除了可以承受更多的并发流量、存储海量数据外,分布式系统另外一个优点就是:利用数据备份来防止数据丢失。但也正是由于数据副本的存在,也引入了一些其他的问题,比如,如何选取主副本、复制数据时如何保证各个副本的数据一致性等。
为了解决分布式存储系统中数据复制的问题,微软提出了 PacificA 算法,而 ES 在数据副本模型的实现中正是参考了 PacificA 算法。因此,“数据不丢失的奥秘”这个主题将分为上、下两章,本章将为你介绍 PacificA 算法,而下一章将为你介绍 ES 数据副本模型的实现。
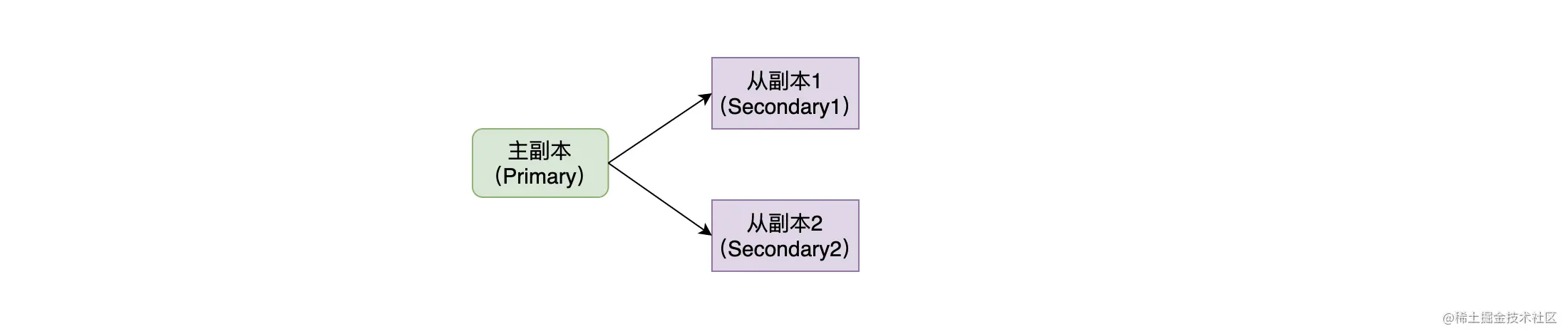
在开始下面的内容之前,先来明确一下副本的概念。如下图,在我们复制一份数据时,原数据称为主副本(Primary),复制出来的数据称为从副本(Secondary)。主副本和从副本统称为副本。
一、PacificA 算法简介
PacificA 是一个应用于主从复制的强一致性协议,其设计的目标是成为一个通用的、抽象的框架,并且模型的准确性能容易得到认证。但 PacificA 是一个适用于 LAN(Local Area Network)环境的协议,对跨机房的支持不太友好。
在了解 PacificA 的具体细节之前,先来看看 PacificA 定义的几个术语(这些术语及信息在后面的讲解中都会用到)。
- Replica Group:互为副本的集合称为副本组,每个副本组中只能有一个主副本(Primary),其他都只能是从副本(Secondary)。
- Configuration:配置信息保存了副本组的信息,每个副本组都有哪些副本,主副本是谁,从副本有哪些,这些副本都分配在哪个节点上。
