今天我们将以 ES 7.13.0 为基础来走一遍节点的启动过程。节点的启动过程比较长,我们只关注大概的流程,至于具体的细节,大家可以后面再慢慢研究。
ES 的启动主要涉及 3 个类:
- Elasticsearch,其中 Elasticsearch 继承了 EnvironmentAwareCommand,而 EnvironmentAwareCommand 继承了 Command,所以 Elasticsearch 可以解析命令行参数,同时 Elasticsearch 还负责加载配置等工作。
- Bootstrap,Bootstrap 主要负责资源检查、本地资源初始化。
- Node,主要负责启动节点,包括加载各个模块和插件、创建线程池、创建 keepalive 线程等工作。
所以我们今天会把节点启动过程分为 3 个阶段(分别对应上述的类)来分析节点整体的启动流程,最后我们还会从宏观的角度来看看集群的启动流程。
一、阶段一:命令行参数解析与配置加载
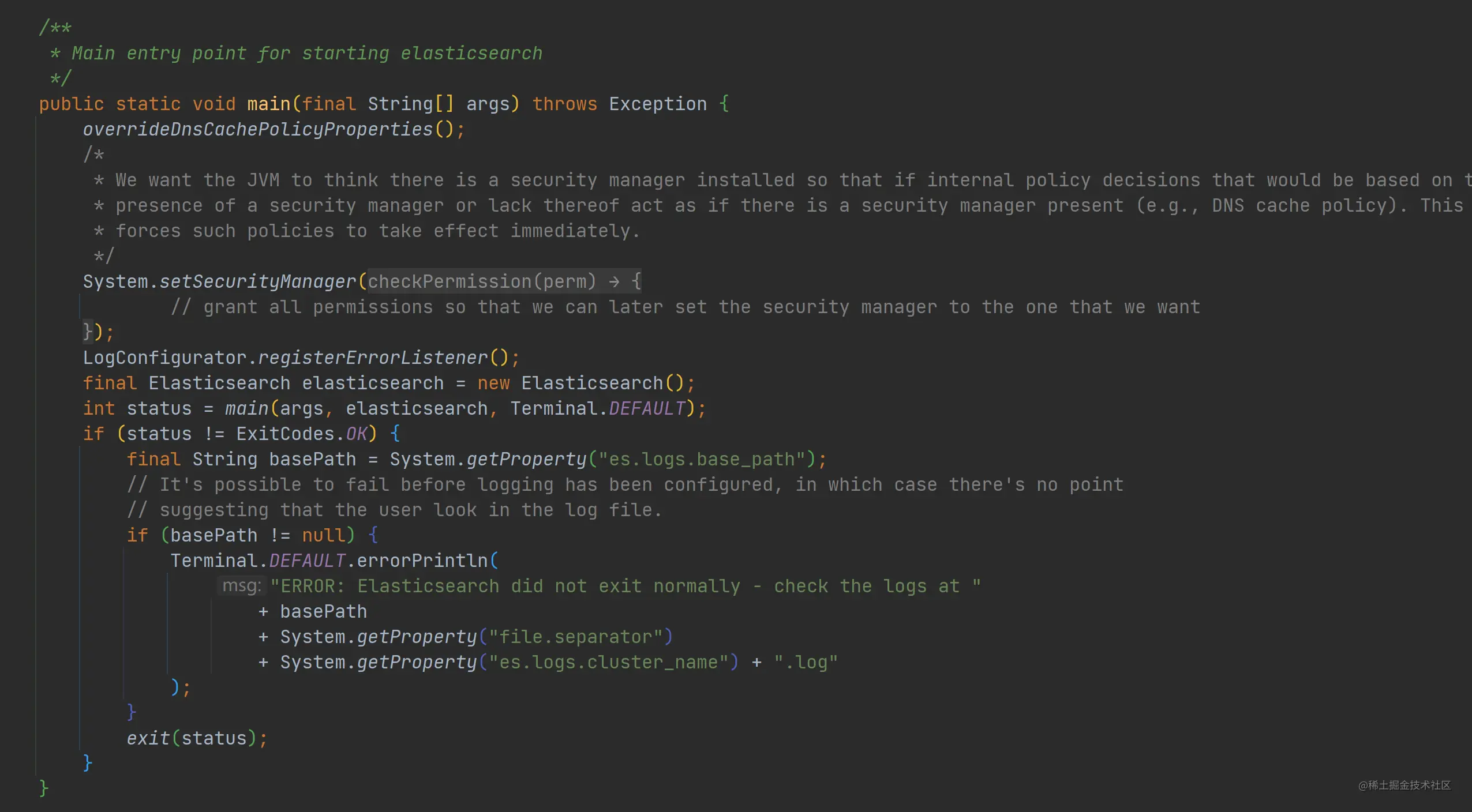
如上图,ES 的启动入口在 org.elasticsearch.bootstrap.Elasticsearch.java 中的 main 函数。main 主要做了以下几件事:
- 重写 DNS 缓存时间
如果启动时传入 es.networkaddress.cache.ttl 或 es.networkaddress.cache.negative.ttl VM 参数的话,将会在这里被解析。你可以在 IDEA 启动 ES 时加入 -Des.networkaddress.cache.ttl=15 进行调试跟踪这个函数的工作。更多关于 DNS 缓存的信息可以参考官方文档。
- 创建空的 SecurityManager 安全管理器
为了保证 Java 应用程序的安全性,在应用层,Java 为用户提供了一套安全管理机制:SecurityManager 安全管理器。Java 应用可以使用自己的安全管理器在运行阶段检查资源的访问和操作权限,从而保护系统不受恶意的攻击。
在这里,ES 先简单创建了一个安全管理器,并且这个安全管理器是授予了所有权限的,在后续执行中可以为这个安全管理器设置所需要的权限。
- 注册错误日志监听器
通过调用 LogConfigurator.registerErrorListener() 注册错误日志监听器。在此处安装监听器可以记录在一些在加载 log4j 配置前的启动错误信息,如果启动有错误将会停止启动并且显示出来。
- 创建一个 Elasticsearch 对象实例
可以看到,其实 Elasticsearch 类继承了 EnvironmentAwareCommand,而 EnvironmentAwareCommand 继承了 Command,所以 Elasticsearch 可以解析命令行参数,同时 Elasticsearch 还负责加载配置等工作。
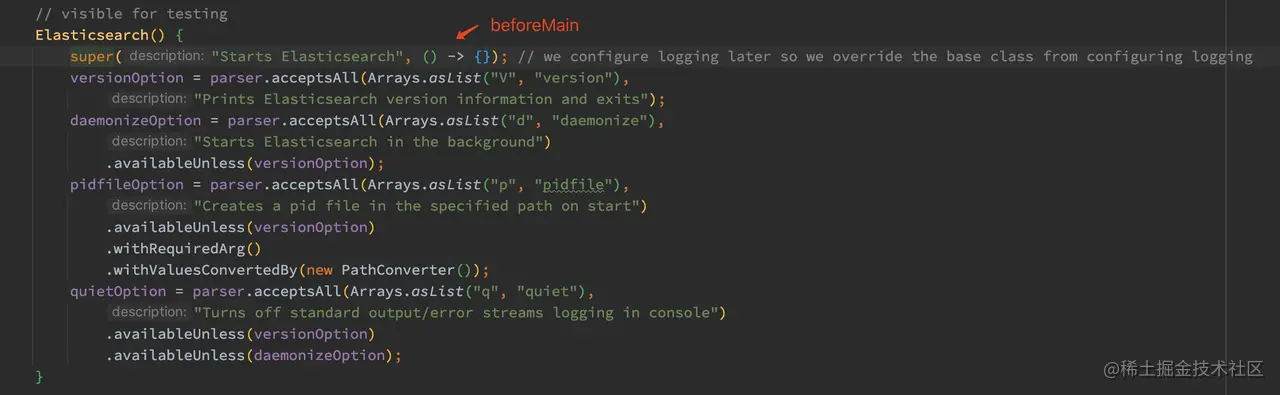
调用 Elasticsearch 构造方法时,主要解析了一些 命令行传入的参数,如 V(版本)、d(后台运行)、p(pid文件)、q(退出)等,需要注意的是此处的 beforeMain 函数是啥都没有干的。而在 super(EnvironmentAwareCommand构造函数)里,主要是设置 settingOption,所以命令行的 ES 参数需要以 -Ees.path.home=/es/home 这样子来设定。
