当我们学习一个复杂的系统时,最怕的是一上来就钻到其复杂的实现或者源码中去。Linus 就建议,在看 Linux 内核源码前,应该先熟悉使用 Linux 系统。同样在学习 ES 的时候,我们也会有序渐进。从安装到各种 API 的使用,从名词概念的解析到讲解相关概念、功能的实现原理,最后才是源码的阅读。
而本文将会对 ES 中出现的大部分名词、概念做一个汇总和解析,希望通过本文,你可以对 ES 的服务架构有一个基本的了解。有了对 ES 整体的认识,我们后续的学习才有可能做到事半功倍。
ES 中的概念有很多,如:集群、节点、索引、分片、副本、集群状态、Mapping、文档、字段(Field)、词项(Term)、Lucene、倒排索引、正排索引、相关性评分等。
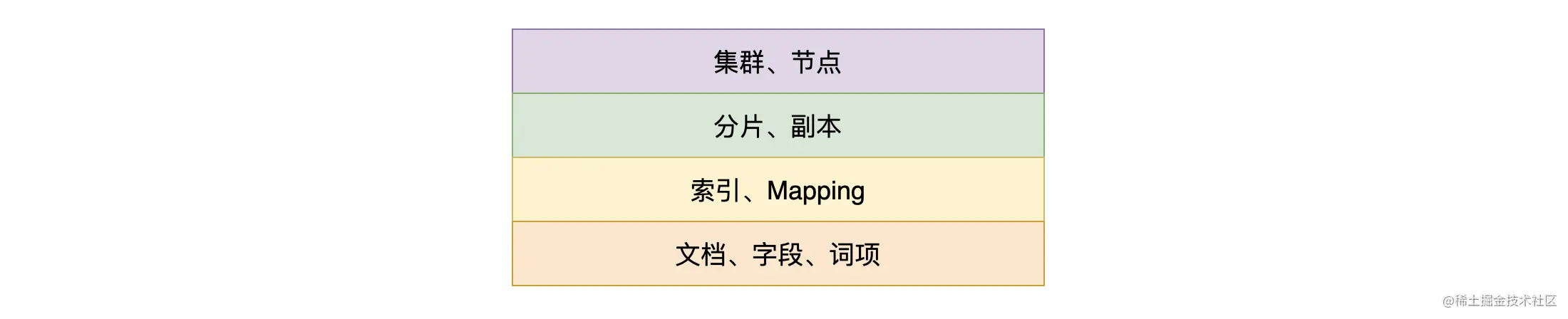
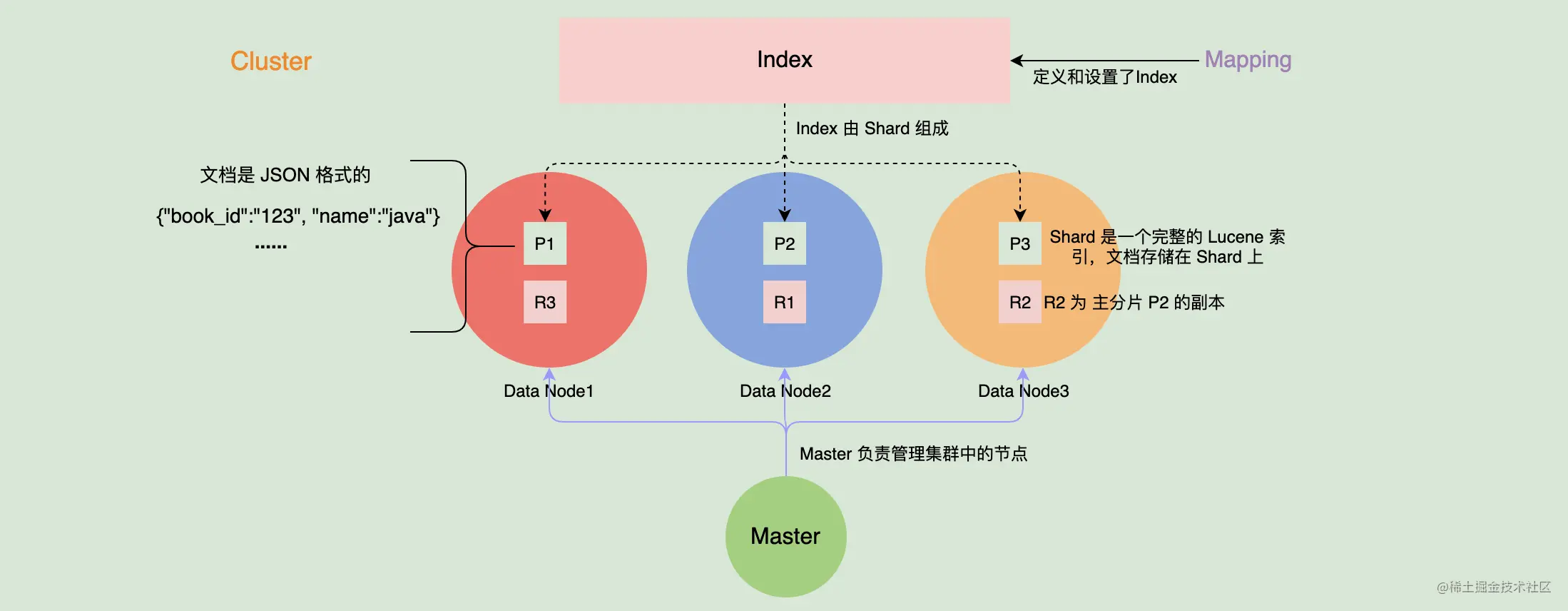
如上图,本文会先从集群层面来了解 ES ,然后再看看数据层面、系统层面上相关的概念。通过从上到下,我们把这些概念一一串起来。
那下面就开始我们今天的内容吧!
一、集群层面上的基本概念
1. 集群(Cluster)
如下图,由多个协同工作的 ES 实例组合成的集合称为集群,图中节点 Node1、Node2、Node3 分别运行了一个 ES 实例,它们组成一个集群。分布式的 ES 集群可以存储海量的数据,也可以从容地面对更高的并发量。
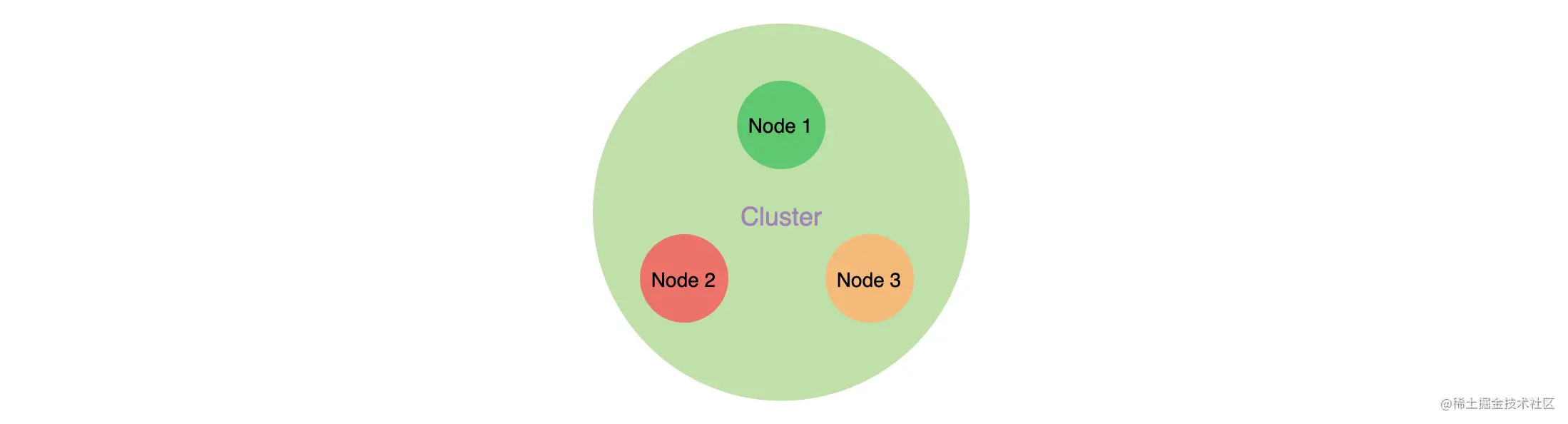
集群也是一种提供无间断服务的方案,得益于分布式系统的架构设计,使得 ES 拥有高可用性和可扩展性。
高可用性,分为服务可用性、数据可用性。
- 服务可用性,在有部分节点挂掉的情况下系统还可以对外提供服务。
- 数据可用性,部分节点挂掉,并且这些节点的数据无法恢复的情况下,也能保证数据不丢失。
- 可扩展性,当并发量提升,或者数据量增多的情况下,可以通过增加节点数来解决问题。
2. 节点(Node)
单个 ES 的服务实例叫做节点,本质上就是一个 Java 进程啦。每个实例都有自己的名字,就是上一节配置里的 ‘node.name’ 设置的内容。为了标识每个节点,每个节点启动后都会分配一个 UID,存储在 data 目录。各个节点受到集群的管理,我们可以通过增加或者减少节点来达到扩容或减容的目的。