- Configuration Version:配置信息也是有版本号的,每次更新配置信息时都会递增。如果某个节点发起要更新配置信息的请求,必须带上其配置信息的版本,当节点的配置信息版本与配置管理器的配置信息版本相同时才能执行操作。
- Serial Number(简称 SN) :为每个写入操作都赋予一个顺序号,每次写入时都会递增,其由主副本维护。
- Prepared List:写入操作的请求将会先存储到这个队列,并且按 Serial Number 排序。
- Committed List:已经提交的写入操作队列。
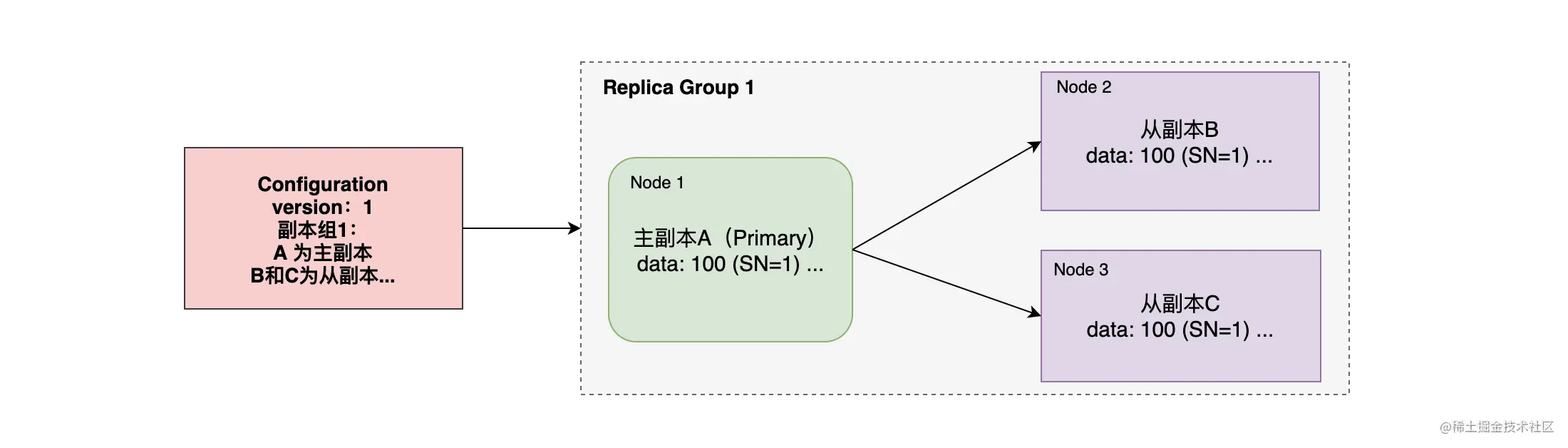
这几个术语大致的关系如上图,其中 Prepared List 和 Committed List 并没有画出,可以看到 Configuration 的管理和副本数据的存储是分开处理的。下面来了解一下 PacificA 系统框架是如何实现这两部分的。
二、PacificA 系统框架
PacificA 系统框架主要分为两个部分:一部分是负责配置管理的配置管理器,另一部分是负责数据存储、数据复制的存储集群。 为了简化读写强一致性的实现,PacificA 另辟蹊径,把数据的一致性和配置的一致性分开来处理。其中,使用配置管理器来管理配置并保证其一致性,而存储集群中副本间的一致性是通过主从式数据复制框架来保证的。
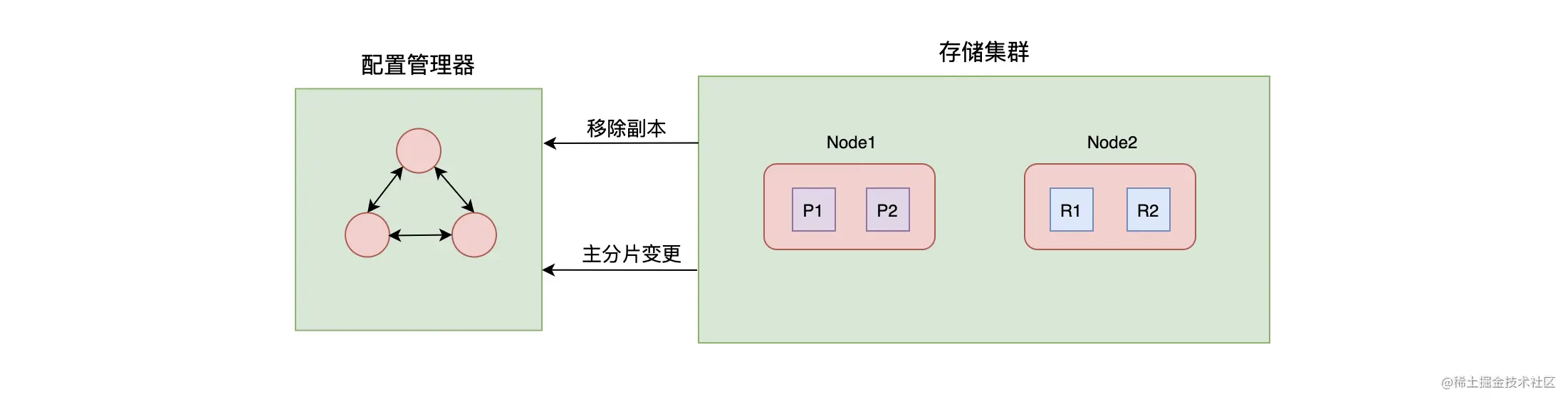
- 配置管理器使用单独一个集群来管理,其维护了副本组(Replica Group)信息,如分片有多少个副本、这些副本位于哪个节点上等信息。配置管理器是遵循其他强一致性协议来实现的,这么一看,一个强一致性协议的选主(这里选主指的是选举管理集群的 Master)过程使用另外一个强一致性协议来实现,多少有点不按套路出牌。但细想,这不正是突出了 PacificA 协议的重点是在于如何解决数据复制的问题上吗?