通过跟踪 Elasticsearch.main 可以发现,其最终调用了 Command.main(这个函数太长了,不截图啦),其主要执行内容为以下几步:
- 注册一个 ShutdownHook
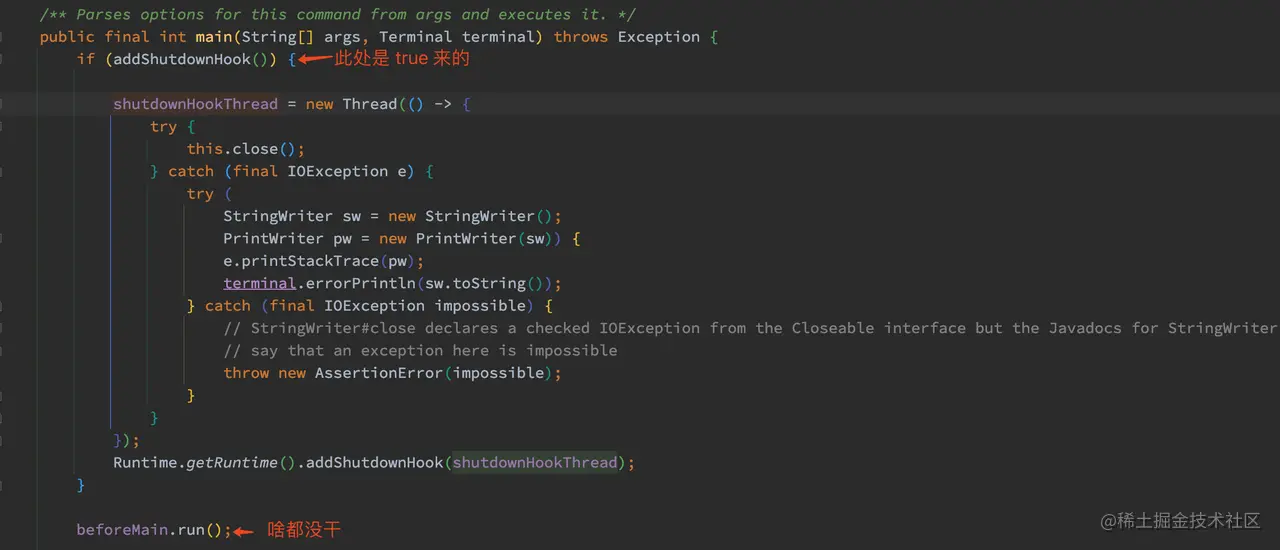
Command.main 函数首先注册了一个 ShutdownHook,其作用是在系统关闭的时候捕获 IOException 并且进行输出。
这里需要注意,beforeMain 其实是之前 Elasticsearch 构造函数传进来的,是一个空函数,此处啥都没干。
- 解析命令行参数
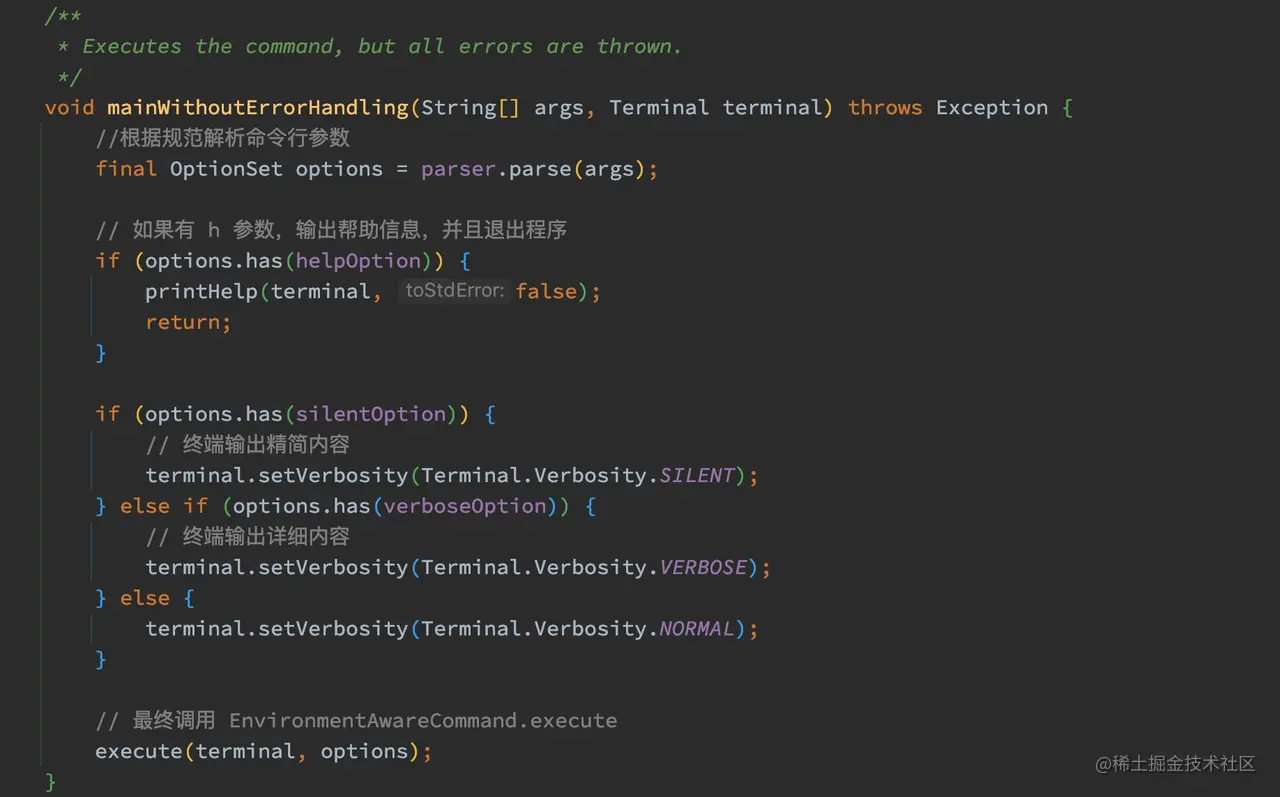
在注册完 ShutdownHook 后,调用 Command.mainWithoutErrorHandling 函数进行命令行参数解析,最终这个函数在解析完命令行参数后调用了 EnvironmentAwareCommand.execute 函数。
- 加载多个路径:data、home、logs

EnvironmentAwareCommand.execute 函数主要将命令行参数解析为 HashMap 的形式,然后确保 es.path.data、es.path.home、es.path.logs 这几个路径设置的存在。最后调用 createEnv 函数加载 elasticsearch.yml 配置文件,再调用 Elasticsearch.execute 函数。
- 加载 elasticsearch.yml 配置文件
createEnv 函数最终调用了 InternalSettingsPreparer.prepareEnvironment 来加载 elasticsearch.yml 配置文件,并且创建了 command 运行的环境:Environment 对象。这部分感兴趣的可以进行 debug 跟踪其实现细节,这里就不展开了。
- 验证配置
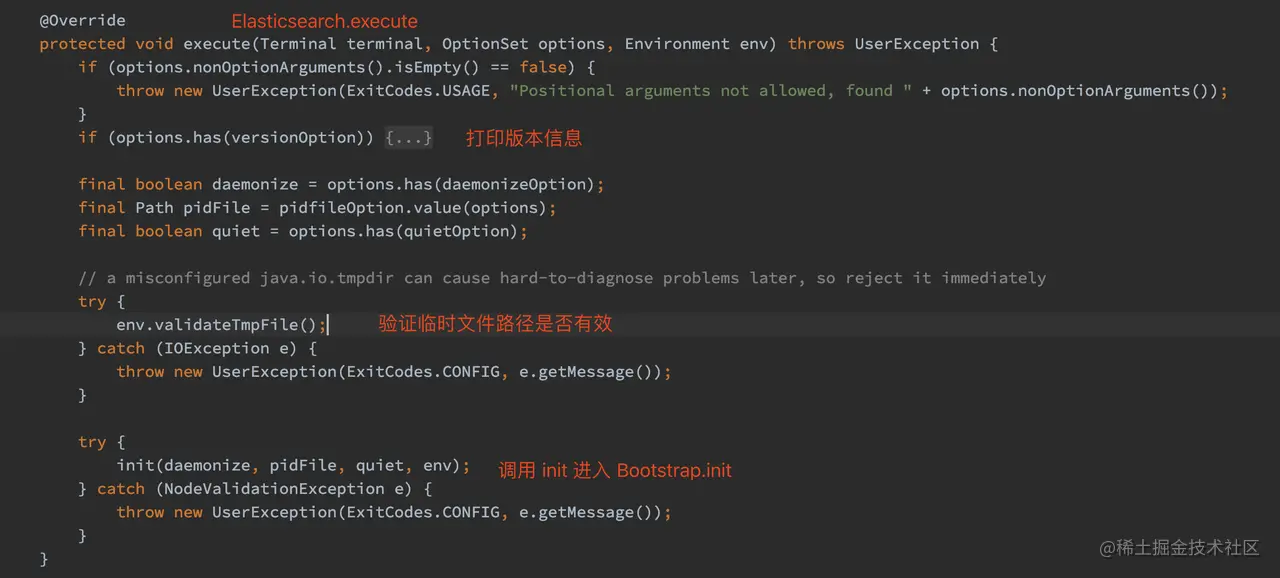
EnvironmentAwareCommand.execute 函数最终调用了 Elasticsearch.execute 函数,Elasticsearch.execute 主要做配置验证的操作,并且调用 init 函数进入到 Bootstrap.init,也就进入到第二阶段了。
所以总的来说,启动的第一阶段做了命令行参数解析与配置加载验证的工作。
二、阶段二:资源检查与本地资源初始化
阶段二主要在 Bootstrap 类中进行,我们进入到 Bootstrap.init 中进行跟踪,其详细流程如下:
- 创建 Bootstrap 实例 通过 INSTANCE = new Bootstrap() 创建了 Bootstrap 实例:
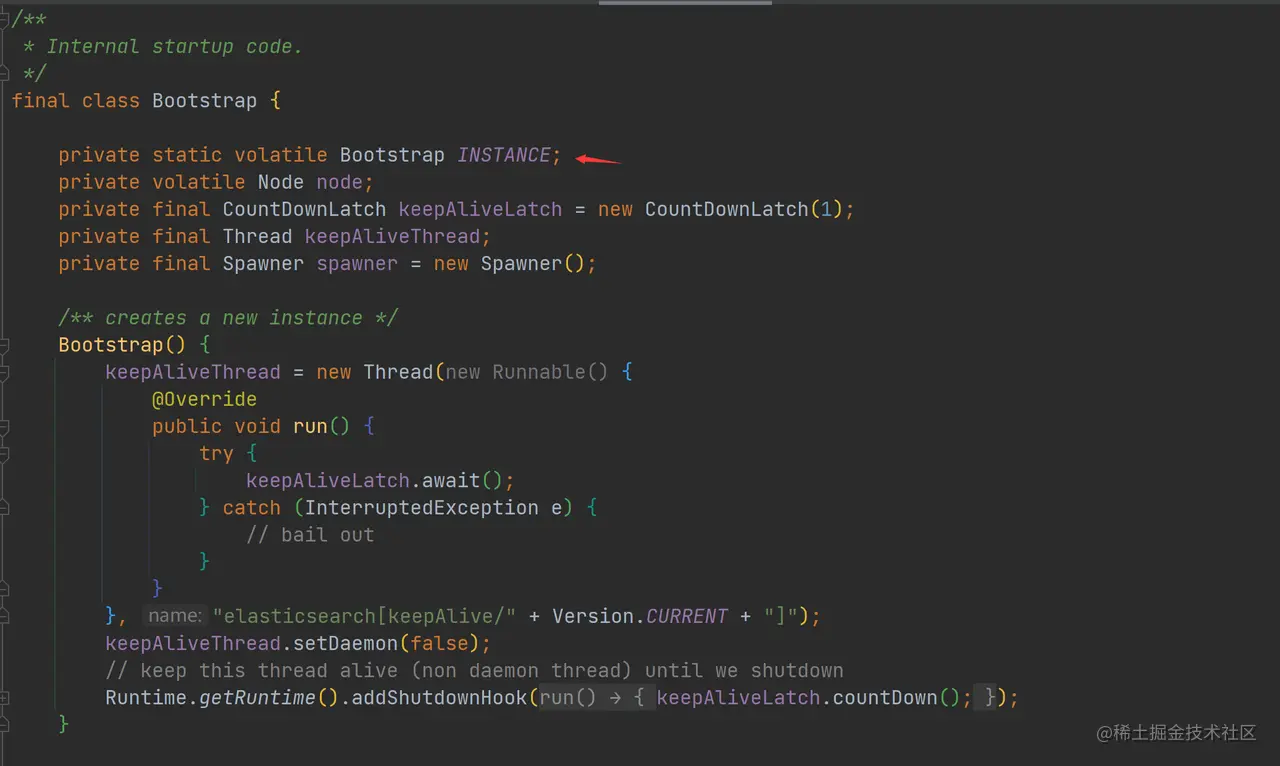
如上代码,Bootstrap 实例是一个单例,但其又不是严格按照我们常用的那几种创建单例的模式实现的,这里的实现简单粗暴,因为外面只调用了一次。
