在前面的内容中,我们已经创建和删除过索引了,今天我们将会介绍更多关于索引管理的 API 和其使用示例。
索引管理的 API 提供了单个索引的管理(创建和删除)、别名管理、索引设置、定义 Mapping、Reindex、索引模板、索引收缩等功能。今天我们来看看这些功能的 API 示例。
一、单个索引的管理(索引创建和删除)
1. 创建索引
我们之前学习的内容就已经有索引创建的示例了,下面再来复习一下:
# 创建索引的最基本形式,没有指定 MappingPUT test_index# 创建带 setting 和 Mapping 的 books 索引PUT books{"mappings": {"properties": {"book_id": {"type": "keyword"},"name": {"type": "text"}}},"settings": {"number_of_shards": 3, # 指定了 3 个主分片"number_of_replicas": 1 # 指定了一个副本分片}}
创建索引的限制有以下几个:
- 只能是小写字母。
- 不能包含 \,/,*,?,”,<,>,|,(空格),,,#等字符。
- 7.0 之后的版本不能再包含 : (冒号)字符了。
- 不能以 -,_,+ 开头。名字不能是 . 或者 ..。
- 不能长于 255 字节。需要注意的是某些字符是需要多个字节来表示的。
2. 索引删除
索引删除比较简单,我们之前一直有用到了,其示例如下:
# 删除一个索引DELETE test_index# 结果:{ "acknowledged" : true }
二、索引别名管理
当我们业务需求发生改变,而不得不创建一个新索引来代替旧索引的时候,我们必须更新应用服务的索引名称,使用索引别名可以解决这个问题。假设应用中用 test 别名指向旧索引 test_old,在创建新索引 test_new 并将 test_old 的数据迁移到 test_new 后,我们可以将 test 索引别名指向 test_new,这样可以做到在新旧索引间的无缝切换。 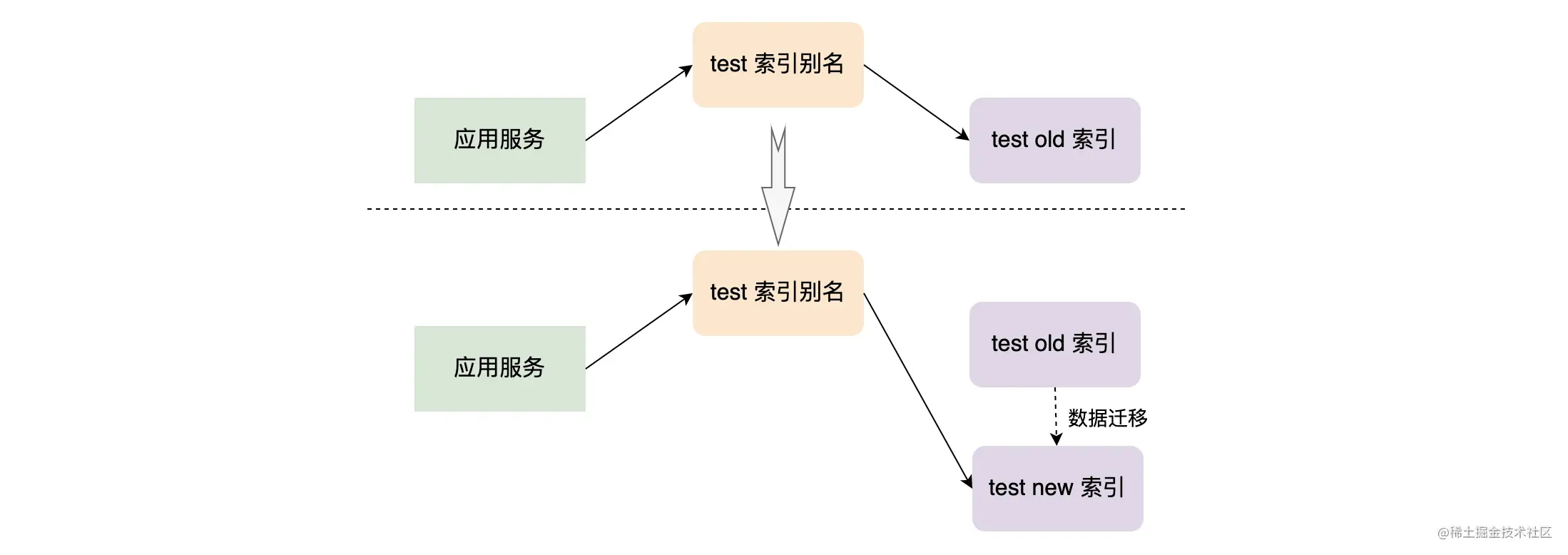 别名就是一个索引另外的名字,其就像一个软连接或者快捷方式。每个索引可以有多个别名,而不同的索引也可以使用相同的别名,这样使得不同的别名可以适用于不同的情景。
别名就是一个索引另外的名字,其就像一个软连接或者快捷方式。每个索引可以有多个别名,而不同的索引也可以使用相同的别名,这样使得不同的别名可以适用于不同的情景。
下面是别名创建、删除、重命名、关联多个索引的示例,更多的别名使用示例请参考官方文档:
1. 别名创建示例
POST /_aliases{"actions" : [{ "add" : { "index" : "test1", "alias" : "alias1" } }]}
如上示例(官方示例),为 test1 索引创建了 “alias1” 别名。
2. 别名删除
POST /_aliases{"actions" : [{ "remove" : { "index" : "test1", "alias" : "alias1" } }]}
