redo、undo、buffer pool、binlog,谁先谁后,有点儿乱
标签: MySQL是怎样运行的
这篇文章我们来讨论一下一条DML语句从客户端发出后,服务器都做了哪些处理。
小贴士:
虽然SELECT语句的处理也很复杂,但SELECT语句并不会修改数据库中的数据,也就不会记录诸如redo、undo、binlog这些日志,本文主要是想讨论redo、undo、binlog这些日志是在什么时候生成的,啥时候写到磁盘的。
为了增强文章的真实性(总是有一些小伙伴问小孩子为什么和CSDN上的某某文章陈述的不一样),我们会列举一些关键步骤的代码,本文用到的源码版本为MySQL 5.7.22。
另外,我们假设屏幕前的小伙伴已经知道什么是buffer pool,什么是redo日志,什么是undo日志,什么是binlog,以及MySQL为什么需要它们。我们不会再展开各种日志的格式、写入方式等细节问题,有不清楚的小伙伴可以查看《MySQL是怎样运行的:从根儿上理解MySQL》,包教包会,不会来问小孩子。
预备知识
我们讨论的是基于InnoDB存储引擎的表,数据会被保存在硬盘上的表空间(文件系统中的一个或多个文件)中。
InnoDB会将磁盘中的数据看成是若干个页的集合,页的大小默认是16KB。其中某些页面用于存储关于系统的一些属性,某些页面用于存储undo日志,某些页面用于存储B+树的节点(也就是包含记录的页面),反正总共有十来种不同类型的页面。
不过不论是什么类型的页面,每当我们从页面中读取或写入数据时,都必须先将其从硬盘上加载到内存中的buffer pool中(也就是说内存中的页面其实就是硬盘中页面的一个副本),然后才能对内存中页面进行读取或写入。如果要修改内存中的页面,为了减少磁盘I/O,修改后的页面并不立即同步到磁盘,而是作为脏页继续呆在内存中,等待后续合适时机将其刷新到硬盘(一般是有后台线程异步刷新)。
准备工作
为了故事的顺利发展,我们先建立一个表:
CREATE TABLE hero (number INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引),示意图如下: 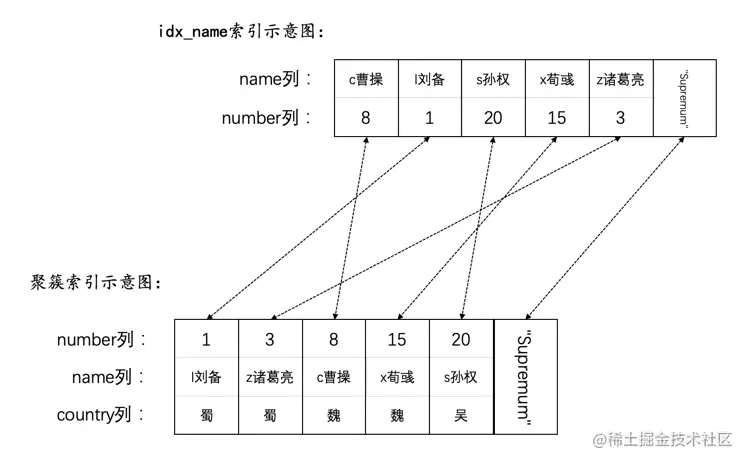
执行计划的生成
假设我们想执行下边这条UPDATE语句:
UPDATE hero SET country = '汉' WHERE name >= 'x荀彧';
MySQL优化器首先会分析一下使用不同索引执行查询的成本,然后选取成本最低的那个索引去执行查询。
对于上述语句来说,可选的执行方案有2种:
- 方案一:使用全表扫描执行查询,即扫描全部聚簇索引记录,我们可以认为此时的扫描区间就是
(-∞, +∞)。 - 方案二:使用二级索引idx_name执行查询,此时的扫描区间就是
