我们知道 ES 是一个分布式搜索引擎,但其实 ES 也是一个分布式数据存储系统。对于一个数据存储系统来说,如何保证数据可靠性、提高读写吞吐量是重中之重,所以今天我们来了聊聊 ES 的数据存储过程。
通过本章的内容我们要搞清楚以下 3 个问题:
- 从集群的层面上看,数据写入主分片和副分片的流程是怎样的。
- 从分片的角度看,数据的索引过程是怎么样的。
- 从节点的角度看,数据是如何被持久化的。
一、文档分布式存储的流程
我们知道 ES 的索引有一个或者多个分片,而分片又分为主分片和副本分片两种。 那数据写入索引的过程是怎么样的呢?数据写入主分片和副分片的流程又是怎样的呢?
文档分布式存储首先需要找到能存储文档的主分片,并在主分片的节点上写入对应数据,数据在主分片写入成功后再将数据分发到副分片进行存储。文档的新增、更新、删除等操作都属于写入操作。单个文档的写入操作如下:
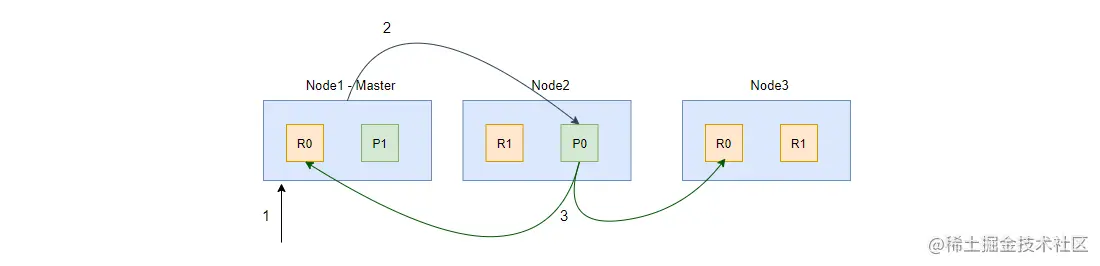
通过上图,可以看到写入一个文档的步骤如下:
- 如图中 1 阶段,客户端的请求到达 Node1,Node1 根据文档 ID 或者 routing key 来计算得出文档应该被保存到哪个分片(这里是分片 0),并且从集群状态的内容路由表信息中获取分片 0 所在的节点为 Node2;
- 如图中 2 阶段,Node1 将请求转发到 Node2 处理,Node2 执行写入操作;
- 如图中 3 阶段,如果写入成功,Node2 将写请求并发转发到 Node1 和 Node3,并且执行副本写入操作;
- 当所有副分片都写入成功后,Node2 会向协调节点(这里的 Node1)返回写入成功的信息,最后协调节点向客户端返回成功(为保持示意图的整洁,图中省略了此阶段)。