Bootstrap 构造函数创建了 keepAlive 线程,并且将这个线程设置为非守护线程,因为 JVM 中必须存在一个非守护线程,否则 JVM 进程会退出。
这个 keepAlive 线程啥都没干,只执行了 keepAliveLatch.await(),然后就是一直等待 countDown 操作。CountDownLatch 在 Java 里是一个线程同步工具,keepAliveLatch 是一个 CountDownLatch 实例,并且 count 为 1。所以 keepAliveLatch.await() 的作用是一直等待直到有一个线程执行了一次 keepAliveLatch.countDown() 操作。
最后通过 addShutdownHook,在系统关闭的时候执行 keepAliveLatch.countDown() 操作。
- 加载 elasticsearch.keystore 安全配置 细心的你会发现,在运行了 ES 后在,在 config 目录会生成一个 elasticsearch.keystore 文件,这个文件是用来保存一些敏感配置的。因为 ES 大多数配置都是明文保存的,但是像 X-Pack 中的 security 配置需要进行加密保存,所以这些配置信息就是保存在 elasticsearch.keystore 中。
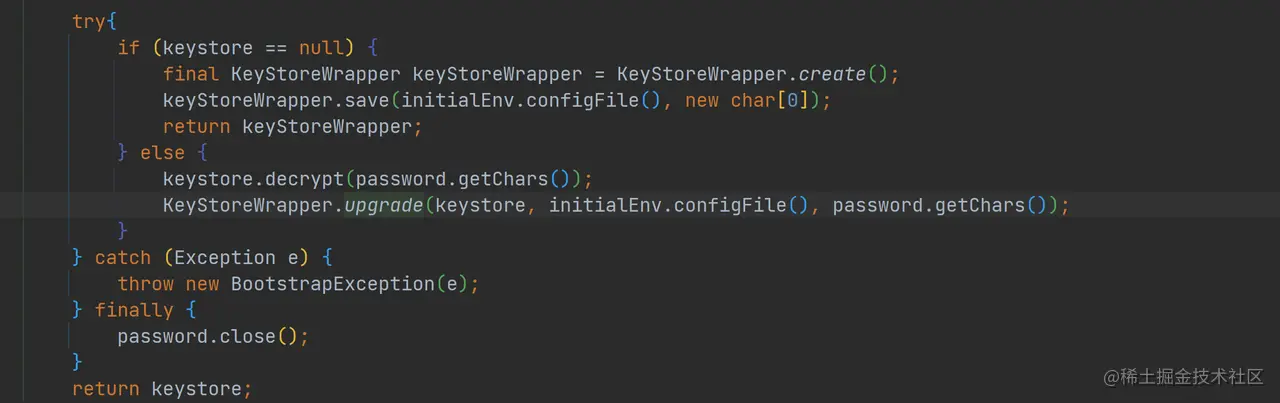
如上代码,在 loadSecureSettings 函数中进行加载 elasticsearch.keystore 中的安全配置,如果 elasticsearch.keystore 不存在,则进行创建并且保存相关信息,如果 elasticsearch.keystore 存在,则更新配置信息。
- 创建一个新的 Environment
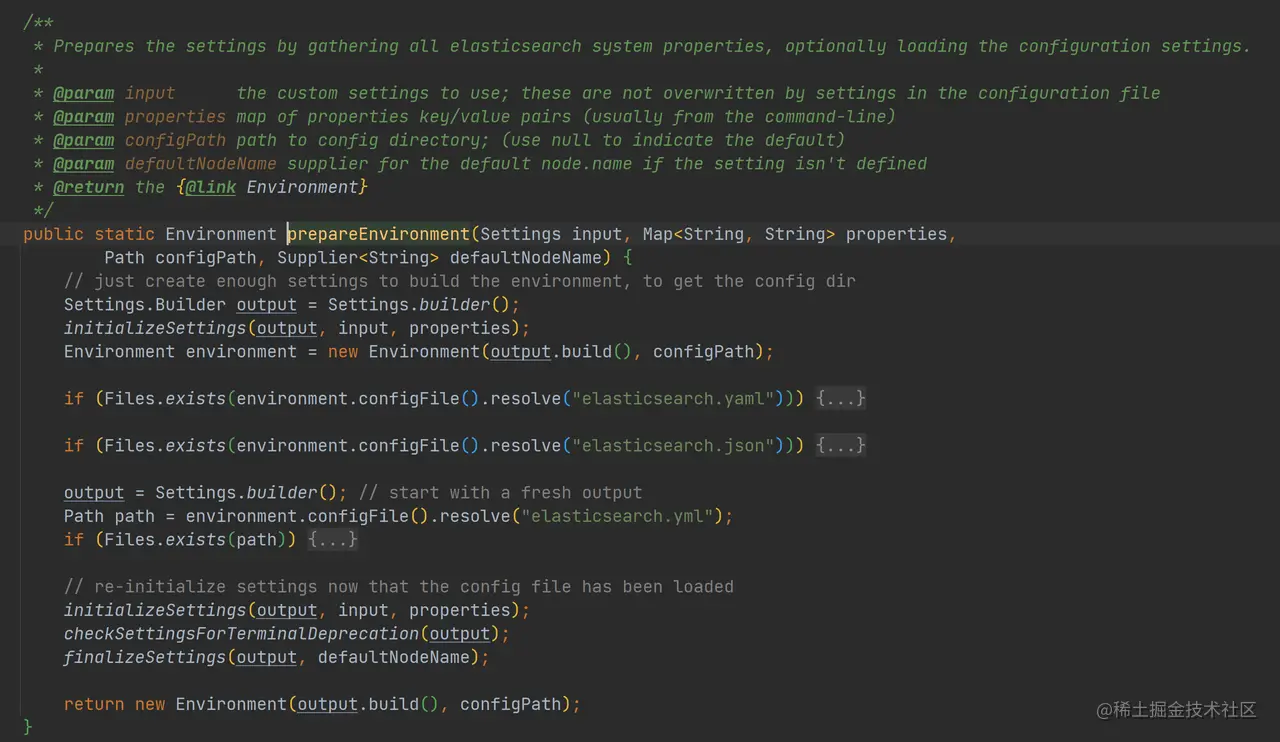
如上代码,根据保存初始化配置的 initialEnv 和 安全配置 keystore 调用 createEnvironment(最终调用 prepareEnvironment 函数) 重新创建一个运行 ES 必须的环境。
- 设置节点名称
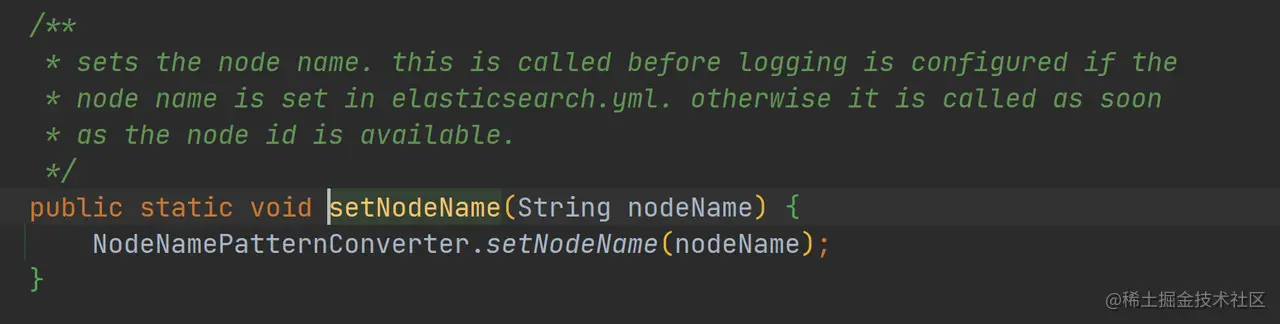
如上代码,调用 LogConfigurator.setNodeName 设置节点的名字,这里设置节点的名字,可以后续的日志输出中使用,否则只要节点 ID 可用就会使用节点 ID(节点 ID 可读性不好!)。
- 加载 log4j2 配置
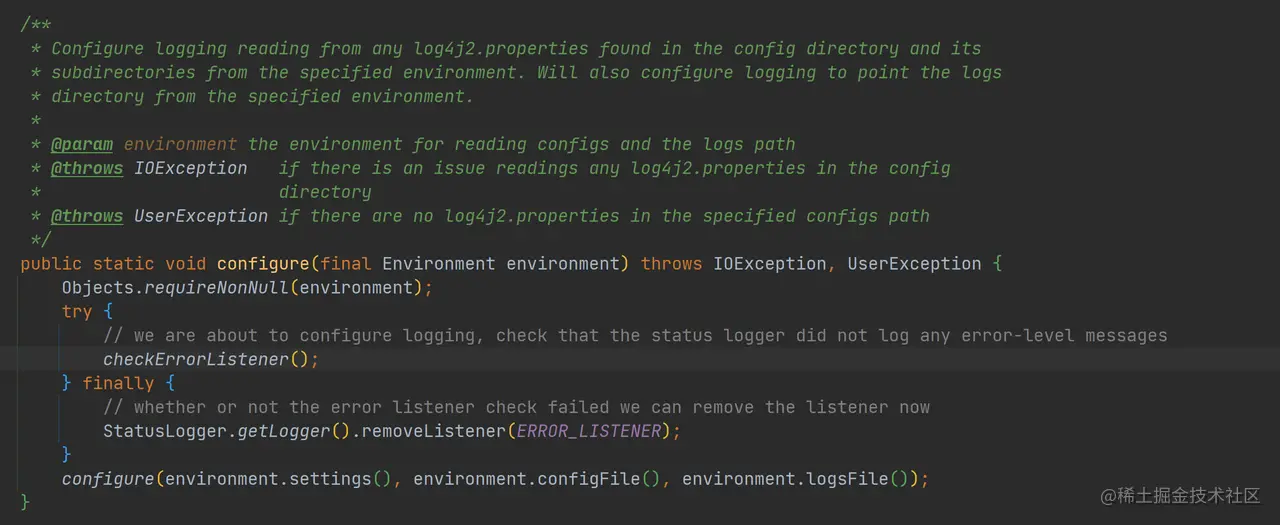
如上代码,调用 LogConfigurator.configure 加载 log4j2.properties 文件中的相关配置,然后配置 log4j 的属性。注意这里的 checkErrorListener(),不知道你是否还记得 Elasticsearch.main 中注册的错误日志监听器,在这里检查这个日志监听器是否有记录错误等级的日志。
- 创建 pid 文件
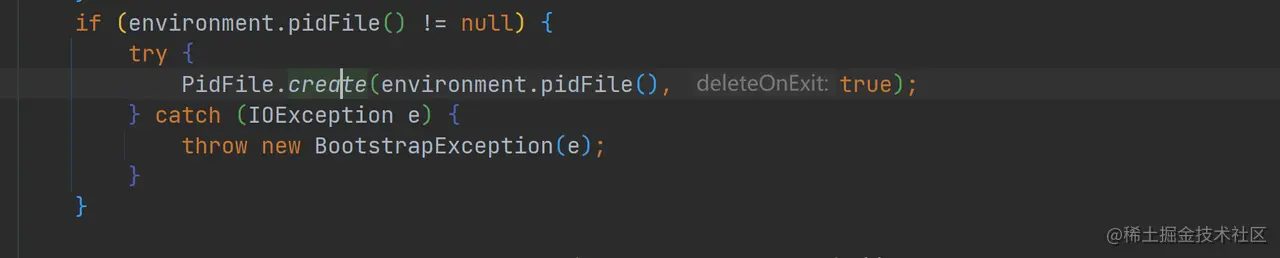
如上代码,创建 pid 文件(如果存在先进行删除),并且将进程的 pid 写入其中。
