 Mget 中多个 Get 请求异步发送到对应的节点中处理,并且等待和收集全部请求的响应,然后整理后返回给客户端。
处理 MGet 的类为:org.elasticsearch.action.get.TransportMultiGetAction,在其 doExecute 方法中主要对每个 Get item 获取对应的 Shard 等信息,然后再调用 executeShardAction 对每个 Get item 异步发送请求。
MGet 的主要流程如下:
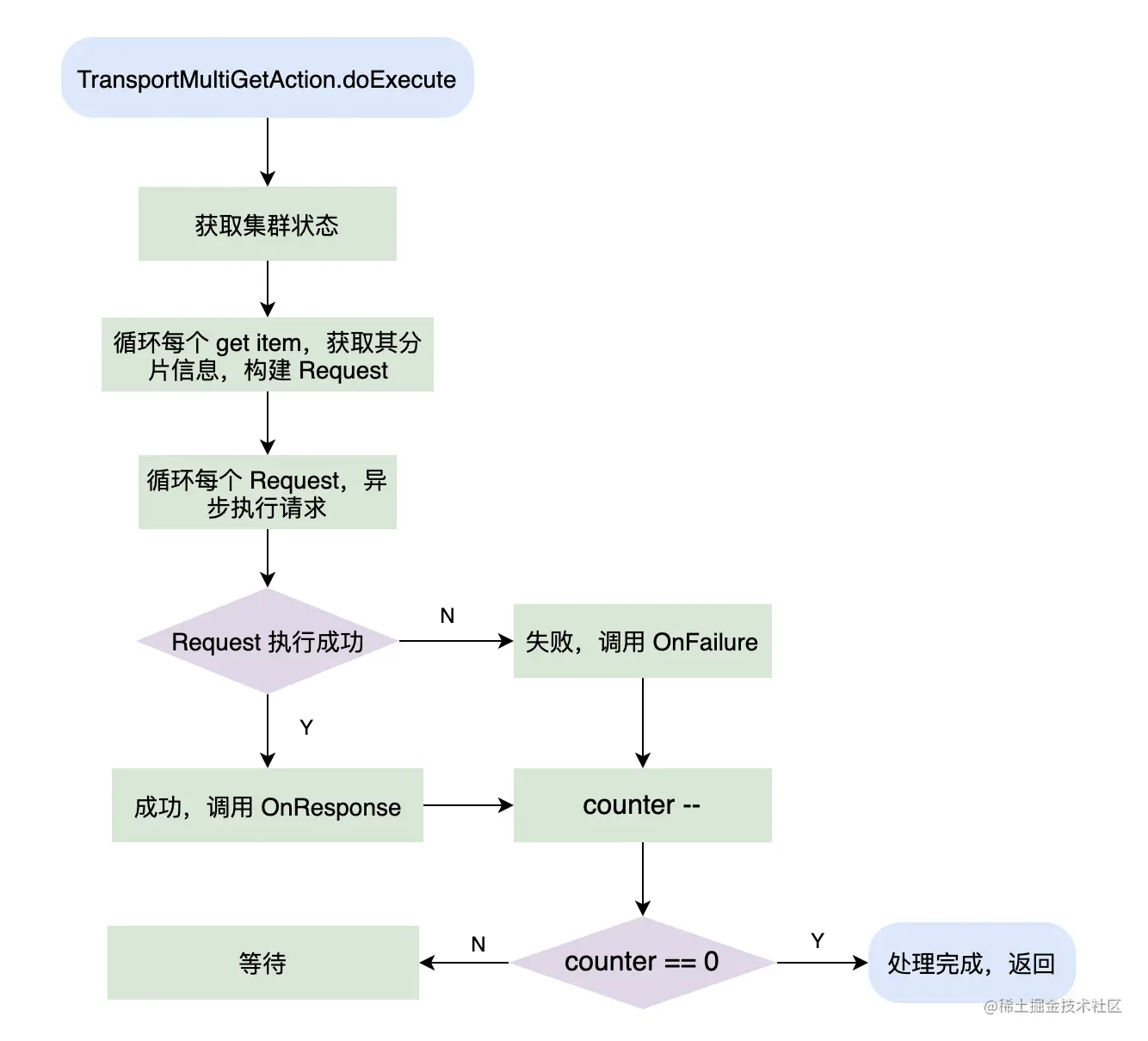
- 在 doExecute 遍历每个 Get item,计算出每个 item 对应的路由信息,并且构造以 shardid 为 key,MultiGetShardRequest 为 value 的 map。
- 在 executeShardAction 中遍历每个 request item,调用 shardAction.execute 异步处理请求。可以发现 shardAction 是 TransportShardMultiGetAction 的实例,其继承了 TransportSingleShardAction,所以每个 item request 的处理其实使用了TransportSingleShardAction.AsyncSingleAction,与单个文档的 Get 请求处理一致。