['x荀彧', +∞)。
优化器会计算上述两种方案的成本,选取成本最低的方案作为最终的执行计划。
我们作为用户,可以通过EXPLAIN语句来看一下这个语句的执行计划(当然也可以通过MySQL提供的optimizer trace功能查看具体执行计划分析流程):
mysql> explain UPDATE hero SET country = '汉' WHERE name >= 'x荀彧';+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+| 1 | UPDATE | hero | NULL | range | idx_name | idx_name | 303 | const | 2 | 100.00 | Using where |+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+1 row in set, 1 warning (0.01 sec)
可以看到,MySQL优化器决定采用方案二,即扫描二级索引idx_name在['x荀彧', +∞)这个扫描区间种的记录。
真正开始执行
MySQL分为server层和存储引擎层,我们前边的多篇文章有唠叨这两层之间的关系。考虑到没有看过前边文章的小伙伴,我们再不厌其烦的唠叨一下在执行上述UPDATE语句时server层和InnoDB层之间是如何沟通的。优化器的执行计划中得到了若干个扫描区间(本例中只有1个扫描区间['x荀彧', +∞)),针对每个扫描区间,都会执行下边的步骤:
处理扫描区间的第一条记录
步骤1:首先server层根据执行计划,向InnoDB层索要二级索引idx_name的扫描区间
['x荀彧', +∞)的第一条记录。步骤2:Innodb存储引擎便会通过二级索引idx_name对应的B+树,从B+树根页面一层一层向下查找(在页面中查找是通过页目录的槽进行二分查找的,这个过程很快),快速在叶子节点中定位到扫描区间
['x荀彧', +∞)的第一条二级索引记录。接着根据这条二级索引记录中的主键值执行回表操作(即通过聚簇索引的B+树根节点一层一层向下找,直到在叶子节点中找到相应记录),将获取到的聚簇索引记录返回给server层。步骤3:server层得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样,如果一样的话就不更新了,如果不一样的话就把更新前的记录和更新后的记录都当作参数传给InnoDB层,让InnoDB真正的执行更新记录的操作。
步骤4:InnoDB收到更新请求后,先更新记录的聚簇索引记录,再更新记录的二级索引记录。最后将更新结果返回给server层。
处理扫描区间的第二条记录