如上示例(官方示例),删除了索引 test1 的别名 “alias1”。
3. 别名重命名
POST /_aliases{"actions" : [{ "remove" : { "index" : "test1", "alias" : "alias1" } },{ "add" : { "index" : "test1", "alias" : "alias2" } }]}
如上示例(官方示例),别名重命名的操作是先将原先的别名删除了,然后再创建新的别名。这操作是原子的,不需担心别名不指向索引的短暂时间。
4. 关联多个索引
POST /_aliases{"actions" : [{ "add" : { "indices" : ["test1", "test2"], "alias" : "alias1" } }]}
如上示例(官方示例),将别名 alias1 指向了索引 test1、test2 。
三、索引设置
在创建索引的时候,可以在 “settings” 字段中指定索引的设置。number_of_shards 和 number_of_replicas 是索引非常重要的两个配置,设置它们值的示例如下:
PUT test_index{"settings": {"number_of_shards": 3, # 指定了 3 个主分片"number_of_replicas": 1 # 指定了一个副本分片}}
如上示例,我们设置了 test_index 索引有 3 个主分片,每个主分片一个副本分片。
可以动态修改索引的配置,其示例如下:
PUT /test_index/_settings{"number_of_replicas": 2}
如上示例,我们设置了索引 test_index 拥有 2 个副本分片。但需要注意的是,number_of_shards 设定后是无法改变的,要修改索引的分片数量可以通过 Reindex API 或者收缩索引的 API 做处理。
四、定义索引的 Mapping
在创建索引的时候可以设置索引的 Mapping。其示例如下:
PUT test_index{"mappings": {"properties": {"test_id": {"type": "keyword"}}}}
如上示例,使用 “mappings” 字段可以指定创建索引时的 Mapping 设置。
如果增加了某些需求,想要增加索引 Mapping 的设置,其示例如下:
PUT test_index/_mapping{"properties": {"test_name": {"type": "keyword"}}}
需要注意的是,在 Mapping 中已经定义好的字段是不能修改的,如果尝试修改将会返回以下结果:
# 尝试修改 test_name 的类型为:textPUT test_index/_mapping{"properties": {"test_name": {"type": "text"}}}# 结果,http 状态码为 400{"error" : {"root_cause" : [{"type" : "illegal_argument_exception","reason" : "mapper [test_name] cannot be changed from type [keyword] to [text]"}]},"status" : 400}
五、Reindex API