二、数据索引的流程
上面描述的文档写入操作的内容中,我们是从集群的角度来看的,而数据到达分片后需要对内容进行分词、索引数据等操作。ES 中的数据大致可以分为两种:
- 全文本,例如短信的内容、文章内容等;
- 精确值,如实体 ID、日期等。
在入库的时候精确值不需要进行分词处理,而全文本需要通过分词器进行分词处理。在查询的时候,对于精确值来说会比较二进制值,比较结果要么相等,要么不等;而全文查询呢,是无法给出准确的等或者不等的,只能说相似度怎么样,所以查询时会按相关性算分排序,算分越高相似度越高。
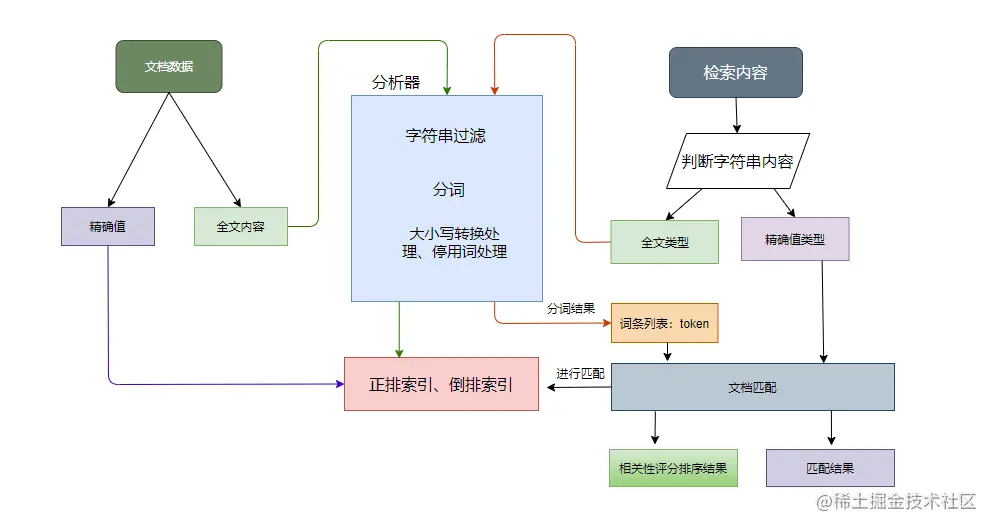
如上图,对全文本数据来说,数据索引时会对文本内容进行分析处理,分析器的处理流程如下:
- 先对字符串进行过滤,把一些 HTML、& 等字符处理掉;
- 分词器会将字符串按某些规律(空格、句号等)切分成单词,输出的这些单词为词条(token);
- 词条过滤器对切分后的词条进行过滤,例如过滤停用词(and、is 等),或者同义词转换等;
- 对过滤后的词条作进一步的处理,如小写转换、词根转换。
在搜索的时候如果是全文数据,会先生成词条列表,然后根据语法规则生成语法树进行查询,最后返回匹配度最高的文档列表。
到这里我们对文档的写入流程有个基本的了解了,那在数据到达分片后是怎么落盘的呢?如何保证数据不丢失的同时提高系统的吞吐量呢?请继续往下看!
三、数据持久化的流程
现在很多系统为了保证数据写入的吞吐量都做了特别的设计,而 ES 数据落盘主要有以下几个过程:Refresh、写 Transaction Log、Flush、Merge。 下面为你一一介绍。
近实时搜索的原因:Refresh