集群里的节点是有分类的,就好像一家公司的不同部门,负责不同的业务和工作,主要的节点类型如下。
主节点(Master)。主节点在整个集群是唯一的,Master 从有资格进行选举的节点(Master Eligible)中选举出来。主节点主要负责管理集群变更、元数据的更改。如果要类比的话,主节点像是公司的总经办。
数据节点(Data Node)。其负责保存数据,要扩充存储时候需要扩展这类节点。数据节点还负责执行数据相关的操作,如:搜索、聚合、CURD 等。所以对节点机器的 CPU、内存、I/O 要求都比较高。
协调节点(Coordinating Node)。负责接受客户端的请求,将请求路由到对应的节点进行处理,并且把最终结果汇总到一起返回给客户端。因为需要处理结果集和对其进行排序,需要较高的 CPU 和内存资源。
预处理节点(Ingest Node)。预处理操作允许在写入文档前通过定义好的一些 processors(处理器)和管道对数据进行转换。默认情况下节点启动后就是预处理节点。
部落节点(Tribe Node)。部落节点可以连接到不同集群,并且支持将这些集群当成一个单独的集群处理。但它在未来的版本中将会被淘汰。
Hot & Warm Node。不同硬件配置的 Data Node,用来实现 Hot & Warm 架构的节点,有利于降低集群部署成本。例如,在硬件资源好的机器中部署 Hot 类型的数据节点,而在硬件资源一般的机器上部署 Warm Node 节点。
在生产环境中建议将每个节点设置为单一角色。如果业务量或者并发量不大的情况下,为了节省成本可以调整为一个节点多种角色的集群。在开发环境中的话,为了节省资源,一个节点可以设置多种角色(上一章的伪集群模式就很适合)。
下表是旧版本(7.8 及之前)各个节点类型的配置方式(Hot & Warm Node 需要通过其他方式来设定,不在此列):
| 节点类型 | 配置 | 默认值 |
|---|---|---|
| Master Eligible | node.master | true |
| Data Node | node.data | true |