- 数据存储集群主要负责数据的读写、复制等操作。在数据存储集群中,数据的所有副本集合称为副本组,如图中 Node1 的 P1 和 Node2 的 R1 组成了数据的副本组,其中 P1 为主副本,R1 为从副本。在数据节点向配置管理器发起增加、移除副本的请求时,需要将节点当前配置的版本号带上,只有这个版本与配置管理器中的版本号一致时才能执行操作。执行成功后,配置的版本将会增加。
存储集群通过多副本的方式来保证数据的可用性、可靠性,而要实现多副本存储,就可能会产生数据不一致的问题,通过下面的内容我们来了解一下这些问题是如何被解决和如何做取舍的。
PacificA 的数据复制策略
在 PacificA 的数据复制框架中,数据要先写入主副本,然后再写入到其他副本中去。而当主副本下线时,会从其他副本中选择符合条件的副本来作为主副本。
数据写入的流程和数据复制策略如下:
- 主副本节点接收到写入请求后,会为此次写入操作分配 SN,然后把写入请求插入到 prepared list 中。其中 prepared list 中的记录是按照 SN 排序的。
- 主副本节点将写入请求和 SN 发送到其他副本节点,从副本节点收到写入请求后会插入到自己的 prepared list 中,成功后给主副本节点进行回复。
- 当主副本节点收到所有从副本的回复,并且确认所有的从副本都已经把写请求写入到自己的 prepared list 中,主副本把这写入操作插入到 committed list,committed list 向前移动。
- 主副本节点响应客户端,返回写入成功的消息,并且主副本会向所有返回响应的从副本发送一个 commit 的通知,告诉它们 commit point 的位置,各个从副本收到通知后会移动 commit point 到相同的位置。