检查 Lucene jar checkLucene() 函数通过版本号来检查 lucene 是否被替换了,如果 lucene 被替换将无法启动。
安装未捕获异常的处理程序

如上代码,通过 Thread.setDefaultUncaughtExceptionHandler 设置了一个 ElasticsearchUncaughtExceptionHandler 未捕获异常处理程序。Thread.UncaughtExceptionHandler 是当线程由于未捕获的异常而突然终止时调用的处理程序接口。在多线程的环境下,主线程无法捕捉其他线程产生的异常,这时需要通过实现 UncaughtExceptionHandler 来捕获其他线程产生但又未被捕获的异常。
为创建 Node 对象实例做准备工作 通过调用 INSTANCE.setup(true, environment) 为创建 Node 对象实例做一些准备工作,下面几步我们进入到 INSTANCE.setup 中看看其实现。
为给定模块生成控制器守护程序 在 INSTANCE.setup 里调用了 spawner.spawnNativeControllers,通过跟踪,其实现如下:
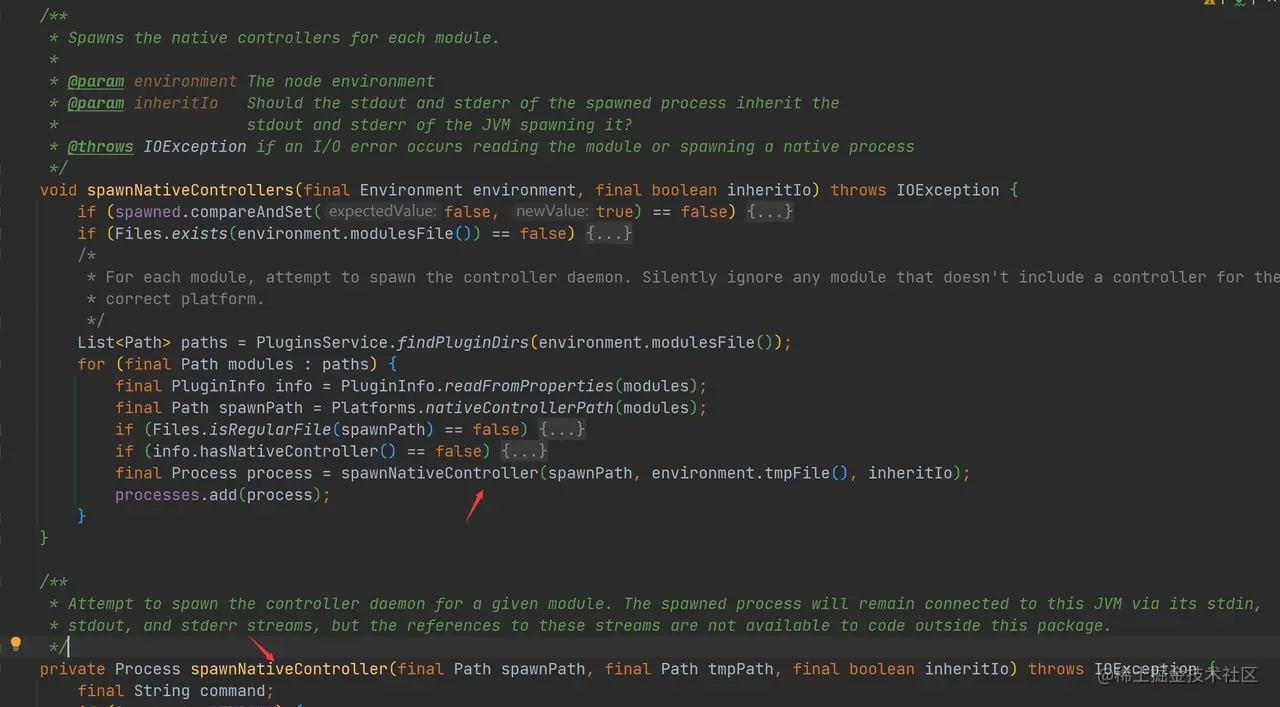
如上代码,通过注释可以知道,spawnNativeControllers 的作用主要是尝试为每个模块(modules 目录下的模块)生成 native 控制器守护进程的。生成的进程将通过其 stdin、stdout 和 stderr 流保持与此 JVM 的连接,这个进程不应该写入任何数据到其 stdout 和 stderr,否则如果没有其他线程读取这些 output 数据的话,这个进程将会被阻塞,为了避免这种情况发生,可以继承 JVM 的 stdout 和 stderr(在标准安装中,它们会被重定向到文件)。此处的实现如下:

怎么说呢,这部分要明白的话基础知识要非常扎实才行,这里涉及到很多进程、线程、子进程、守护进程、进程标准输入输出等操作系统相关的知识。遗憾的是这里无法展开了,感兴趣的可以自行了解。
- 初始化本地资源 通过调用 initializeNatives() 函数进行本地资源初始化:
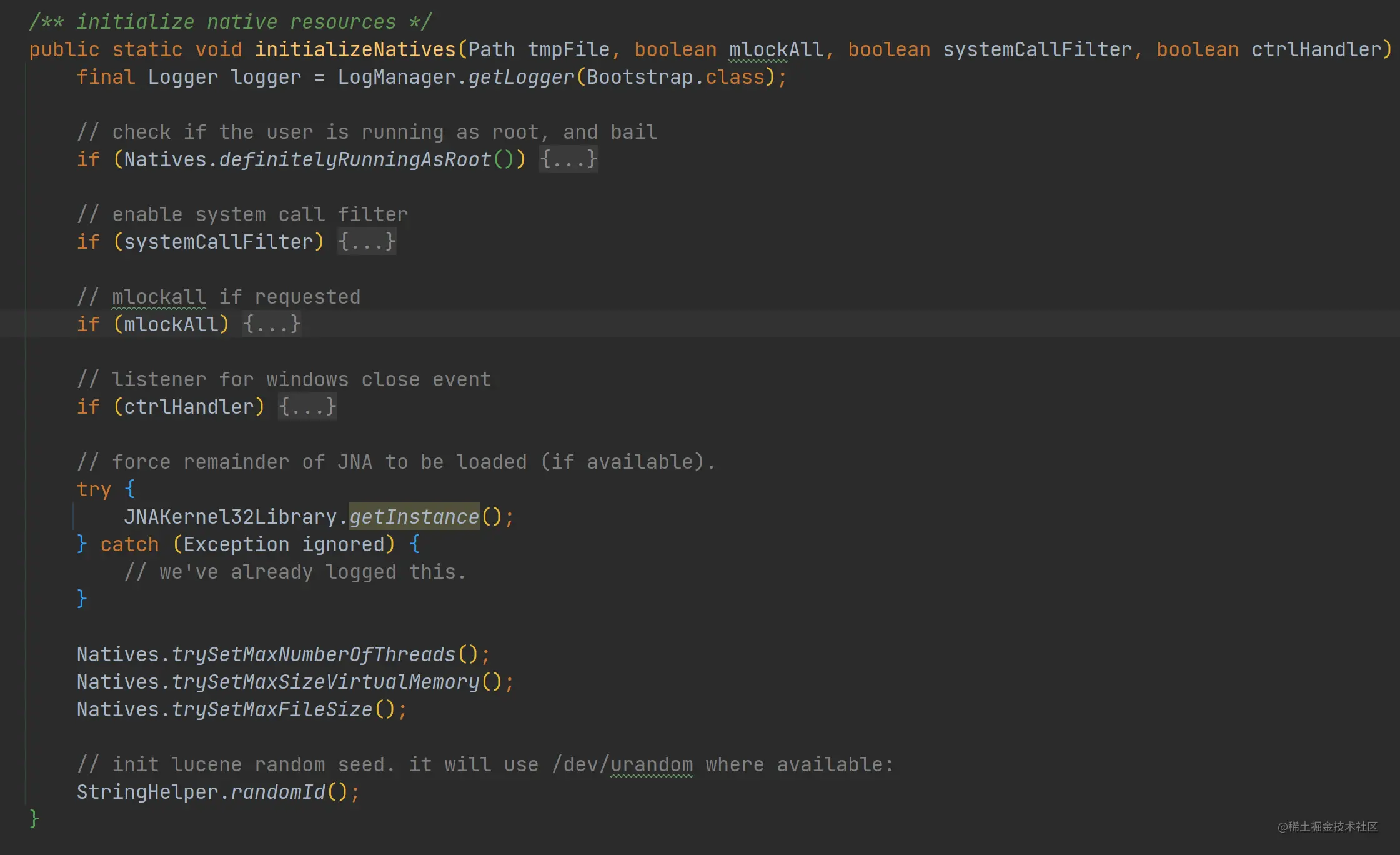
如上代码,本地资源初始化主要包括:
- 不能以 root 运行。
- 尝试启用系统调用过滤器。
- 尝试调用 mlockall,mlockall 会将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。
- 如果是运行在 Windows 的话,关闭事件的监听器。
- 尝试设置最大线程数量、最大虚拟内存、最大文件 size。
- 为 lucene 设置一个随机的 seed。
除了调用 initializeNatives() 函数进行本地资源初始化,还调用 initializeProbes() 进行初始化探针操作,主要用于操作系统负载监控、jvm 信息获取、进程相关信息获取。
- 注册关闭资源的 ShutdownHook
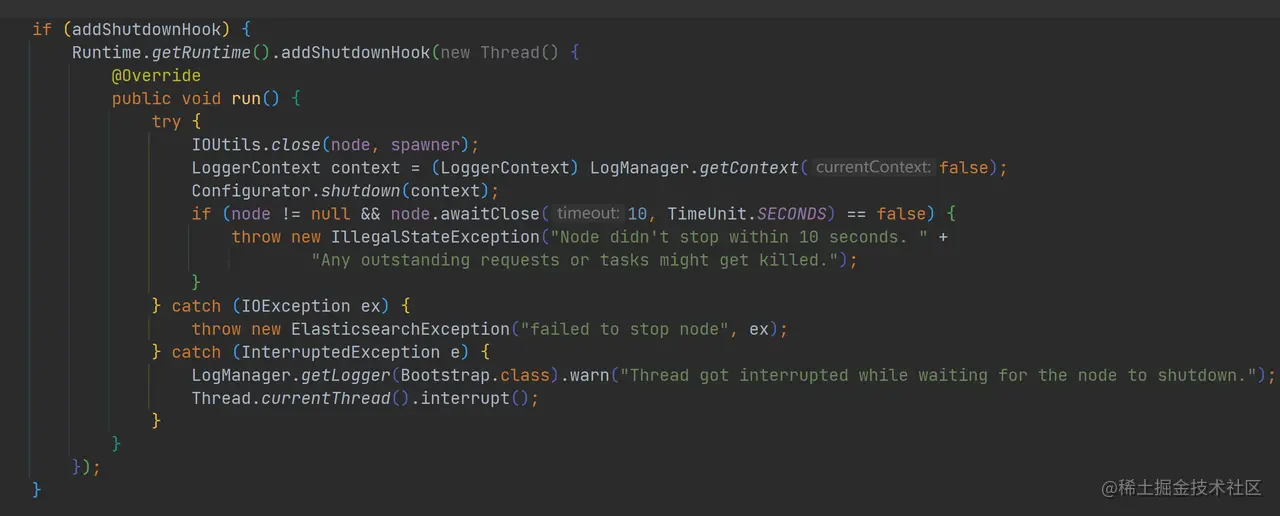