- 最后收集各个 request 的 response,等到全部 response 返回后,执行 finishHim 方法,返回结果给客户端。需要注意的是,返回的结果中文档的顺序与请求的顺序一致。
四、总结
今天我与你阅读跟踪了 Get 和 MGet 的整体流程,我们从应该 Get REST 请求开始说起,一直到协调节点进行内容路由和请求转发、数据节点进行数据读取和结果返回。
在实现类的角度来看,总的来说,实现了 RestHandler 接口的类它们代表着 REST 请求,而真正处理这些请求内容的类则为形如 Transport*Action 的类,例如处理 Get 请求的类为 TransportGetAction。
在流程上来看,协调节点在接收到请求后会获取可以处理这个请求的 Shard 列表信息,然后转发请求。如果处理这个请求的节点为本地节点,则直接读取数据,不再进行网络转发。而如果是远程的数据节点,则通过发送网络请求,并且等待请求返回。
通过 Get 源码的阅读,也可以回答我们文章开头提出的两个问题了。
- 如果我们写入数据后马上使用 Get API 获取数据可以获取到吗?答案是可以的,系统通过 refresh 操作来保证 Get API 的实时性。
- 系统是如何确定该到哪个 Shard 上找文档内容的呢?系统通过文档 id 和 routing key 参数来计算确定该到哪个 Shard 上获取数据。
最后整理了下图来对 Get 源码流程做一个简单总结: 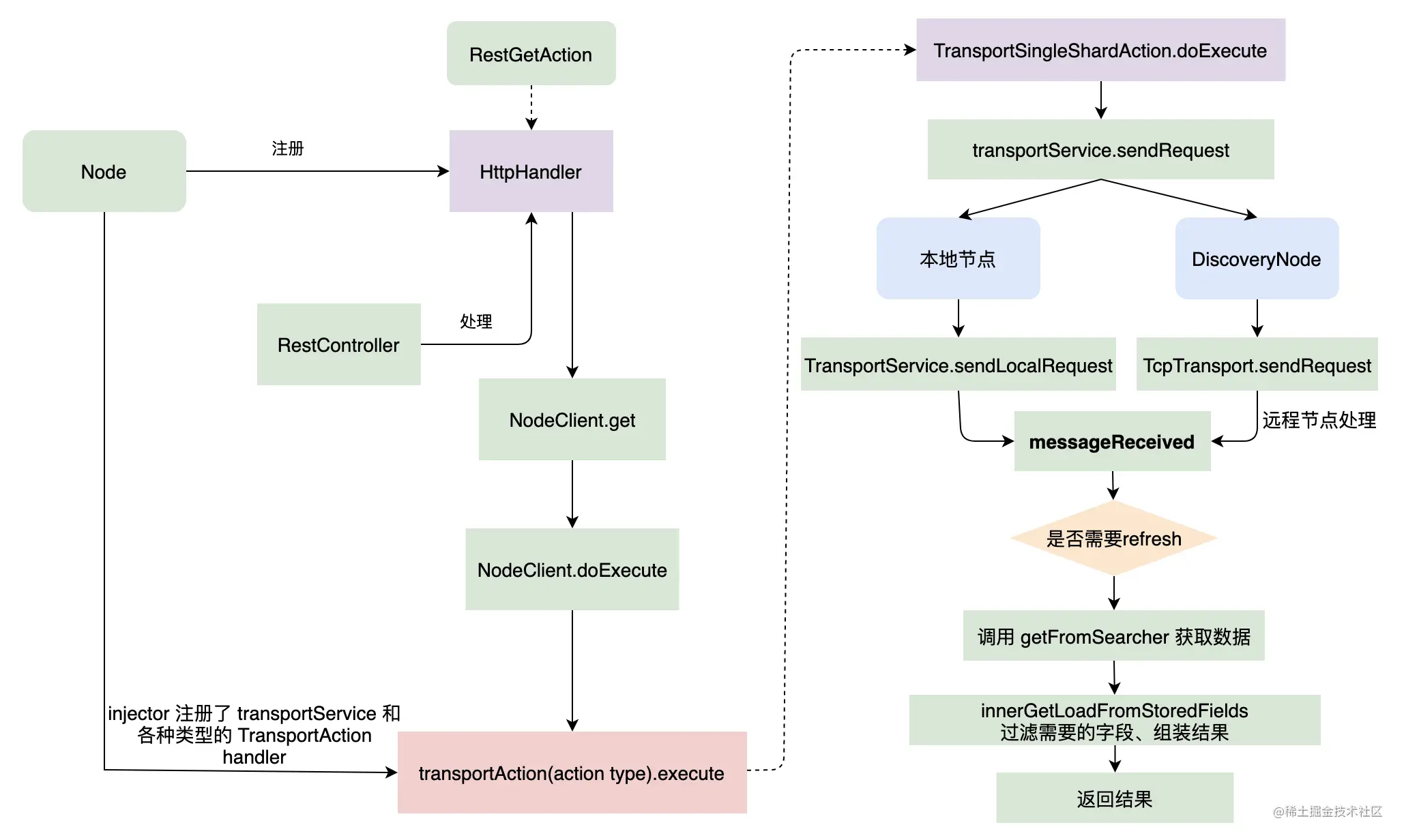
相信通过今天的学习,很多 API 的源码阅读你应该都可以应付了。