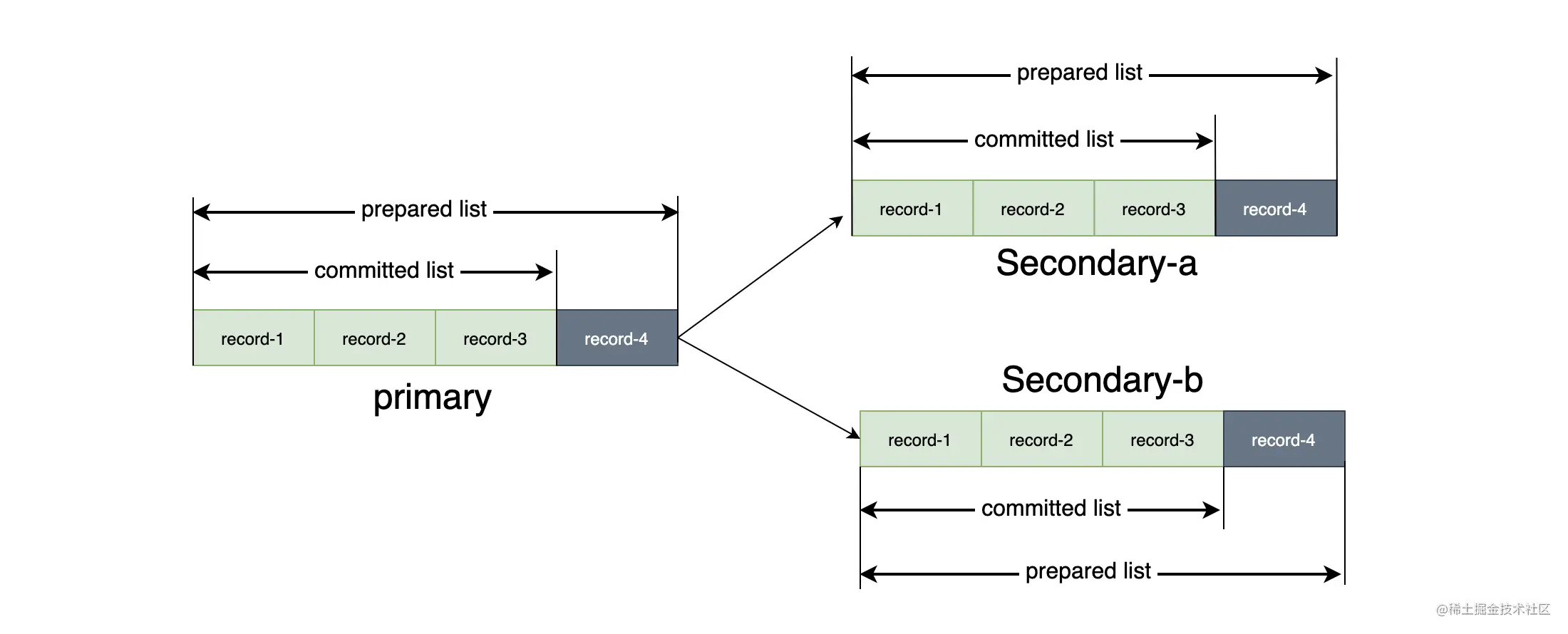
从整个过程中可以看到,主副本先 prepared,然后转发给从副本 prepared,主副本收到所有从副本回复后进行 committed, 最后再转发给所有从副本进行 committed。所以令 P 为主副本,R 为从副本,可以得出以下关系式:committed_R ⊆ committed_P ⊆ prepared_R ⊆ prepared_P。
保证主副本的唯一性
在现实的世界中,节点下线、网络分区等异常是普遍存在的,而 PacificA 的数据一致性是由主副本来维持,那么如何避免在异常环境中出现两个主副本就非常重要了。PacificA 使用了 lease(租约)机制来避免出现双主的情况。
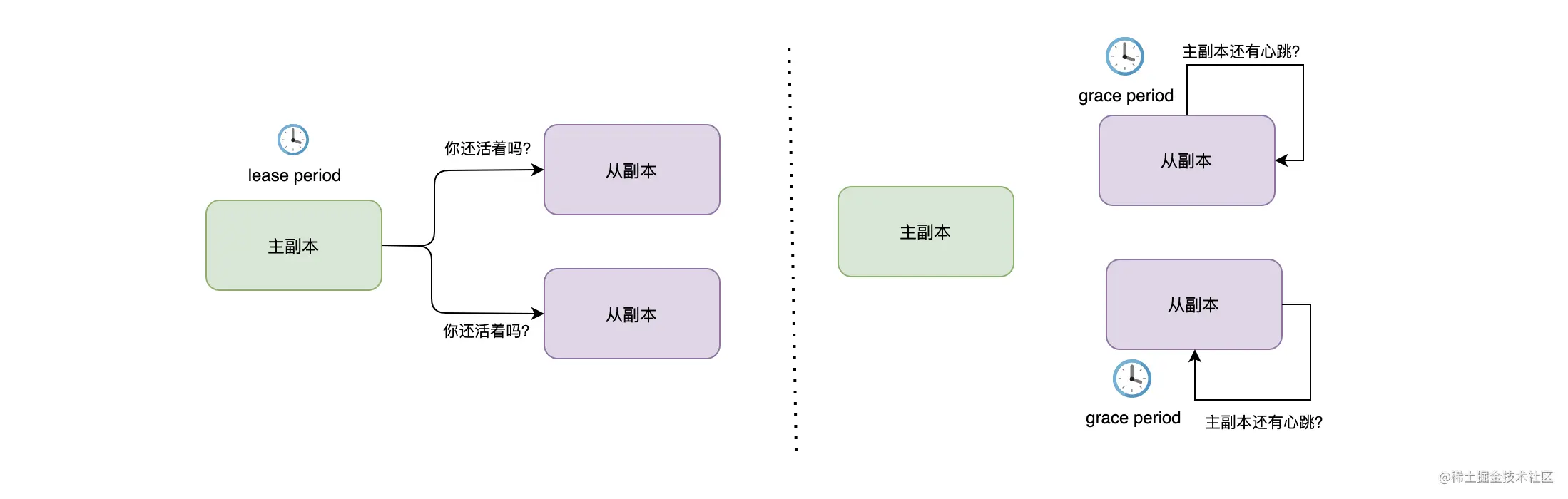
如上图,lease 机制主要说了这么一件事:主副本每隔一段时间(lease period)向副本组中所有从副本发起心跳请求并且等待响应来获取租约,而从副本则每隔一段时间(grace period)检查是否收到主副本的心跳请求。很明显这个过程中可能会有两种异常:
- 从副本异常 , 主副本没有收到从副本对心跳请求的响应;
- 主副本异常 , 从副本在 grace period 内没有收到主副本的心跳请求。
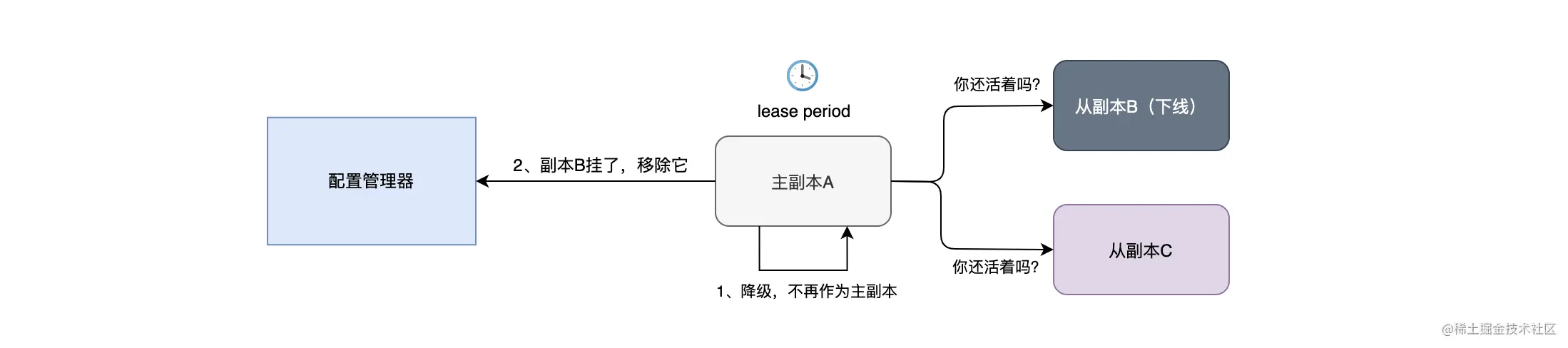
在从副本异常时,主副本会自动降级,不再作为主副本,停止处理读写请求,并且会向配置管理器汇报,将异常的副本从副本组中删除。如下图所示:
在从副本认为主副本下线时,从副本会向配置管理器汇报主副本发生异常,将主副本从副本组中移除,并且会请求提升自己为新一任主副本。在有多个从副本发起上述操作时,谁先成功谁就会成为新的主副本(First Win 原则)。如下图所示:
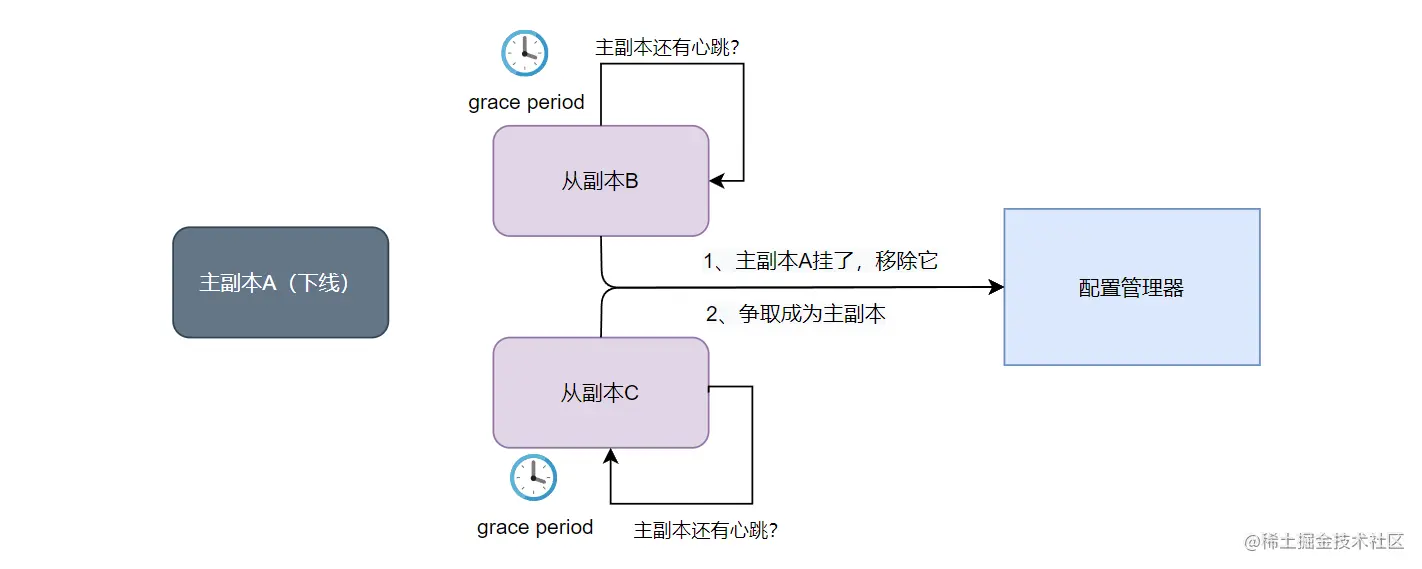
可以发现在 lease 机制下,主副本和从副本可以看作是“互相监督、互相举报”的,而配置管理器在响应“互相举报”时的策略是 First Win 原则。所以,如果没有时钟漂移,只需 grace period >= lease period,那么就可以保证主副本先于从副本知道有副本异常了,而且还可以保证在主副本降级后,各个从副本才去竞争成为主副本,从而避免出现两主副本的情况。需要注意的是只要主副本发生了变更,Configuration Version 就需要自增了,这样带有旧版本的配置变更请求就会被拒绝。
更改集群配置(Reconfiguration)
主从复制协议的复杂性在于其如何做 Reconfiguration,需要进行 Reconfiguration 的场景主要有 3 种,其中 2 种就是上面提到过的:Primary 故障、Secondary 故障,还有一种是加入新节点。
下面我们就来看看发生 Secondary 故障、新加节点、Primary 故障时,PacificA 是如何处理的。
- Secondary 故障
当 Secondary 发生故障时,主副本节点会向配置管理器发起 Reconfiguration 请求,将这个副本从 Replica Group 中移除(由于 grace period >= lease period,所以系统更倾向于由主副本发起 Reconfiguration 请求)。而当这个副本不属于 Replica Group 后,其无法承担读写操作,发起的 Reconfiguration 请求也不会被执行,所以无法对系统造成影响。
- 新加入节点