上面提到,如果 Mapping 中字段已经定义就不能修改其字段的类型等属性了,同时也不能改变分片的数量,如果需求上必须要我们修改的时候怎么办呢?可以使用 Reindex API 来解决这个问题。
我们需要先创建一个新的索引,使其 Mapping 等设置满足新的需求,然后将数据从旧的索引中迁移到新的索引。Reindex API 的使用示例如下:
# 删除索引,如果存在的话DELETE test_index# 创建索引PUT test_index{"mappings": {"properties": {"test_id": { "type": "keyword" },"test_name": { "type": "keyword" }}}}# 插入数据PUT test_index/_doc/1{"test_id": "123","test_name": "name tes"}# 创建新的索引,并且满足需求PUT test_index_reindex{"mappings": {"properties": {"test_id": { "type": "keyword" },"test_name": { "type": "text" }}}}# 执行 reindex 操作POST _reindex{"source": { "index": "test_index" },"dest": { "index": "test_index_reindex" }}# 在迁移数据后的 test_index_reindex 索引中获取数据GET test_index_reindex/_doc/1
如上示例,我们先创建一个索引 test_index 作为 reindex 操作的源索引,并且写入数据,然后再创建一个新的索引 test_index_reindex 作为 reindex 操作的目标索引。可以看到 test_index 和 test_index_reindex 的差别是 test_name 字段的类型不同了。最后在执行 reindex 完成后,可以在 test_index_reindex 中查询到我们写入的数据。
需要注意的是,如果索引中的数据很多,并且是需要同步返回的情况下,在 Kibana 中执行这个操作可能会发生超时的现象。可以使用 wait_for_completion=false 参数来进行异步操作,其示例如下:
# 异步地执行 _reindexPOST _reindex?wait_for_completion=false{"source": { "index": "test_index" },"dest": { "index": "test_index_reindex" }}# 结果{"task" : "26d0dAjcRYygigd0shfz5w:35995695"}
如上示例,异步的 reindex 操作返回的结果将会是个 task_id,可以使用 Task API 查看这个任务的情况:
GET /_tasks/26d0dAjcRYygigd0shfz5w:35995695
Reindex API 还提供很多丰富的参数和操作示例,你可以参考官方文档。
六、索引模板
可以使用 Index templates 按照一定的规则对新创建的索引进行 Mapping 设定和 Settings 设定。需要注意的是,索引模板只在索引被新创建时起作用。创建一个模板:
PUT /_index_template/my_tmp1{"index_patterns" : ["tmp_*"], # 以tmp_ 开头的索引都引用这个模板"priority" : 1, # 指定优先级, 数值越大优先级越高, 这个模板就越先被应用"template": {"settings" : {"number_of_shards" : 3},"mappings": {"date_detection": false}}}
如上示例,我们创建了一个索引的模板,当以后有 tmp_ 开头的索引创建时都引用这个模板,会设置 number_of_shards 为 3 和 Mapping 中的 date_detection 为 false。
模板中的 “priority” 指定了模板的优先级,其数值越大优先级越高,这个模板就越先被应用。
七、打开和关闭索引
当我们需要执行某些操作的时候,需要关闭索引或者打开索引,可以使用 _close API 和 _open API 来关闭或者打开索引。
关闭索引的操作开销很小,并且会阻塞读写操作,关闭后的索引不再允许执行打开状态时的所有操作。关闭和打开一个索引的示例如下:
# 关闭索引POST /test_index/_close# 打开索引POST /test_index/_open
八、判断索引是否存在
当我们需要知道一个索引是否存在的时候,可以使用 Exists API 来判断索引是否存在,其示例如下:
HEAD test_index
如上示例,如果索引存在,那么返回的 HTTP 状态码为 200,不存在的话为 404。更多关于 Exists API 的使用示例,可以参考官方文档。
九、收缩索引
如果我们一开始创建的索引其分片太多,可以使用收缩索引的 API 将索引收缩为具有较少主分片的新索引。
收缩后的新索引的主分片数量必须为源索引主分片数量的一个因子,例如,源索引的主分片分配了 12 个,那么收缩后的新索引的主分片数只能为 1、2、3、4、6。
在进行索引收缩前需要进行以下操作:
- 源索引必须只读。
- 源索引所有的副本(主分片也行,副分片也行)必须在同一个节点上,也就是在这个节点上必须有这个索引的所有数据,不管分片数据是主分片的还是副分片的。
- 源索引的状态必须为健康状态(green)。
下面的示例我们将拥有 12 个主分片、2 个副本分片的索引(test_index)收缩为拥有 3 个主分片和 1 个副分片的索引(test_index_new)。
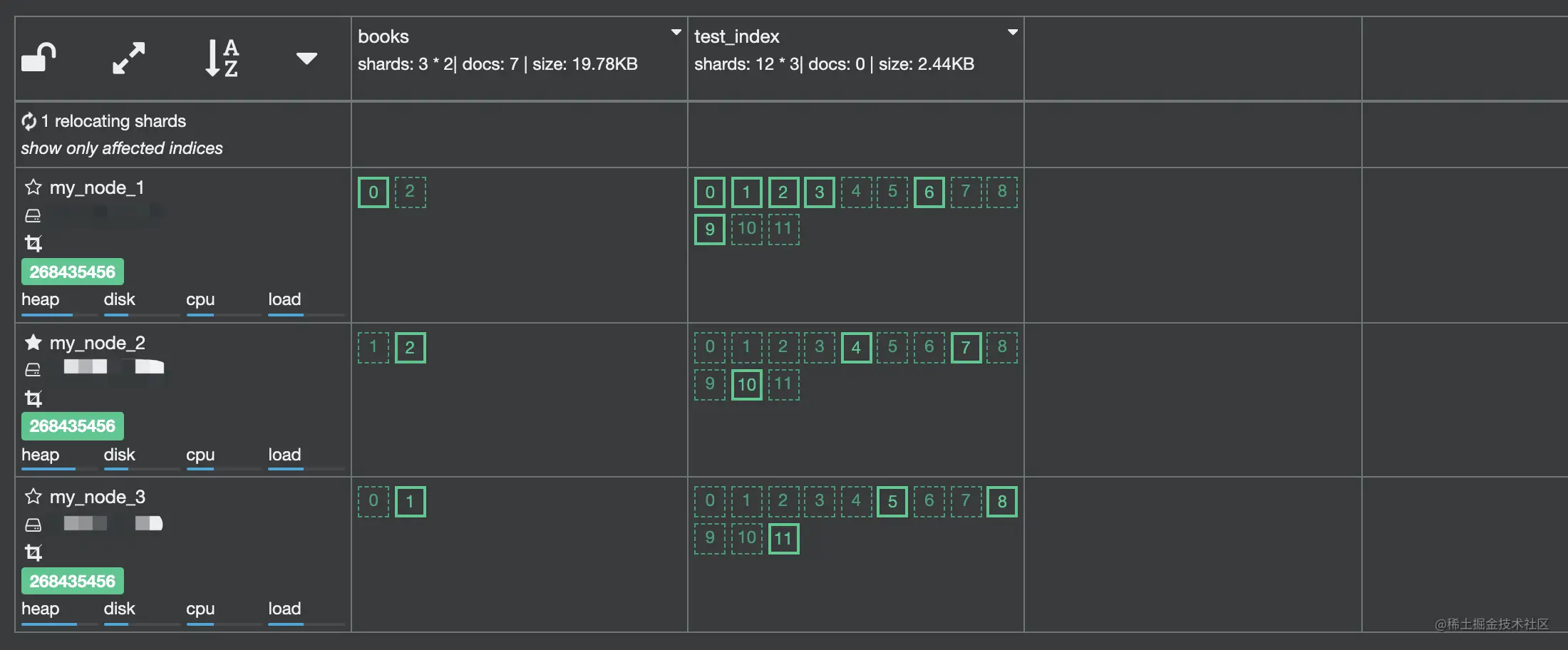
先创建索引 test_index,设置 number_of_shards = 12,number_of_replicas = 2。