如上代码,注册看一个 ShutdownHook,用于在系统关闭的时候关闭相关的 IO 流、日志上下文。
JarHell 检查 通过调用 JarHell.checkJarHell 检查是否有重复的类。
在Debug 模式下以 ifconfig 格式输出网络信息
ifconfig 是 Linux 下常用的指令,用来获取系统网络信息的。
- 加载安全管理器,进行权限认证 通过调用 Security.configure 函数进行安全管理器加载,进行权限认证操作:
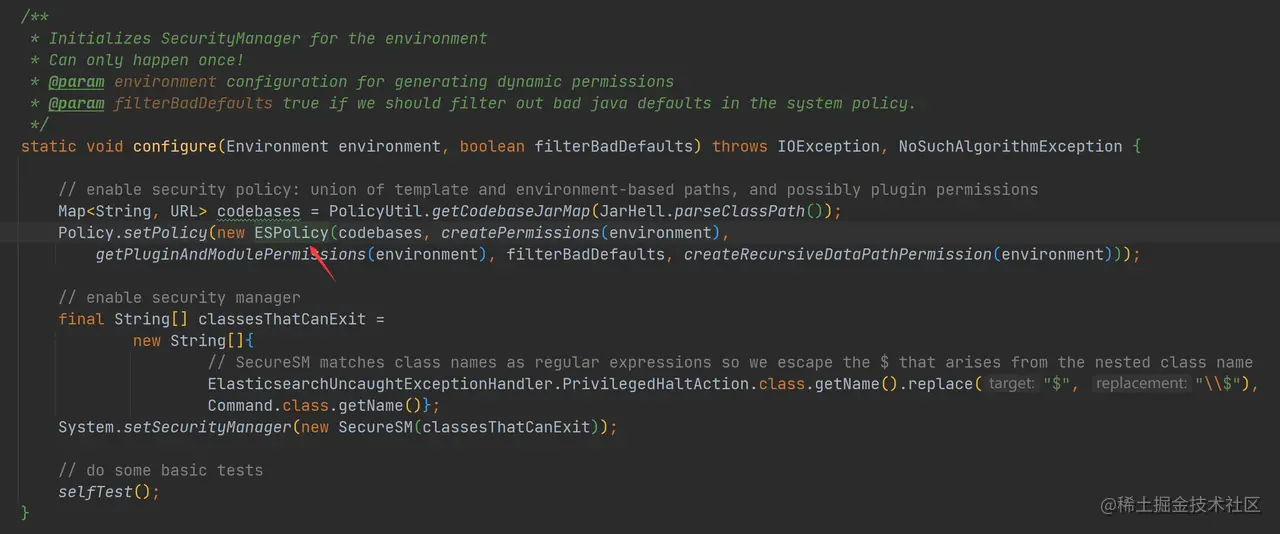
如上代码,通过调用 Policy.setPolicy 方法把 Policy 进行了重置,在 ESPolicy 中加载了 server\src\main\resources\org\elasticsearch\bootstrap\security.policy 文件。不知道你是否记得,在《源码阅读:源码阅读环境搭建》一章中,我们把 security.policy 文件中几个 codeBase 注释了,其实报错就是在这里抛出来的。
从 PolicyUtil.getCodebaseJarMap(JarHell.parseClassPath()) 可以看出,这里的 codebase 是针对 jar 包的,而这些 codebase 的来源在 JarHell.parseClassPath 中有说明:
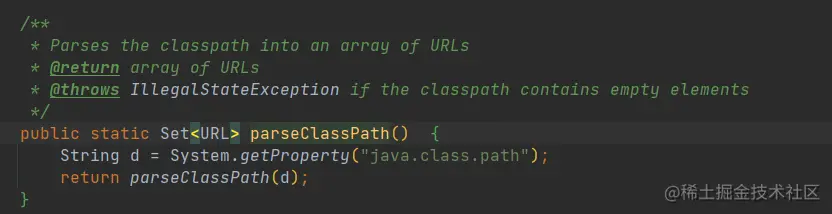
如上代码,codebase 的来源其实是在 “java.class.path”,也就是 “-classpath” 指定的。
但我们运行发行版的时候,加载的是 lib 目录里的 jar,而通过 idea 运行的时候加载的是 libs 里的是编译好的 class 文件:
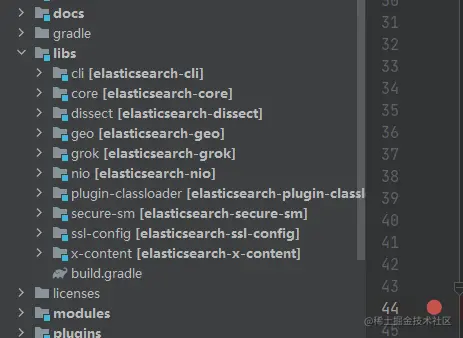
所以当我们在 idea 中运行时,抛出错误的原因是因为找不到对应的 jar,无法授权。
创建 Node 实例 根据加载的运行环境创建了 Node 实例,也就进行了第三阶段了。
启动节点
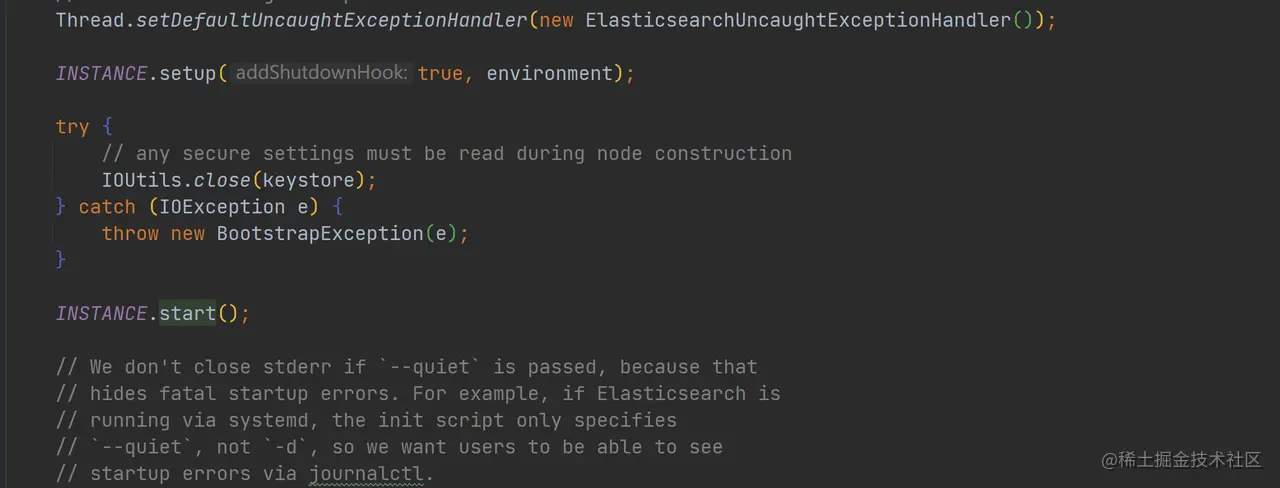
如上代码,在 Bootstrap.init 方法中,INSTANCE.setup 执行完后,会执行 INSTANCE.start(),其会执行上面创建的 Node 实例的 start 方法,启动节点。
- keepAliveThread.start 最后 INSTANCE.start() 方法会启动 keepAliveThread,防止 JVM 退出。
三、阶段三:启动节点实例
第三阶段主要有两个部分,一个是创建节点实例,另一个是调用 start() 方法启动这个节点实例。节点实例化的流程比较长,也比较复杂,其主要内容包括:
- 各种信息的打印输出和已经丢弃的旧版配置项的检查与提示。
- 启动插件服务,加载各个插件和模块。
- 创建节点的运行环境。
- 创建线程池和 NodeClient 来执行各个Action。
- 初始化 HTTP Handlers 来处理 REST 请求。
下面来看看整个节点实例化的流程。
- Override validateNodeBeforeAcceptingRequests