当有新节点要加入到 Replica Group 时,其需要先追平还没有同步的记录,然后才能申请成为从副本,主副本会向配置管理器发起 Reconfiguration 的请求,将这个从副本节点加入到 Replica Group 中。
如果这个节点之前在这个 Replica Group 中,那么这个副本已经提交的数据就肯定已经被提交了,但 prepared list 的数据就不一定被提交了,所以最简单的做法就是去掉没有被提交的数据,然后从 commit point 开始向主副本拉取数据。
- Primary 故障
当 Primary 发生故障时,由于从副本无法收到主副本节点的心跳请求,所以会向配置管理器发起 Reconfiguration 的请求,将主副本从 Replica Group 移除。而此时可能会有多个从副本进行这个操作,所以谁先成功,谁就会成为新的主副本。
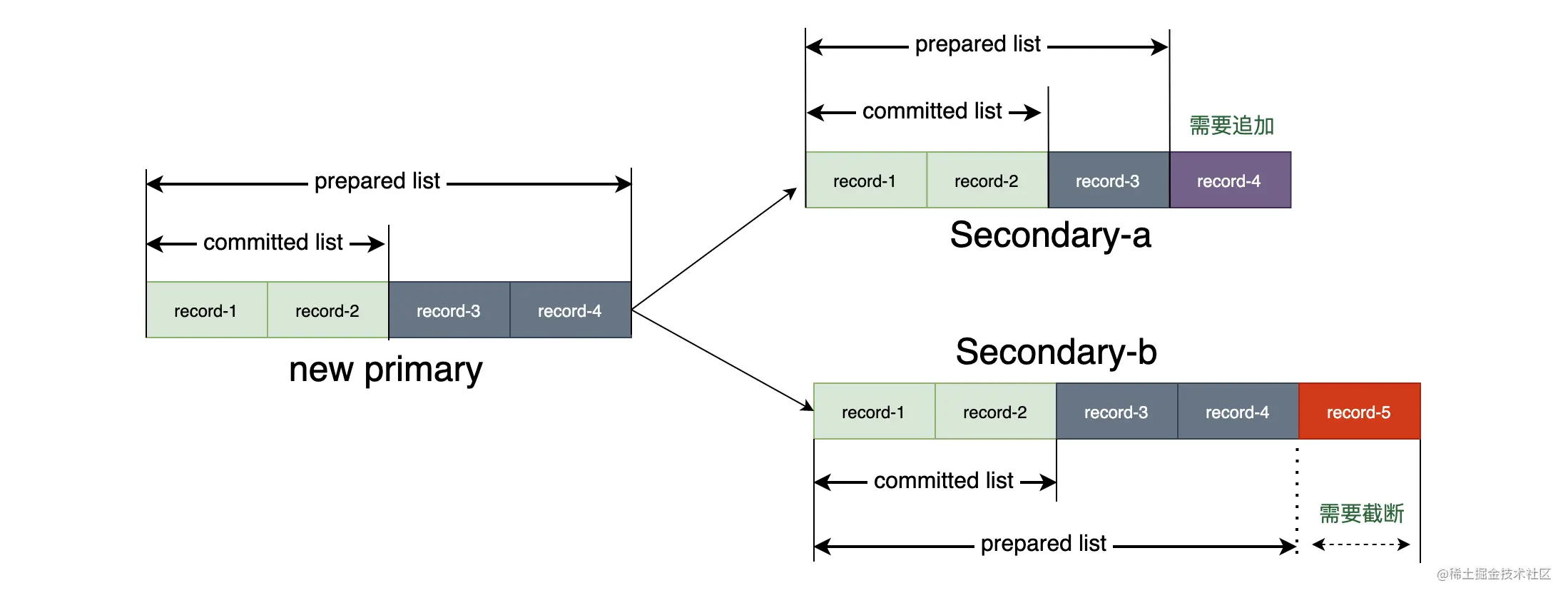
在确定了新主副本后,还要经过一个叫 reconciliation 的过程来保证新主副本和各个从副本间的数据一致性。新主节点会把自己 prepared list 上的操作与其他从节点进行对齐,对齐的条件要满足上面提到的关系式:committed_R ⊆ committed_P ⊆ prepared_R。如果从副本的 prepared list 数据落后则进行补齐,如果从副本的 prepared list 领先则截断超出的数据,如下图所示,这个过程相当于把没有 commit 的数据在所有节点上进行 commit 一次。
三、基于日志的数据同步方式
上面讨论的都是框架层面的内容,但并没有提及数据持久化和数据同步的细节,这里我们简单介绍下。
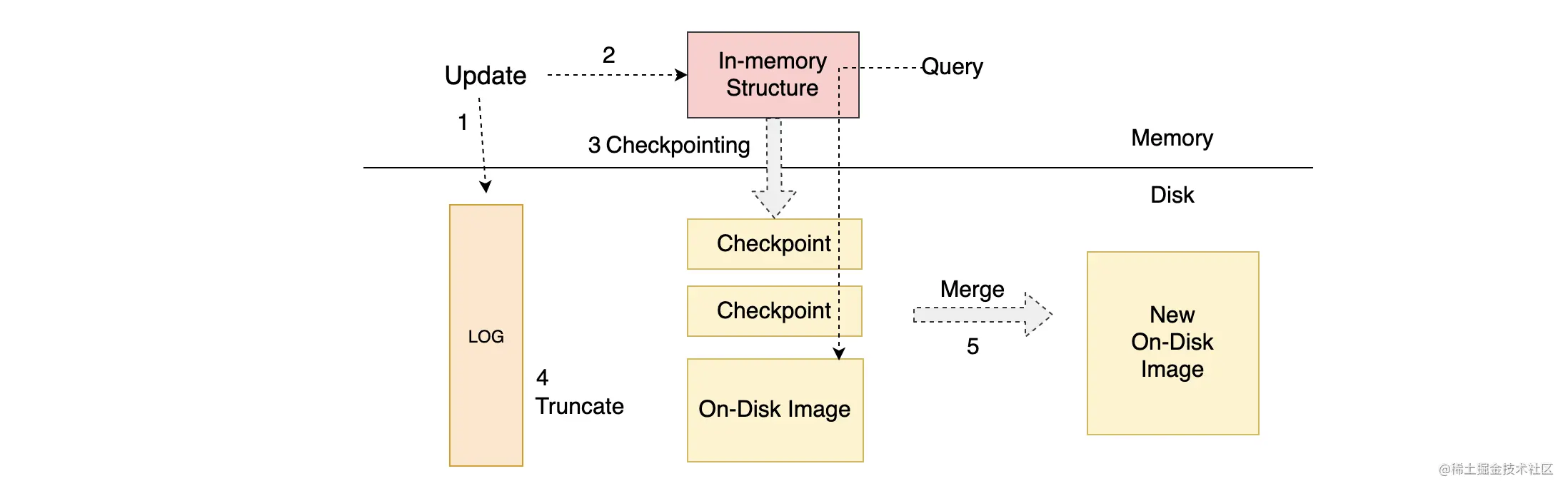