我们知道 ES 是一个近实时的系统,默认的情况下新写入的数据需要一秒后才能被搜索到。而近实时的原因其实跟 Refresh 有关。
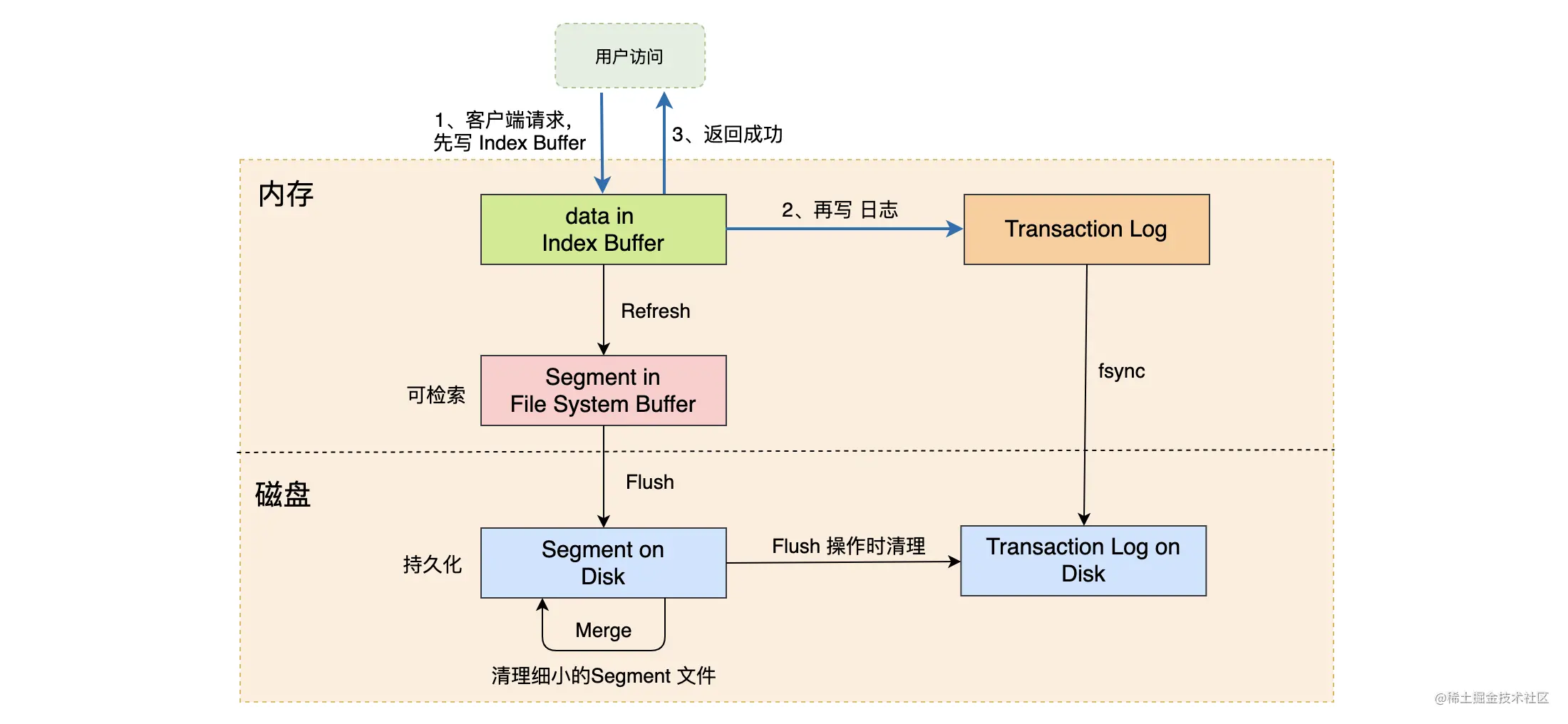
如下图,在文档写入的时候,ES 会将文档先写入到 Index Buffer 中,然后再将这些数据写入磁盘,并且清空 Index Buffer,每次写入磁盘的这批数据就是分段(Segment)了。一般情况下,写入操作只调用操作系统的 write 系统调用,而 write 函数只是将数据写入操作系统缓存中而已,如果此时断电,这部分数据是可能会丢失的。先写 Index Buffer 的策略可以大幅提升系统的写入效率,而在 write 系统调用完成后,这部分存在于操作系统缓存中的数据就可以被检索到了。
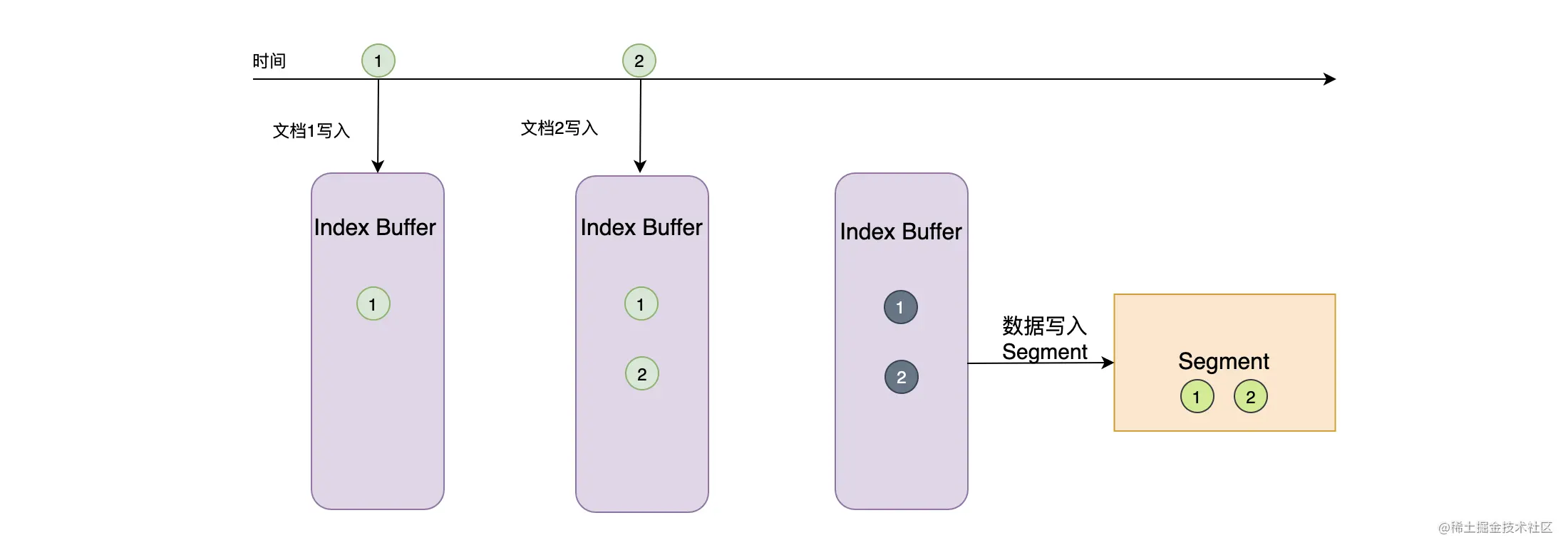
如上所述,我们将 Index Buffer 的内容写入到文件生成 Segment 的过程称为 Refresh,Refresh 不会调用 fsync 进行刷盘操作。
默认的情况下,Refresh 会一秒执行一次,可以通过 index.refresh_interval 配置进行调整。或者在 Index Buffer 被写满的时候,就会触发 Refresh,而这个 Buffer 的容量默认为 JVM 的 10%。 随着时间的推移,系统中会有越来越多的 Segment 文件,这个时候就需要将这些文件进行合并了(参见下面所讲的 Merge)。
通过 Refresh 的机制可以看到,其实 ES 是一个近实时的系统,文档写入成功后,默认的情况下,需要一秒后才能被查询到。所以当你有先写入然后马上再查询数据的业务需求时(写入数据后马上回到列表页并且进行检索数据),一定要注意这个问题!