# 删除索引,如果存在的话DELETE test_index# 创建索引PUT test_index{"mappings": {"properties": { "test_name": { "type": "keyword"} }},"settings": {"number_of_shards": 12,"number_of_replicas": 2}}
创建后的索引,在 Cerebro 中查看如下:
下面将索引 test_index 所有的主分片转移到节点 my_ndoe_1 上,并且设置索引的副本分片数量为0、设置这个索引为只读状态:
PUT /test_index/_settings{# 分片分配到 my_node_1 节点"index.routing.allocation.require._name": "my_node_1","index.number_of_replicas": 0,"index.blocks.write": true}
ok,这个时候 test_index 满足了收缩索引的 3 个条件了,下面开始进行收缩:
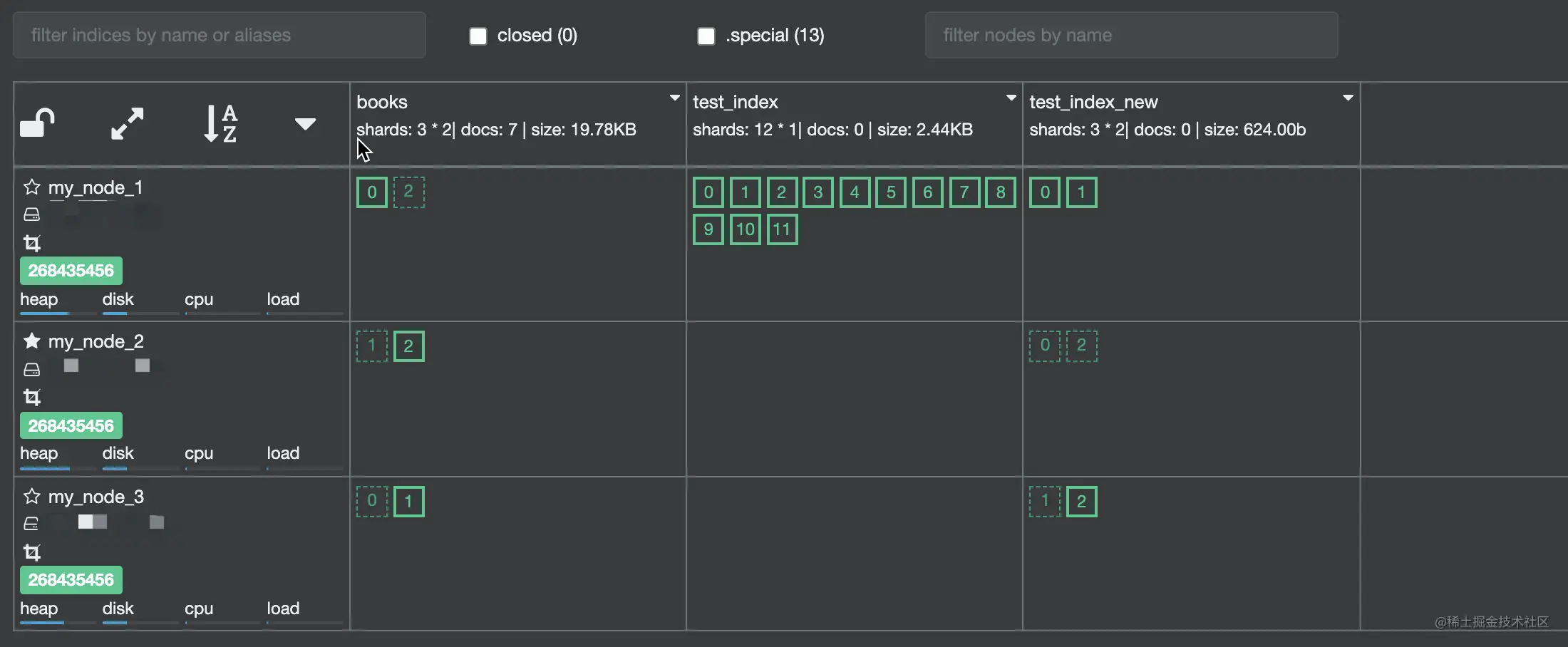
POST /test_index/_shrink/test_index_new{"settings": {"index.number_of_replicas": 1,"index.number_of_shards": 3,"index.routing.allocation.require._name": null, # 系统随机分配分片"index.blocks.write": null # 不阻塞写操作}}
如上示例,我们设置了新索引的主分片数量为 3,每个主分片的副本数量为 1,并且这些分片是系统自动、随机分配的,不阻塞新索引的写操作。
最终在 Cerebro 中可以看到,这两个索引的信息如下:
更多关于收缩索引 API 的使用参数和示例,可以参考官方文档。
十、总结
今天为你介绍了多个关于索引管理的 API 和它们的使用示例。
索引的创建和删除我们一直在使用,相信你已经非常熟悉了。在创建索引的时候我们可以定义 Mapping 和 Setting,同样 ES 也提供单独的更新 Setting 和 Mapping 功能接口,但是不是所有的设置都可以修改的,例如 number_of_shards,一旦设定了使用的主分片数量就无法更改了,又例如我们无法修改已经在 Mapping 中定义了的字段的类型。
如果发现索引创建了太多的主分片,可以使用收缩索引 API 减少索引的主分片的数量,但最终还是不会修改原索引的设定,并且新索引主分片数量必须是旧索引主分片数量的因子。
同样如果发现 Mapping 中某个字段的类型已经无法满足需求了,需要使用 Reindex API 才能解决问题,最终也是创建了一个新的索引来接收旧索引数据的迁移,并没有对旧索引有任何影响。
如果我们要创建的索引都有着差不多的配置,我们可以先定义索引模板,之后索引名字匹配这个模板的话就可以应用这些设置了。
好了今天的内容到此为止,今天介绍的索引管理 API 是比较常用的功能了,ES 提供的索引管理 API 非常丰富,更多的使用例子可以参考官方文档。