如上图,展示的是通用的以日志为基础的存储系统架构,主要包括 5 个步骤:
- 数据写入时先写日志,类似于 MySQL 中的 Binlog;
- 写日志成功后将数据写入到内存中,在系统重启时会重放日志来重建内存状态;
- 定时将内存中的数据写入到磁盘中,并记录 Checkpoint;
- 当 Checkpoint 生成后,日志中与 Checkpoint 相关的日志就可以被清理了;
- 由于 Checkpoint 过多,系统会定期将多个 Checkpoint 合并成一个 On-Disk Image。
可以在主从副本中维护这样一套相同的结构,然后通过同步日志到从副本,从副本应用同步过来的日志即可完成数据同步的操作。
如果你还记得 《数据持久化:分布式文档的存储流程》 中提及的数据存储流程的话,你会发现那个流程与上面 1~5 的步骤是很相似的。只不过 ES 写入数据时会先写 Lucene(内存),然后再写日志文件。这样做的好处是,写入 Lucene 时可以对数据进行校验,从而避免写入日志成功后,在写入 Lucene 失败时需要进行数据回滚的问题的出现。
四、PacificA 算法的总结
在这一讲中,我主要介绍了微软提出的强一致性主从复制算法:PacificA。
PacificA 主从复制框架主要由配置管理器和数据集群组成。其中,配置管理器负责维护副本组的信息,包括副本组中有多少个副本、每个副本在哪个节点上、谁是主副本等信息;而数据集群则采用主从复制框架来负责数据存取,从而保证数据的可靠性。
另外,我还介绍了 PacificA 的数据复制策略,因为数据写入时,需要先写入到主副本的 prepared list,然后再写入到从副本的 prepared list,在得到所有从副本的回复后,主副本才会写自己的 committed list,最后各个从副本写入自己的 committed list,所以推出了关系式:committed_R ⊆ committed_P ⊆ prepared_R(P 为主副本,R 为从副本)。其实也很好理解,越早写入的 list 越“大” 。