| Ingest Node | node.ingest | true |
| Coordinating Node | 不需要配置 | 默认就是coordinating,所以需要设置单一角色时,设置其他类型全部为false |
其实上述的配置方式并不怎么人性化,在新版的 ES 中,这个配置方式就做出了改变,使用 node.roles 参数来指定一个节点的角色。其示例如下:
node.roles: [ master, data ] //设置节点为 master 候选节点和数据节点
如上示例,node.roles 的值是一个数组,说明一个节点可以有多个角色。node.roles 的可选项如下:
master,master 候选节点,master 将会从这些节点中选取出来。
voting_only,参与 master 选举的节点,其只有投票权限,当不会成为 master。
data,我们最熟悉的一类数据节点。保存文档数据的 shard 将分配到 data 节点中保存。
data_content,此角色的节点会处理用户创建的文档内容,如书本信息,歌曲信息这类数据。可以处理 CRUD、数据搜索和聚合等。
data_hot,此角色的节点会根据数据写入 ES 的时间存储时序数据,例如日志数据,data_hot 节点对数据读写要求快速,应当使用 SSD 存储。
data_warm,data_warm 节点会存储不会经常更新但是仍然被查询的数据,相对于 data_hot,其查询的频率要低。
data_cold,很少再被读取的数据可以存储在 data_cold,此类节点的数据是只读的。
data_frozen,专门用于存储 partially mounted indices 的数据节点。
ingest, 预处理数据的节点。
ml, 提供机器学习的功能,此类节点运行作业并处理机器学习 API 请求。
remote_cluster_client,充当跨集群客户端并连接到其他集群。
transform,运行 transforms 并处理 transform API 请求。
机智的你会发现,上述类型中并没有协调节点的类型选项,那怎么设置一个节点为协调节点呢?其实每个节点本身就是一个协调节点,而你一定要指定一个节点为协调节点的话,可以这样设置:
node.roles: [ ] //对,就是啥都不写即可
在线上的环境中建议你将节点分层部署,使用专门的节点类型来处理相应的业务需求。更多关于节点角色的信息请参考官方文档。
3. 分片(Shard)
分片的概念其实很好理解,试想一下如果家里的书多到一个箱子装不下,是不是要找另外一个箱子来装?这些书就好比海量的数据,一台机器存不下,就放到多台机器来存储。
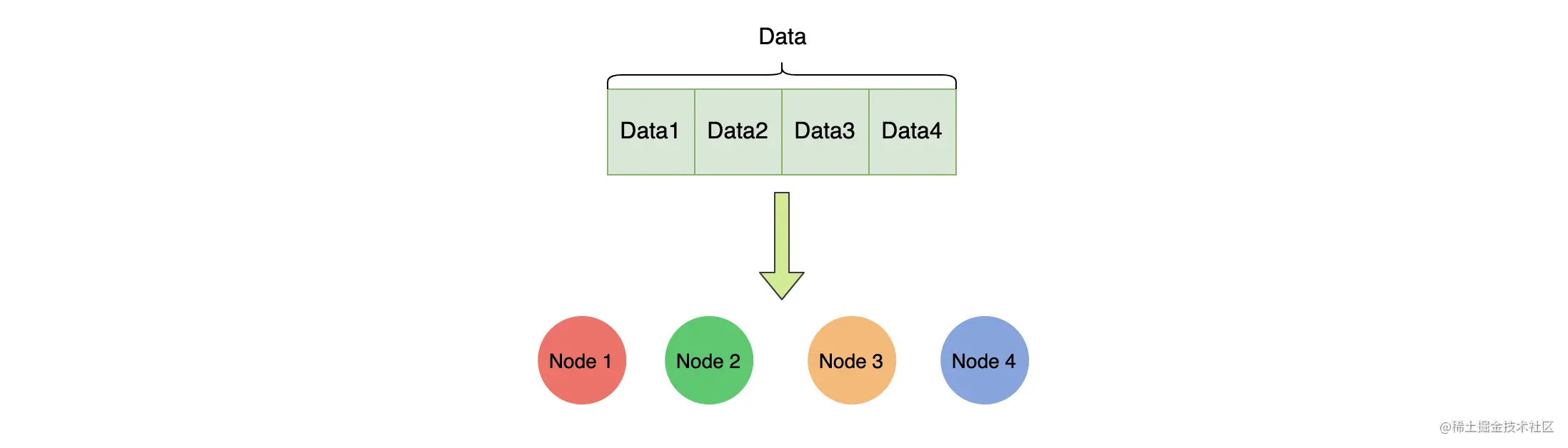
如上图,数据集 Data 按某些规则分为 4 个部分,然后被存储到 4 个节点上面(一个节点一个分片)。
一般来说,面对海量数据的时候,分布式系统可以通过增加机器数量来进行水平扩展。所以,系统需要将数据分成多个小块数据,并且尽量均匀地分配到各个机器上,然后可以通过某种策略找到对应数据块所在的位置。分片(Shard)是 ES 底层基本的读写单元,分片是为了分割巨大的索引数据,让读写可以由多台机器来完成,从而提高系统的吞吐量。
4. 副本(Replica)
为了保证数据可靠性,一般分布式系统都会对数据进行冗余备份,这个备份也就是副本了。ES将数据副本分为主从两类型:主分片(primary shard)和副分片(replica shard) 。在写入的过程中,先写主分片,成功后并发写副分片,在数据恢复时以主分片为主。多个副本除了可以保证数据可靠性外,还有一个好处是可以承担系统的读负载。
可以在 Kibana 中运行下面指令来设置分片数量和副本数量:
# 创建 mapping 的时候定义好分片和副本数量。PUT books{"mappings": {"properties": {"book_id": {"type": "keyword"},"name": {"type": "text"}}},"settings": {"number_of_shards": 2, # 定义了 2 个分片"number_of_replicas": 2 # 定义了每个分片 2 个副分片}}
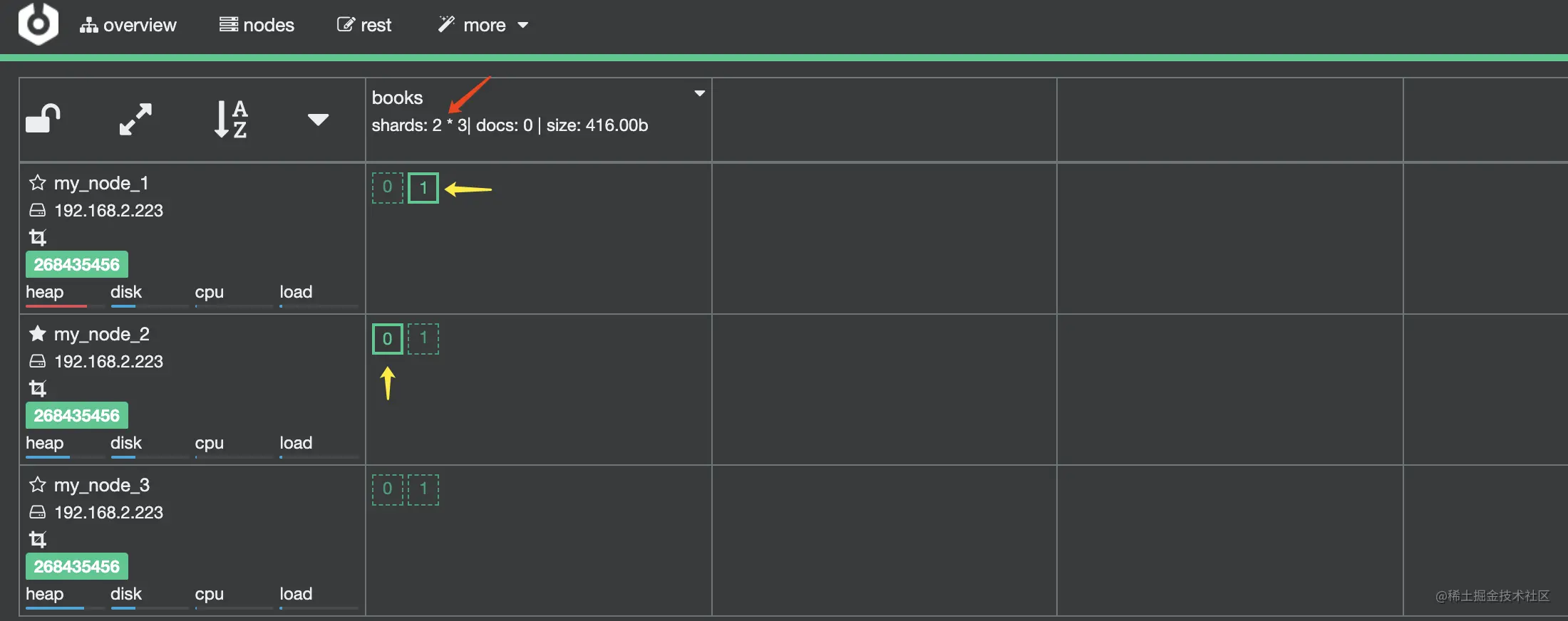