很不幸的是,Index Buffer 的机制虽然可以提高系统的写入吞吐量,但是却带来了数据丢失的风险。这时候怎么办呢?系统是使用 Transaction Log 来解决这个问题的。
防止数据丢失:Transaction Log
上面提到过,在默认的情况下,文档写入时数据是没有刷盘的,所以存在数据丢失的风险。为了防止数据丢失,在文档写入的时候不仅需要写 Index Buffer,而且还会写 Transaction Log 文件。而在当前的版本中,Transaction Log 默认是刷盘的。每个分片都会有自己的 Transaction Log,在 Refresh 的时候系统会清空 Index Buffer,但不会清空 Transaction Log。重启的时候系统会从 Transaction Log 中恢复数据,从而防止数据丢失。
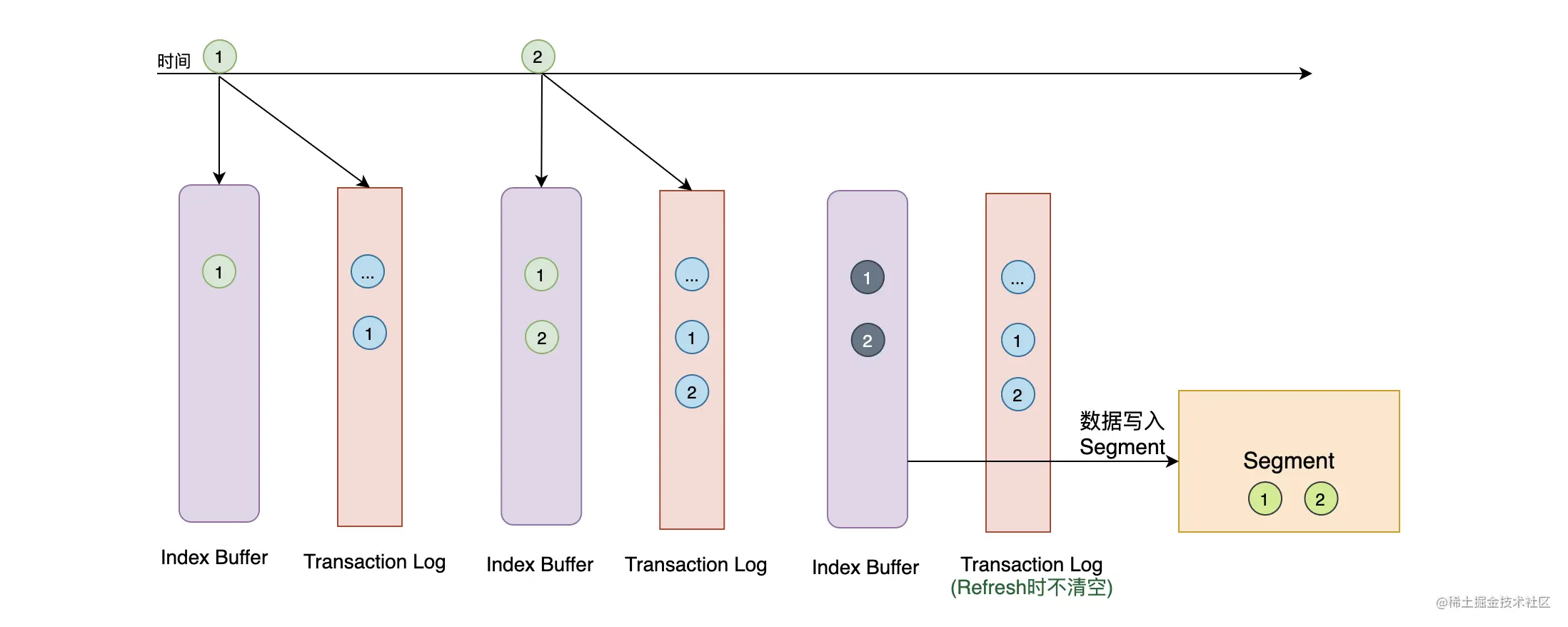
那你可能会问,ES 在文档写入的时候先写 Index Buffer 和 Transaction Log 到底有什么意义呢?而且 Transaction Log 是默认刷盘的不会很慢吗?写 Index Buffer 你可以认为是使用内存将一批数据缓存下来,然后再一次性批量写磁盘、索引数据。这个设计肯定是非常快的,比一条条写磁盘效率高得多,而且一条数据创建一个 Segment 文件多少有点浪费。其实写 Index Buffer 就是写 Lucene,这期间做了很多数据校验的操作,所以先写 Index Buffer 的另一个好处是为了减少写入失败时产生回滚。
每次写入一条文档就要写一次 Transaction Log,其实现在非常多系统都是这样来做事务日志记录的,Transaction Log 是顺序写的,速度比较快,而要做事务日志这部分数据必须进行刷盘进行持久化。但不管怎么样,毕竟要写磁盘,还是有点慢的!