步骤1:server层继续向InnoDB索要下一条记录。
步骤2:此时由于已经通过B+树定位到二级索引扫描区间
['x荀彧', +∞)的第一条二级索引记录,而记录又是被串联成单向链表,所以InnoDB直接通过记录头信息的next_record的属性即可获取到下一条二级索引记录。然后通过该二级索引的主键值进行回表操作,获取到完整的聚簇索引记录再返回给server层。步骤3:server层得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样,如果一样的话就不更新了,如果不一样的话就把更新前的记录和更新后的记录都当作参数传给InnoDB层,让InnoDB真正的执行更新记录的操作。
步骤4:InnoDB收到更新请求后,先更新记录的聚簇索引记录,再更新记录的二级索引记录。最后将更新结果返回给server层。
处理扫描区间的剩余记录
该扫描区间中的其他记录的处理就和第2条记录的处理过程是一样一样的了,这里就不赘述了。
详细的更新过程
MySQL使用mysql_update函数处理我们上述的更新语句:
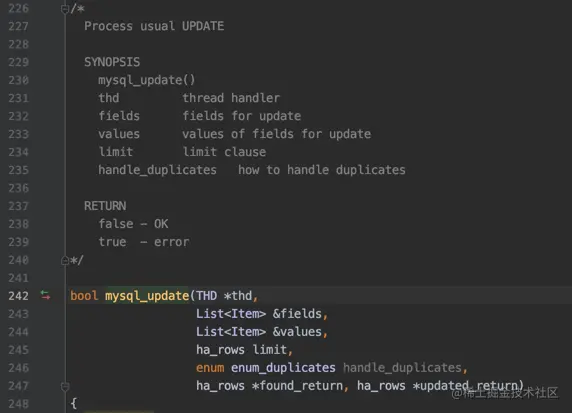
最主要的处理流程写在了一个循环里:
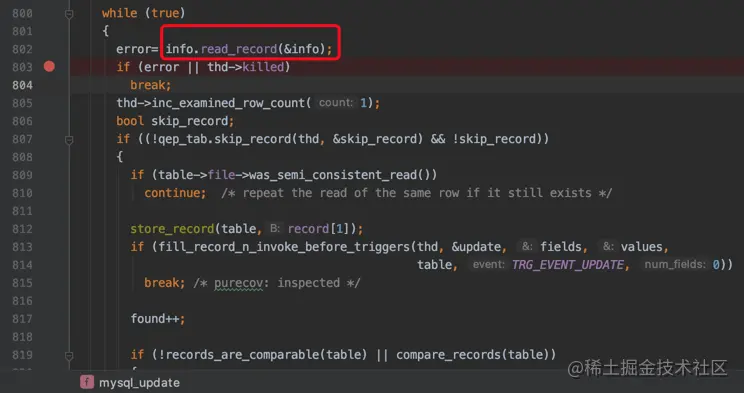
上图所示的while循环就是依次处理各条记录的过程。
其中info.read_record是用于获取扫描区间的一条记录,读取到该记录后随后展开详细的更新操作。处理完了之后再回到这个while循环的起点,通过info.read_record获取下一条记录,然后进行详细的更新操作。
也就是说,其实处理每一条记录的过程都是类似的,只不过定位扫描区间的第一条记录会有点儿麻烦(需要从B+树根页面一层一层向下找)。
我们下边聚焦于一条记录的更新过程,看看这个过程都发生了什么。
将记录所在的页面加载到buffer pool
我们想更新一条记录,首先就得在B+树中定位这条记录——即进行一次加锁读(上图中的info.read_record函数用于调用Innodb读取记录的接口,关于对一条记录加锁的过程我们在之前的文章中分析过,这里就不赘述了。)。
如果该记录所在的页面已经在内存的buffer pool中,那就可以直接读取,否则还需要将该记录所在的页面读取到内存中的buffer pool中。
小贴士:
再一次强调,不论我们想读写任何页面,都需要先将该页面从硬盘加载到buffer pool中。在定位扫描区间的第一条记录时,我们首先要读取B+树根页面中的记录,所以首先需要先把B+树根页面加载到buffer pool中,然后再读取下一层的页面,然后再读取下下层的页面,直到叶子节点。每当要读取的页面不在buffer pool中,都得将其先加载到buffer pool后才能使用。