用上述指令创建 books 索引后,其在 Cerebro 中显示如下图,在红色箭头处 shards: 2 * 3 的意思是共有 2 个分片,每个分片一个主分片和 2 个副分片,加起来就是 3 个副本了。图中黄色箭头处的 0 和 1 代表的是两个分片:分片 0 、分片 1,实线代表主分片,虚线代表分片副本。
5. 集群健康状态
通过集群的健康状态,我们可以了解集群是不是出现问题了。 集群健康状态有以下 3 种。
Green,集群处于健康状态,所有的主分片和副本分片都正常运行。
Yellow,所有的主分片都运行正常,但是有部分副本分片不正常,意味着可能存在单点故障的风险(如果部分主分片没有备份了,一旦这个主分片数据丢失,将导致这些数据永久丢失)。如果集群只有 3 个数据节点,但是分配了 4 个副本(主分片 + 副本分片的总数),这个时候有一个副本无法分配的,因为相同的两份数据不应该被分配到同一个节点上。
Red,有部分主分片没有正常运行。
需要注意的是,每个索引也有这三种状态,如果索引丢失了一个副本分片,那么这个索引和集群的状态都变为 Yellow 状态,但是其他索引的的状态仍为 Green。
二、数据层面上的基本概念
1. 索引(Index)
索引是一类相似文档的集合。ES 将数据存储在一个或者多个 Index 中,例如将用户数据存储在 User Index 中,而将订单数据存储在 Order Index 中。一个索引有一个或者多个分片,索引的数据会以某种方式分散到各个分片上去存储。
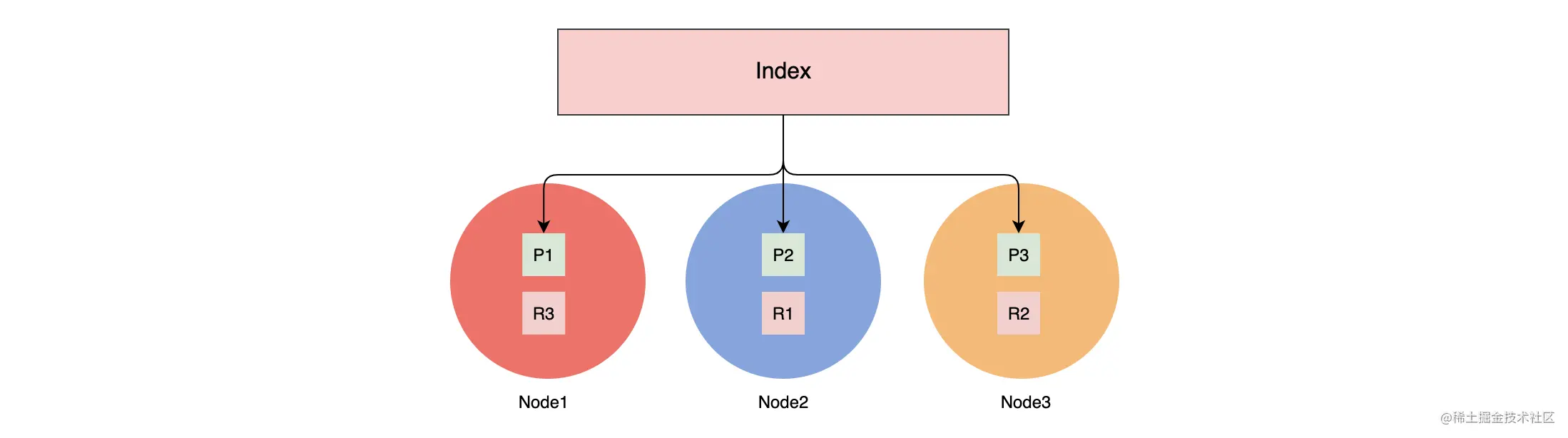
如上图,索引有 3 个分片,主分片分别是 P1、P2、P3,对应的副本分片为 R1、R2、R3,它们分别位于 3 个节点中。如果你细心的话,可以发现主分片和其副本分片不会同时分配在同一个节点上。这样是为了保证当一个节点上的主分片下线时,其他节点上的从副本可以升级为主分片,保证数据的可靠性。
2. Mapping
Mapping 定义了索引里的文档到底有哪些字段及这些字段的类型,类似于数据库中表结构的定义。Mapping 有两种作用:
- 定义了索引中各个字段的名称和对应的类型;
- 定义各个字段、倒排索引的相关设置,如使用什么分词器等。