如上代码,创建的 Node 实例会重写 validateNodeBeforeAcceptingRequests 方法,主要做一些检查工作。进入 BootstrapChecks.check 方法可以看到,其主要是做一些 bootstrap checks 工作的:

如上代码,当系统不是监听 loopback 时会执行 bootstrap checks,如果 es.enforce.bootstrap.checks 配置项设置为 true,那将会强制执行 bootstrap checks。bootstrap checks 检查的项比较多,例如:HeapSizeCheck、FileDescriptorCheck 等,有兴趣的话可以深入这部分看看其实现。
- 设置节点的生命周期

创建 Lifecycle 实例的时候,其内部枚举成员 state 被设置了 State.INITIALIZED,此时节点处于初始化状态。节点状态的转换在 Lifecycle 类的注释中写得非常明白了,这里不再赘述。
- 各种信息的打印输出和已经丢弃的旧版配置项的检查与提示
这个没啥好说的,就是打印 JVM 相关的信息。
- 创建插件服务
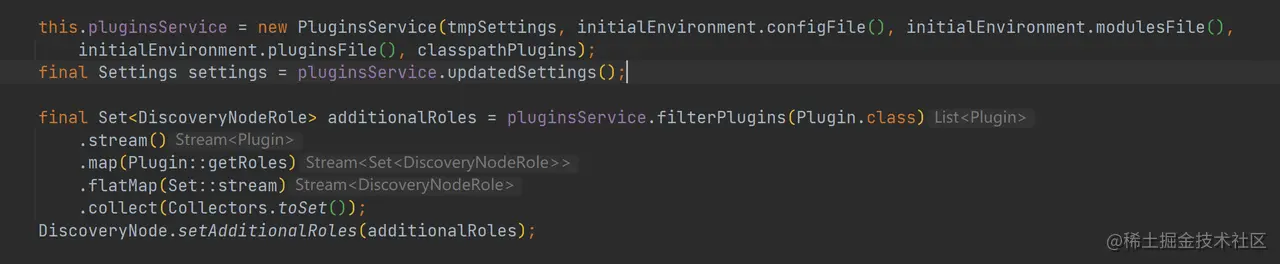
如上代码,此处创建了 PluginsService 实例。下面来看看 PluginsService 实例化的过程中做了些啥。
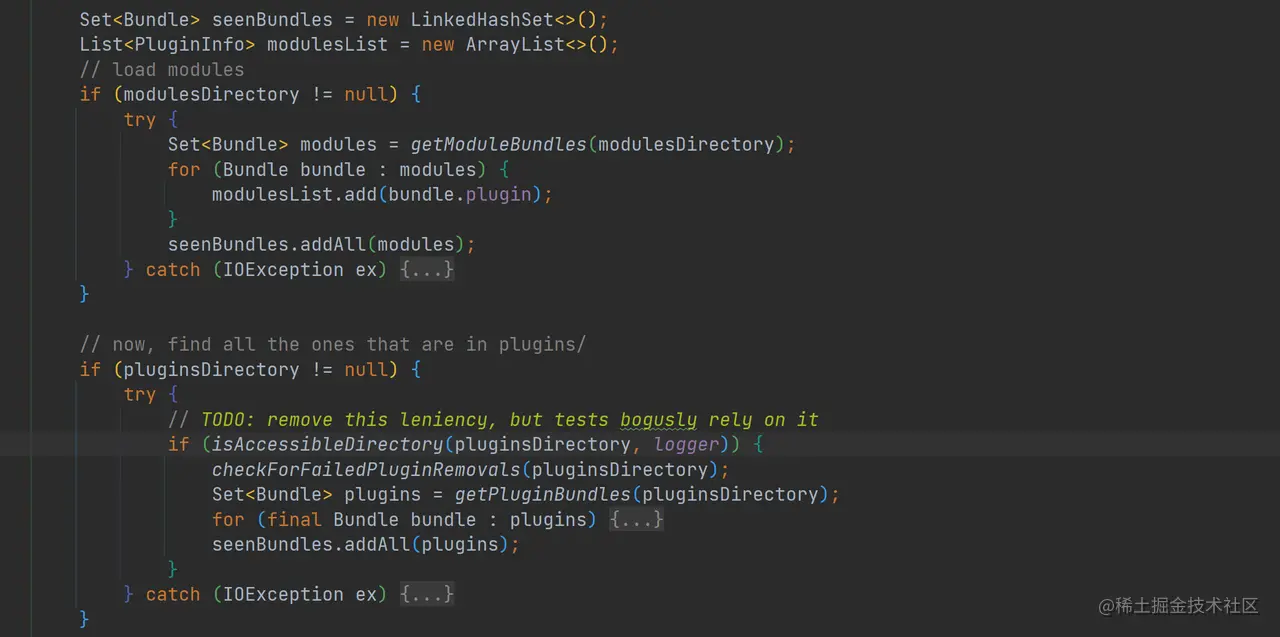
如上代码可以看到,PluginsService 实例化的过程中主要是加载 modules 目录中的模块和加载 plugins 目录中已经安装的插件。
此处我们重点关注模块加载的过程(插件的加载同理),通过跟踪 getModuleBundles 方法,其最终会调用 readPluginBundle 方法,并且其 type 为 “module” :
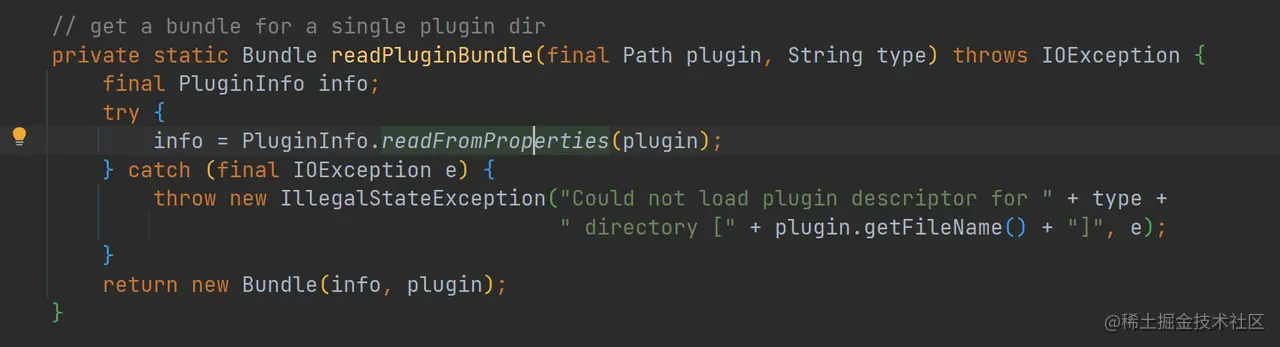
如上代码,最后 PluginInfo 的实例从 readFromProperties 构建出来,所以整个模块(或者插件)的加载其实是在 readFromProperties 函数中处理的:
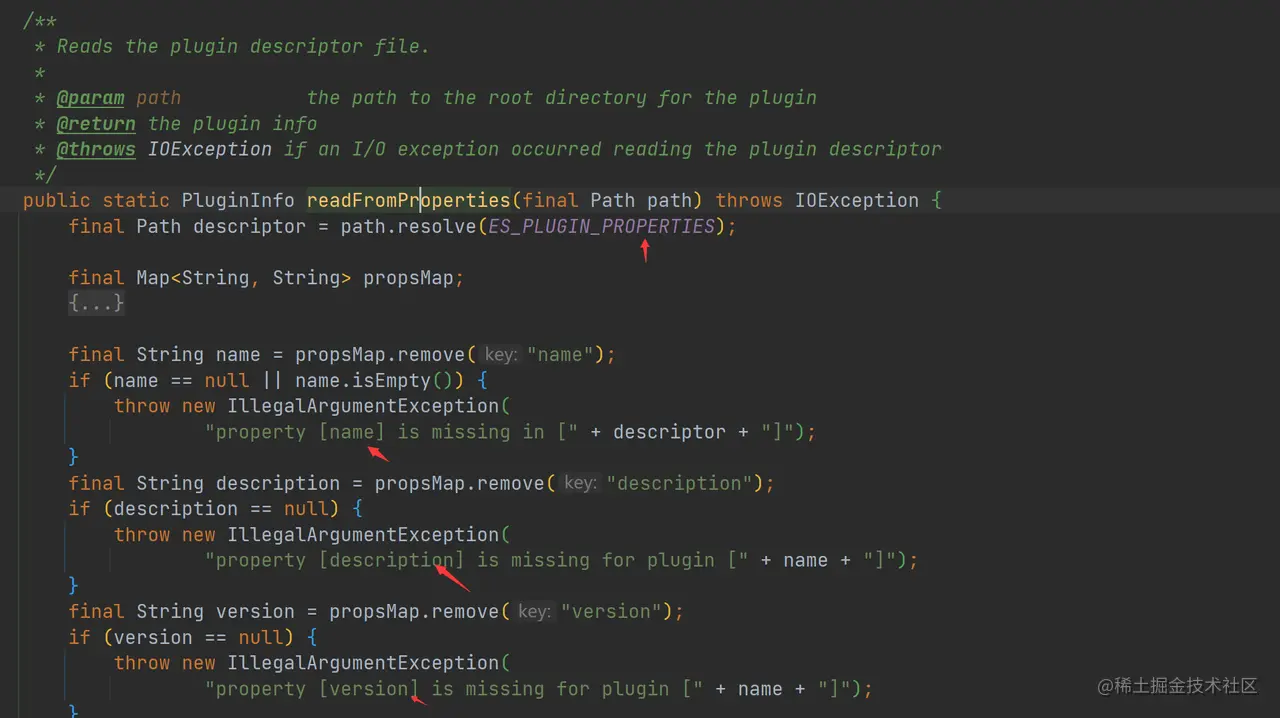
如上代码,插件或者模块有两个配置模板,用了两个全局变量进行定义:
/*** An in-memory representation of the plugin descriptor.*/public class PluginInfo implements Writeable, ToXContentObject {public static final String ES_PLUGIN_PROPERTIES = "plugin-descriptor.properties";public static final String ES_PLUGIN_POLICY = "plugin-security.policy";......}
其对应的是 modules 中每个模块的配置模板文件:

当然从名字可以看出,其实 ES_PLUGIN_POLICY(plugin-security.policy 文件) 应该是跟 SecurityManager 相关的。