Innodb使用row_search_mvcc处理读取一条记录的过程(不论是加锁读还是一致性读都调用这个函数),在该函数内btr_pcur_open_with_no_init用于从B+树定位记录:
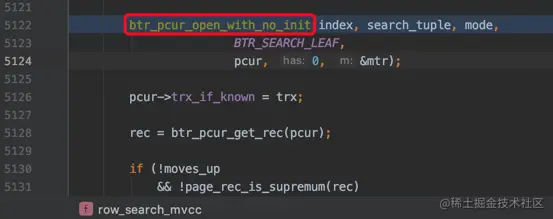
在定位记录时就需要将记录所在的页面加载到buffer pool,完成这个过程的函数是:
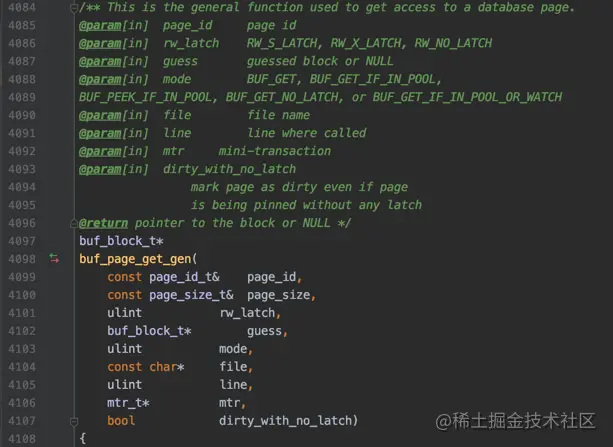
检测更新前后记录是否一样
在mysql_update函数中,当通过info.read_record读取到一条记录之后,就要分析一下这条记录更新前后是否发生变化:
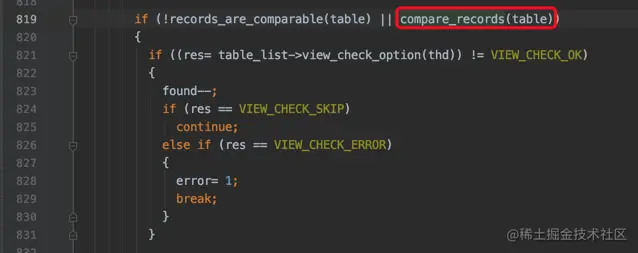
上图中的compare_records用于比较记录更新前后是否一样。
如果更新前和更新后的记录是一样的,那就直接跳过该记录,否则继续向下处理。
调用存储引擎接口进行更新

上图中的ha_update_row就是要存储引擎去更新记录,其中的table->record[1]代表旧记录,table->record[0]代表新记录。
更新聚簇索引记录
InnoDB会首先更新聚簇索引记录,然后再更新二级索引记录。
我们先看更新聚簇索引记录时都发生了什么。更新聚簇索引的函数如下所示:
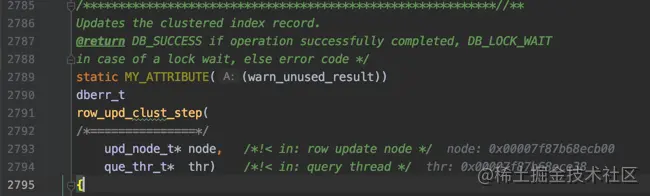
下边首先会尝试在同一个页面中更新记录,这被称作乐观更新,调用btr_cur_optimistic_update函数:
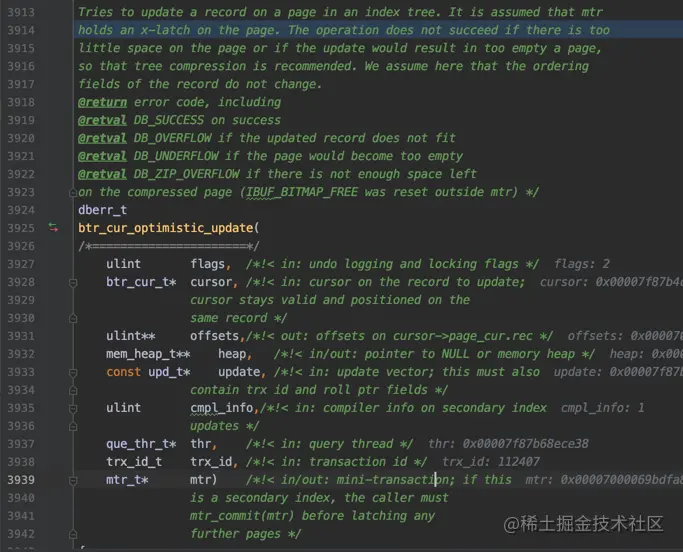
如果不能在本页面中完成更新(比方说更新后的记录非常大啊,本页面容纳不下),就会尝试悲观更新:
本例中使用乐观更新即可。
记录undo日志
更新记录前,首先要记录相应的undo日志,调用trx_undo_report_row_operation来记录undo日志:

首先我们要知道,MySQL的undo日志是要写到一种专门存储undo日志的页面中的。如果一个事务写入的undo日志非常多,需要占用多个Undo页面,那这些页面会被串联成一个链表,称作Undo页面链表。
trx_undo_page_report_modify函数用于真正的向Undo页面中写入undo日志。另外,由于我们这里是在修改页面,一个事务执行过程中凡是修改页面的地方,都需要记录相应的redo日志,所以在这个函数的末尾,有一个记录修改这个Undo页面的redo日志的函数trx_undof_page_add_undo_rec_log:

有同学在这里肯定会疑惑:是先将undo日志写入Undo页面,然后再记录修改该页面对应的redo日志吗?