例如,我们在上面定义的 books 索引,其有一个 keyword 类型的字段,名字为 book_id,另外一个字段为 name,其类型为 text。
需要注意的是,Mapping 一旦定义后,已经定义的字段的类型是不能更改的。至于其原因,我们后续的内容会提到。
3. 文档(Doc)
我们向 ES 中写入的每一条数据都是一个文档(类似数据库中的一条记录),并且我们搜索也是以文档为单位的,所以文档是 ES 中的主要实体。我们可以在 Kibana 中运行下面指令来插入一条书本的记录:
# 我们指定了文档的 id 为1POST /books/_doc/1{"book_id":"123","name":"linux 从入门到放弃"}
下面我们继续数据查询,看看能得到什么结果,在 Kibana 中运行以下查询:
# 搜索POST books/_search{"query": {"match_phrase": {"book_id": "123"}}}# 返回的结果{......"hits" : {......"max_score" : 0.2876821,"hits" : [{"_index" : "books","_type" : "_doc","_id" : "1","_score" : 0.2876821,"_source" : {"book_id" : "123","name" : "linux 从入门到放弃"}}]}}
从返回结果中可以看到,我们插入的数据包含在 “_source” 字段里,结果中还带有其他字段,这些额外的字段都是 ES 为文档加上的元数据,下面是这些字段的解析。
- _index,文档所属的索引名字,上述是 books。
- _type,文档所属的类型名字,现在 ES 7.x 版本的类型统一为 “_doc” 。
- _id,文档的唯一 id。如果我们插入时不指定文档 id,ES 会随机分配,这样有利于数据均匀分散到各个分片。
- _version,文档的版本信息,并发读写时可以解决文档冲突。
- _score,相关性算分,代表着查询的匹配性,用来排序。