所以,readFromProperties 函数最终读取 plugin-descriptor.properties 文件中的配置模板加载模块。配置的内容主要包括:type、description、version、name、classname 等信息,根据这些信息最终封装成为一个 PluginInfo 实例。
设置额外的节点角色 这部分没啥好说的,调用 DiscoveryNode.setAdditionalRoles 将对应的角色类型加入到 roleMap 中即可。
创建 NodeEnvironment
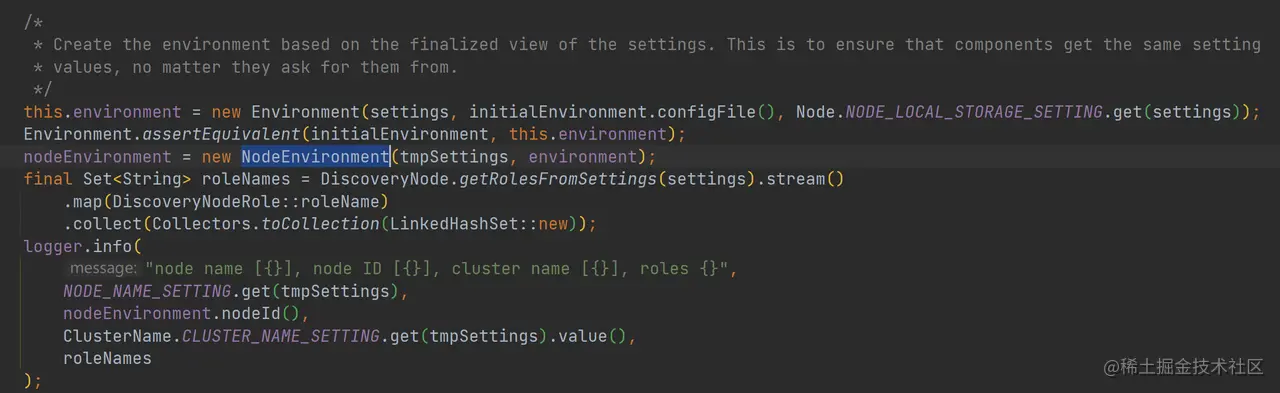
如上代码,通过 Environment 实例创建节点运行需要的运行环境:NodeEnvironment 实例。NodeEnvironment 实例化的过程会生成 NodeId,最后此处打印节点相关的信息。需要注意的是,此处会通过 Environment.assertEquivalent 函数来保证启动过程中配置没有被更改。
- 创建线程池

如上代码,ES 线程池 的实现封装在 ThreadPool 中。ThreadPool 中定义了 4 中线程池类型:

如上代码,线程池的类型有:
- direct,执行器不支持关闭的线程。
- fixed,线程池拥有固定数量的线程,当一个任务无法分配一条线程时会被排队处理。
- fixed_auto_queue_size,和 fixed 类似,但是任务队列会根据 Little’s Law 自动调整。8.0 后将被移除。
- scaling, 线程池中线程的数量可变,线程的数量在 core 和 max 间变化,使用 keep_alive 参数可以控制线程在线程池中的空闲时间。
更多关于线程池的类型可以参考官方文档。
ThreadPool 中还创建了多个线程池,主要有以下这些:
更多关于线程池的信息,可以参考官方文档,这里就不再展开了。
- 创建 NodeClient 实例
NodeClient 用于执行本地的 actions 的。action 的类型定义在 ActionType:
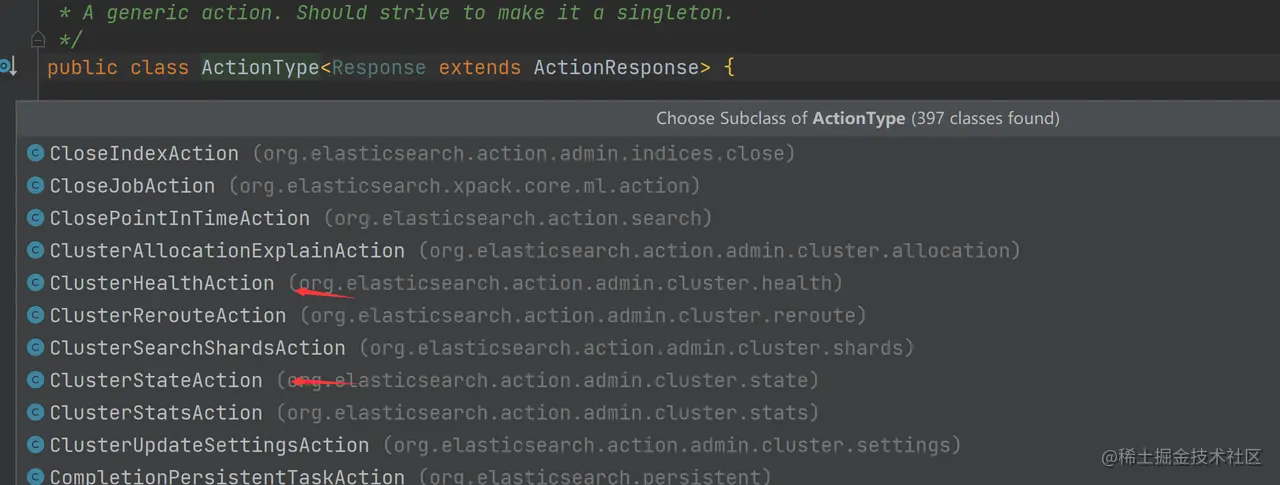
如上代码,可以看到有非常多的 Action 类型继承了 ActionType,已经标红了部分应该非常熟悉了吧?
- 创建各个模块和服务
之后就是各个模块和服务的创建部分,这部分内容太多,你可以慢慢看,这里不进行展开了。
- 绑定对应的对象到 Guice
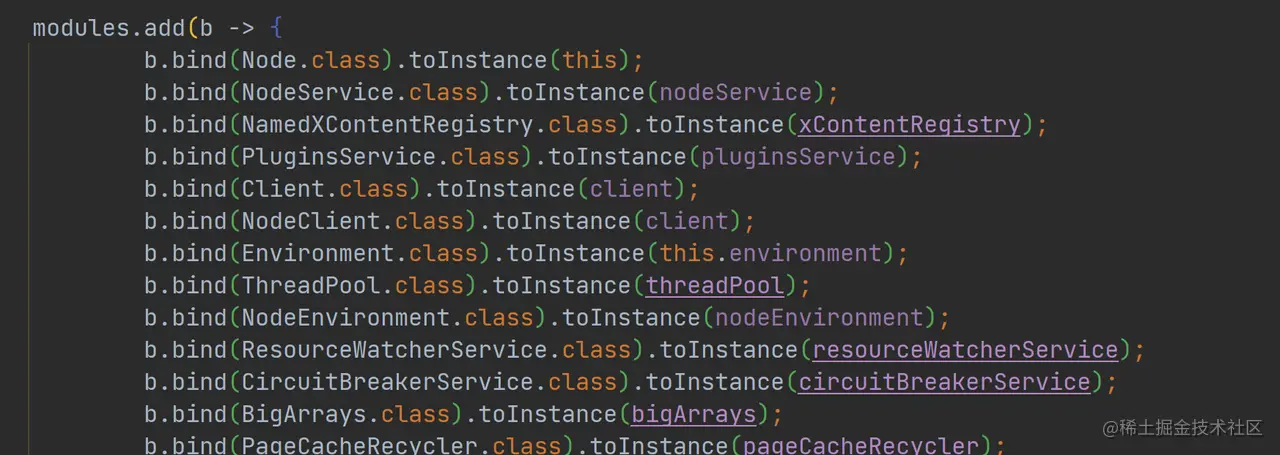
如上代码,将已经实例化的对象绑定到 ModulesBuilder 中,最后调用 modules.createInjector 创建 injector(注入器)。ES 用到了 Guice 这个谷歌提供的轻量级 IOC 库,bind 和 createInjector 是其提供的基本功能。
- 初始化 HTTP Handler

在这里主要是注册一堆 RestHandler,例如获取节点状态的 API 是在 RestNodesStatsAction 中定义的:
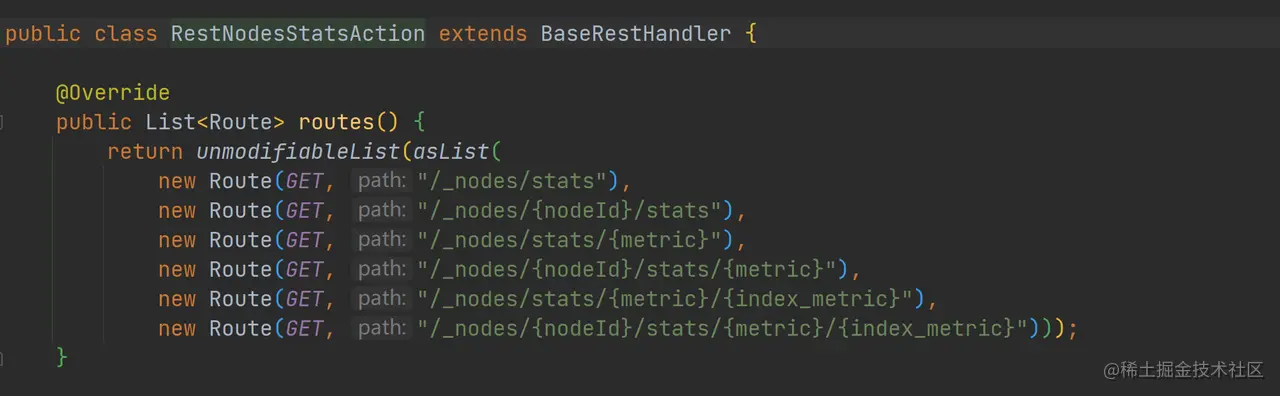
那一个 REST 请求是怎么被处理的呢?