先说答案:是的。
不过这里修改后的页面并没有加入buffer pool的flush链表,记录的redo日志也没有加入到redo log buffer。当这个函数执行完后,才会:
- 先将这个过程产生的redo日志写入到redo log buffer。
- 再将这个过程修改的页面加入到buffer pool的flush链表中。
上述过程是在mtr_commit中完成的:
小贴士:
设计MySQL的大叔把对底层页面的一次原子修改称作一个Mini Trasaction,即MTR。一个MTR中包含若干条redo日志,在崩溃恢复时,要么全部恢复该MTR对应的redo日志,要么全部不恢复。
也就是说实际上虽然先修改Undo页面,后写redo日志,但是此时InnoDB并不认为Undo页面是脏页,就不会将其刷新到硬盘,redo日志也没有写入到redo log buffer,这些redo日志也不会被刷新到redo日志文件。只有当MTR提交时,才先将redo日志复制到redo log buffer,再将修改的Undo页面加入到flush链表。
所以我们可以粗略的认为修改Undo页面的redo日志是先写的,而修改页面的过程是后发生的。
小贴士:
有后台线程不断的将redo log buffer中的redo日志刷新到硬盘的redo日志文件,也有后台线程不断的将buffer pool里的脏页(只有加入到flush链表后的页面才能算作是脏页)刷新到硬盘中的表空间中。设计InnoDB的大叔规定,在刷新一个脏页到硬盘时,该脏页对应的redo日志应该被先刷新到redo日志文件。而redo日志是顺序刷新的,也就是说,在刷新redo log buffer的某条redo日志时,在它之前的redo日志也都应该被刷新到redo日志文件。
修改页面内容
上一步骤是先把undo日志写到Undo页面中以及记录相应的redo日志,接下来该真正修改聚簇索引记录了。
首先更新系统字段trx_id以及roll_pointer:

然后真正的修改记录内容:

小贴士:
由于本例中的更新语句更新前后的各个字段占用的存储空间大小是不变的,所以可以直接就地(in place)更新。
然后记录更新的redo日志:

像向Undo页面写入undo日志一样,InnoDB规定更新一个页面中的一条记录也属于一个MTR。在该MTR提交时,也是先将MTR中的redo日志复制到redo log buffer,然后再将修改的页面加入到flush链表。
所以我们也可以认为在这个过程中,先记录修改页面的redo日志,然后再真正的修改页面。
至此,一条聚簇索引记录就更新完毕了。
更新二级索引记录
更新二级索引记录的函数如下所示:
更新二级索引记录时不会再记录undo日志,但由于是在修改页面内容,会先记录相应的redo日志。
由于本例子中并不会更新二级索引记录,所以就跳过本步骤了。
记录binlog
在一条更新语句执行完成后(也就是将所有待更新记录都更新完了),就需要该语句对应的binlog日志了(下图中的thd->binlog_query函数):
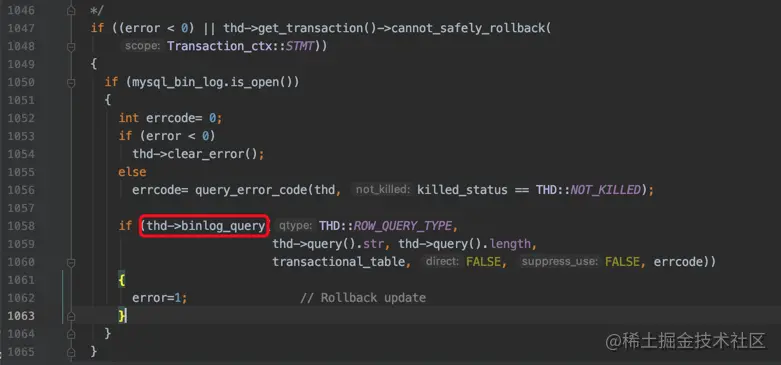
不过值得注意的是,此时记录的binlog日志并不会被写到binlog日志文件中,而是被暂时保存到内存的某个地方,等之后事务提交的时候才会真正将该事物执行过程中产生的所有binlog统一写入binlog日志文件。
提交事务的时候
终于要唠叨到所谓的两阶段提交(two phase commit)啦~
在事务提交时,binlog才会被真正刷新到binlog日志文件中,redo日志也会被刷新到redo日志文件中。不过由于这个部分涉及较多的知识点,所以我们本篇先不唠叨了,留在下一篇里吧
哈哈>_>
总结
本篇文章唠叨了执行一条UPDATE语句过程中都发生了什么事情。当优化器分析出成本最小的执行计划后,就开始对执行计划中的各个扫描扫描区间中的记录进行更新。具体更新一条记录的流程如下:
- 先在B+树中定位到该记录(这个过程也被称作加锁读),如果该记录所在的页面不在buffer pool里,先将其加载到buffer pool里再读取。
- 读取到记录后判断记录更新前后是否一样,一样的话就跳过该记录,否则进行后续步骤。
- 首先更新聚簇索引记录。 更新聚簇索引记录时: ①先向Undo页面写undo日志。不过由于这是在更改页面,所以修改Undo页面前需要先记录一下相应的redo日志。 ②真正的更新记录。不过在真正更新记录前也需要记录相应的redo日志。
- 更新其他的二级索引记录。
至此,一条记录就更新完了。
然后开始记录该语句对应的binlog日志,此时记录的binlog并没有刷新到硬盘上的binlog日志文件,在事务提交时才会统一将该事务运行过程中的所有binlog日志刷新到硬盘。
剩下的就是所谓的两阶段提交的事情了,我们下节再会~