- _seq_no 和 _primary_term,是 ES 内部用来保证主分片和副本数据一致性的,后面的章节中我们会进行介绍。当一个 Index 每次选择出主分片后都会有一个序号,记为 _primary_term,其实递增的。而在同一个 Index 下,每次写入数据后都会有一个写入顺序号,记为 _seq_no,其同样也是递增的。 _primary_term 和 _seq_no 在逻辑上构成了一个文档写入的唯一位置。
总体来说,文档有以下几个特性。
- ES 是面向文档的并且以文档为单位进行搜索的,如一条书本记录。
- 文档以 JSON 格式进行序列化存储。
- 每个文档都有唯一的 ID。如果使用:POST /books/_doc 这样插入,ES 会自动生成唯一 ID,也可以使用 POST /books/_doc/1 指定记录的 ID。不指定 ID 时插入的性能会好点,因为系统不需要进一步判断这个 ID 是否已经存在。
4. 字段(Field)
每个文档都有一个或者多个字段,例如 books 索引指定了书本的记录有 book_id 和 name 两个字段,其实就是 JSON 中的 Key 嘛。
每个字段都有指定的类型,常见的有:keyword、text、数字类型(integer、long、float、double等)、对象类型等。
keyword 类型适合存储简短、结构化的字符串,例如产品 ID、产品名字等。而 text 类型的字段适合存储全文本数据,如短信内容、邮件内容等。对象类型简单来说就是字段的值还是一个 json 对象。下面是一个简单的示例:
PUT books{"mappings": {"properties": {"book_id": {"type": "keyword"},"name": {"type": "text"},"author": { # 对象类型的定义"properties": {"first": { "type": "text" },"last": { "type": "text" }}}}}}
5. 词项(Term)
将全文本的内容进行分词后得到的词语就是词项了。例如 “Programmers Love Cat” 使用标准分词器分词后得到 [programmer, love, cat] 这 3 个词项。需要注意的是:分词器除了进行分词外还会进行大小写转换等其他操作。
6. 倒排索引与正排索引