持久化操作:Flush
通过调用 Flush 操作,ES 可以将操作系统缓存中的数据刷写到磁盘上。ES 的 Flush 操作会触发 Refresh,将当前 Index Buffer 中的数据写入到操作系统的缓存中,然后再调用 fsync 将操作系统缓存中的数据刷盘,并且 Flush 还会清空 Transaction Log。因为需要刷盘,所以 Flush 的操作是比较耗时的。Flush 的两个触发点如下:
- 默认 30 分钟调用一次;
- Transaction Log 的默认容量为 512M(由 index.translog.flush_threshold_size 控制),在 Transaction Log 被写满的时候会触发 Flush。
Segment 文件的清理:Merge
在每次 Refresh 后都会创建一个新的 Segment 文件,在分段文件过多时候会带来一些问题,这些分段文件都要消耗文件句柄和内存,每次搜索都要检查每个段然后再合并结果,于是段越多、搜索也越慢。所以需要通过一定的策略将这些小的段文件合并为较大的段,并且合并的过程中会将文件中标记删除的数据过滤掉,合并结束后会将旧的数据文件删除,这个时候被标记删除的数据才真正从磁盘上删除。所以我们删除文档后会看到磁盘空间并不是立刻释放的。
ES 和 Lucene 会自动执行 Merge 操作,当然用户也可以手动触发合并操作:
bash
复制代码
POST you_index/_forcemmerge
通过 Refresh、写 Transaction Log、Flush、Merge 等操作,系统将用户写入的数据完成了缓存和落盘的操作。为了方便大家理解和记忆,我整理了下图:
四、总结
今天主要为你介绍了 ES 的数据存储过程。
从集群的角度来看,数据写入会先路由到主分片,在主分片上写入成功后,会并发写副本分片,最后响应给客户端。
从分片的角度来看,数据到达分片后需要对内容进行格式校验、分词处理然后再索引数据。
从节点的角度来看,ES 数据持久化的步骤可归纳为:Refresh、写 Transaction Log、Flush、Merge。
默认的情况下,系统会每一秒执行一次 Refresh 操作把 Index Buffer 的数据写入磁盘中,但不会调用 fsync 刷盘。 ES 提供近实时搜索的原因是因为数据被 Refresh 后才能被检索出来 。
为了保证数据不丢失,在写完 Index Buffer 后,系统还有写 Transaction Log。Transaction Log 的写操作是顺序写的,并且默认是调用 fsync 进行刷盘的。
Flush 操作会将操作系统磁盘缓存持久化到磁盘中,默认 30 分钟或者在 Transaction Log 写满时触发执行。Flush 将磁盘缓存持久化到磁盘后,会清空 Transaction Log。
最后 ES 和 Lucene 会自动执行 Merge 操作清理过多的 Segment 文件,这个时候被标记为删除的文档会正式被物理删除。
那为啥 ES 可以保证数据的可靠性呢?其实,一方面,ES 的分片有副本冗余,并且进行分布式存储。另一方面,通过数据持久化步骤可以保证数据在分片写入时不丢失。另外,ES 通过先写 Index Buffer 后写 Transaction Log 的方式也保证了写入的吞吐量不会太差。