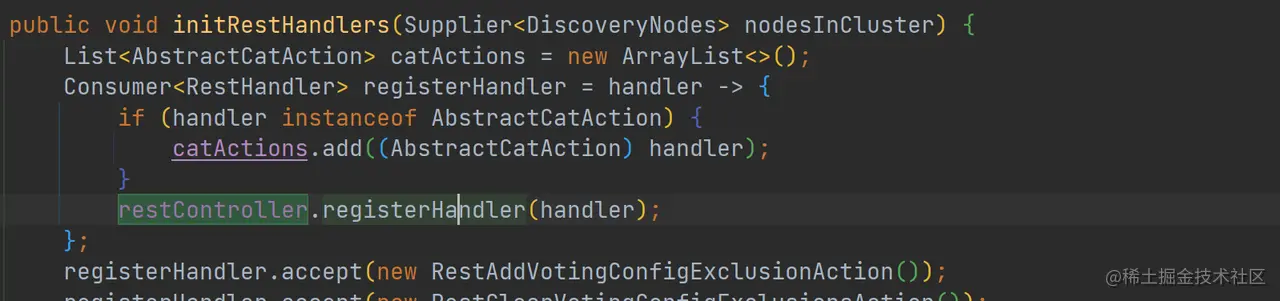
如上代码,通过 accept 方法,各个 RestAction 都被注册到 restController,Rest 请求都在 restController 中被处理。更多关于 RestController 的实现,你可以再深入研究。
ok,到这里,Node 的实例化过程就完结,在外部 将调用 Node.start 方法启动节点。
- 启动节点
最后在 Bootstrap.start 方法中调用了 Node.start 方法。Node.start 主要负责启动各个生命周期组件(LifecycleComponent)和从 Guice( 也就是 injector)中的获取各个需要启动的服务类实例,然后调用它们的 start 方法。
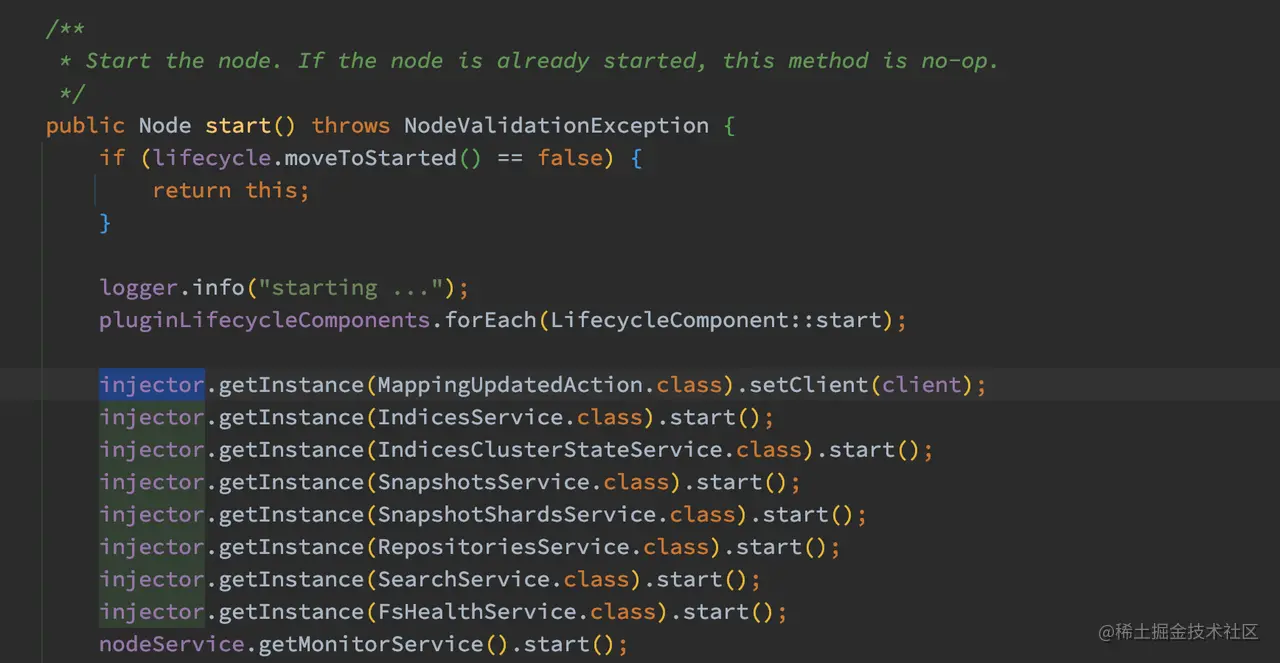
总结下来,Node.start 主要的实现的功能如下:
启动各个生命周期组件和服务,一些重点的服务如下:
| 服务 | 简介 | | —- | —- | | IndicesService | 负责索引管理,如创建、删除等操作。 | | IndicesClusterStateService | 负责根据各种集群索引状态信息进行相应的操作,如创建或者恢复索引(这些实际的操作会交给具体的模块实现)等。 | | SnapshotsService | 负责创建快照,在执行快照创建和删除的时候,所有的执行步骤都在主节点上=进行。 | | SnapshotShardsService | 此服务在 data node 上运行,并且控制此节点上运行中的分片快照。其负责开启和停止分片级别的快照。 | | RepositoriesService | 负责维护节点快照存储仓库和提供对存储仓库的访问。 | | SearchService | 提供搜索支持的服务。 | | ClusterService | 集群管理服务,负责管理集群状态、处理集群任务、发布集群状态等。 | | FsHealthService | 文件系统健康检查服务。通过创建一个临时文件来检查文件系统是否可写。 | | MonitorService | 负责提供操作系统、进程、JVM、文件系统级别的监控服务 | | NodeConnectionsService | 该组件负责维护从该节点到集群状态中列出的所有节点的连接,并在节点从集群状态中删除后断开与节点的连接。并且会定期检查所有链接是否在打开状态,并且在需要的时候恢复它们。需要注意的是此组件不负责移除节点! | | GatewayService | 网关服务,负责集群元数据的持久化和恢复。 | | Discovery | 节点发现模块是一个可插拔的模块,其负责发现集群中其他的节点,发布集群状态到所有节点,选举主节点和发布集群状态变更事件。 | | PeerRecoverySourceService | 负责处理对等分片的恢复请求,并且开启从这个源分片到目标分片的恢复流程。 | | TransportService | 负责节点间数据同步。 | | HttpServerTransport | 提供 REST 接口服务。 |
调用 ClusterService.setNodeConnectionsService 将 NodeConnectionsService 绑定到 ClusterService 中去。
调用 transportService.acceptIncomingRequests 尝试接收请求。
调用 discovery.startInitialJoin 开始进行加入集群的循环。
开启线程去检查是否有开源加入的集群:
如上代码,这里使用一个 CountDownLatch 来等待加入集群的结果。
- 开启 HttpServerTransport,并且绑定监听地址,接收 REST 请求。
好了,到此整个节点的启动已经完成了,如果顺利,将会看到以下的输出:
[2022-05-16T11:56:32,972][INFO ][o.e.n.Node] [node-1] started
四、集群启动流程
在了解了节点的启动过程后,我们从宏观的层面来看看集群的启动过程。要组建集群,首先肯定要选举出 Master,然后 Master 获取集群相关的元数据信息,然后执行 allocation 过程进行分片分配,最后执行 recovery 流程。
- Master 选举
根据前面的内容可知,Master 对集群的重要性,所以集群中多个节点启动后首要的任务是选举出一个 Master,有了 Master 后续的集群启动操作将由 Master 主导。
- 选择集群元数据
在 Master 被选举出来后,其首要任务就是要选择出集群的元数据信息,这部分的工作主要在 Gateway 模块中处理。Master 会向已经加入到集群的所有节点获取各种的元数据信息,然后选择出版本号最新的那个作为集群的元数据,并向所有节点进行广播。
- Allocation
在 allocation 过程中将会选择 shard 级别的元数据信息,并且构建内容路由表。在集群启动的时候,所有的 shard 都是未分配的,allocation 会决定哪个 shard 被分配到哪个节点,并且把这个关系记录下来写入到内容路由表。
我们知道 ES 的分片分为主分片和副分片,所以在分配的时候会先选择出主分片,然后再选择出副分配。
- 索引恢复(recovery )
为了保证数据的可靠性,在启动的时候主分片需要执行 recovery 流程来恢复没有来得及刷盘的数据。而副分片除了要恢复没有刷盘的数据外,还要恢复主分片已经写入但是副分片还没有写入的数据来保证数据的一致性。
集群的启动主要就是上述的几大流程,经过这些流程后,一般来说集群就可以提供对外的服务了。
五、总结
今天为你介绍了 ES 节点的启动过程和在宏观的层面简单介绍了集群的启动流程。
通过 Elasticsearch 这个类,系统进行了命令行参数解析与配置加载。通过 Bootstrap 类进行了资源检查与本地资源初始化。最后实例化了 Node 类,其负责加载各个模块和插件、创建线程池、创建 keepalive 线程等工作,在 Node.start 方法中获取了各个服务的实例并且调用它们的 start 方法。
总的来说,节点的启动流程是很复杂的,整个流程跟踪得非常累,一不小心容易陷入到其他流程分支去。而且有很多的类,ES 的开发者并没有很详细的注释其大致作用,让人很迷惑,必须读完其代码才能了解其大致的功能。