如下图,将保存实体 ID 到实体数据关联关系的数据结构叫做正排索引,我们熟知的 MySQL InnoDB 的索引就是正排索引,使用的是 B+ 树来实现。

如下图,将保存词项到文档实体关联关系的数据结构叫做倒排索引。倒排索引的具体实现我们将在后续的内容中进行介绍,现在只需要简单了解一下这个概念就可以了。

三、系统层面上的基本概念
1. 近实时系统
ES 是一个近实时系统,我们写入的数据默认的情况下会在 1 秒后才能被查询到。ES 每秒都会把缓存中的数据写入到 Segment 文件中(写入到 Segment 中才能被检索),然后根据某些规则进行刷盘,并且合并这些 Segment。所以需要注意的是,不能在写入数据成功后,立刻进行查询,这个时候可能会出现查询不到数据或者获取到旧数据的情况。
2. Lucene 与 ES 的关系
Lucene 是一个用于全文检索的开源项目,ES 在搜索的底层实现上用的就是 Lucene。你可以简单认为,ES 就是在 Lucene 上增加了分布式特性的系统服务。
Lucene 也有索引,那 Lucene 的索引和 ES 的索引是个怎么样的关系呢?其实 ES 上的分片(Shard)就是一个完整的 Lucene 索引。
3. 相关性评分
对于一个搜索引擎来说,对检索出来的数据进行排序是非常重要的功能。全文本数据的检索通常无法用是否相等来得出结果,而是用相关性来决定最后的返回结果。而相关性的指标为相关性评分。
至于相关性评分是如何计算的,这里不展开,我们后续的内容会有非常详细的介绍,这里我们简单举个例子来说明。
例如下面两句话就非常相似:“红色的猫喜欢吃苹果”(这是检索的内容)、“红色的猫猫非常喜欢吃大苹果”(这个是库里的内容,被检索的内容)。 它们相似的原因是因为它们都有 “红色”、“猫”、“苹果” 这 3 个有效词。如果要转化为数学模型的话,简单来说,相关性可以由句子中有效的词语在句子中出现的频率来表示。当然有效的算法比这个复杂很多,要考虑的因素也非常多!
四、总结
本文主要介绍了一些 ES 的基本概念(可结合下图来理解),让你对 ES 有个粗略的认识。ES 中还有很多其他的名词、概念,后面我们在学习中将会遇到,这里就不提及了。
好了,今天的内容到此为止。欢迎你在留言区与我分享你的想法,我们一起交流、一起进步。