在如何避免出现多个主副本的问题中,PacificA 给出的答案是使用 lease 机制来解决,需要让 grace period >= lease period 来使主副本先于从副本知道有副本下线了。由于在租约到期后,从副本才会去申请成为主副本,所以可以确保在新主副本产生前,旧的主分片已经降级,从而不会产生两个主副本。
在系统运行中,有三种情况会触发 Reconfiguration,分别是:Primary 故障、Secondary 故障、加入新节点。Primary 故障和 Secondary 故障都会通知配置管理器把相应异常的节点移除,而在 Primary 故障时,重新选出来的主副本还需要经过 reconciliation 的过程来保证和各个从副本的数据一致后才能上线服务。
最后总结下来,PacificA 有以下三个鲜明的特点。
- PacificA 保证了数据读写的强一致性。
- PacificA 在实现上采取了配置管理和数据复制分离的形式,其中使用第三方一致性组件来管理配置,而数据复制策略采取了主从模式。
- 使用 lease 机制,主副本定期从各个从副本中获取租期,避免使用中心节点去轮询检查是否有节点下线,做到去中心化。
ES 在数据副本模型的实现中参考了 PacificA 算法,在熟读章后,下一章我们再来学习 ES 的数据副本模型。切记,如果本文没有熟读,不要轻易进入下一章节,不然无法保证你能看懂!!!更多关于 PacificA 的内容,你可以查阅 PacificA 的论文,毕竟原文 10 多页的论文很难用几千字来描述所有细节!
