字符从UTF-8转成GBK发生了什么?
标签: MySQL是怎样运行的
字符是什么
字符是面向人类的概念,大致可分为两种,一种叫可见字符,一种叫不可见字符。
顾名思义,可见字符就是打印出来后能看见的字符。比如a、b、我这样的人眼能看见的单个国家文字、标点符号、图形符号、数字等这样的东东,我们就叫做一个可见字符。
不可见字符也好理解,就是之前打印机或者在黑框框里打印字符的时候有时候需要换行,打个制表符啥的,或者在输出某个字符的时候就发出嘟地一声,这种我们看不到,只是为了控制输出效果的字符叫做不可见字符。
注意,字符都是单个的喔!。把字符连起来叫做字符串,比如abc,就是由a、b、c三个字符连起来的一个字符串。
计算机怎么表示字符
计算机只能处理二进制数据,它并不认识字符。为了让计算机能处理字符,人们人为地在字符和二进制数字之间建立起了映射关系,映射的过程可以被称作编码,字符和二进制数字的映射关系也可以被称作编码方案。由于谁都可以制作编码方案,不同地人制作出了不同地编码方案。制作一种编码方案说清楚两个事就可以:
- 要对哪些字符进行编码
- 具体地每个字符和哪个二进制数字关联起来
虽然说谁都可以制作编码方案,但随着时间的流逝,只有为数不多的编码方案流行起来,比方说:
ASCII:收录128个字符,用7个二进制位就可以进行编码。但通常计算机以字节作为基本的存储空间分配单位,所以在ASCII编码方案中,通常使用1个字节对1个字符进行编码。
ISO 8859-1:收录256个字符,可用1个字节进行编码,兼容ASCII编码方案。
GBK:收录21886个字符,用
1~2个字节进行编码,兼容ASCII编码方案。UNICODE:收录目前世界上各式各样的字符。每个字符都对应一个数字,被称作Unicode值。该Unicode值可以被表示为多种形式,称作Unicode Transformation Formats,简称UTF。比方说:
- UTF-8:目前采用1~4个字节来表示一个Unicode值(随着Unicode中字符的扩充,可能使用更多的字节编码一个字符),并且兼容ASCII编码方案。
- UTF-16:目前采用2个或4个字节来表示一个Unicode值。
- UTF-32:目前采用4个字节来表示一个Unicode值
由于我们之前详细唠叨过不同编码方案是如何编码字符的,所以本文就不再赘述了。本文来唠叨一下不同字符编码方案之间是如何相互转换的。
字符编码方案的转换
对于字符'我'来说:
在
UTF-8中的编码值的二进制形式为:11100110 10001000 10010001
共3个字节,写成十六进制的形式就是:0xE68891。
在
GBK中的编码值的二进制形式为:11001110 11010010
共2字节,写成十六进制的形式就是:0xCED2
在某个需要将字符串的字符编码方案从UTF-8转成GBK的场景中,怎么把0xE68891转换成0xCED2呢?
解决这个问题其实很简单,我们可以制作一个大型数组, 数组大小就是源编码方案中包含的字符数量,这样在源编码方案中的每个字符的编码值都对应数组的一个下标。这样每个数组下标都对应一个字符,我们只需要将相应字符的目标编码方案的编码值填入到该下标对应的数组元素中。比方说:
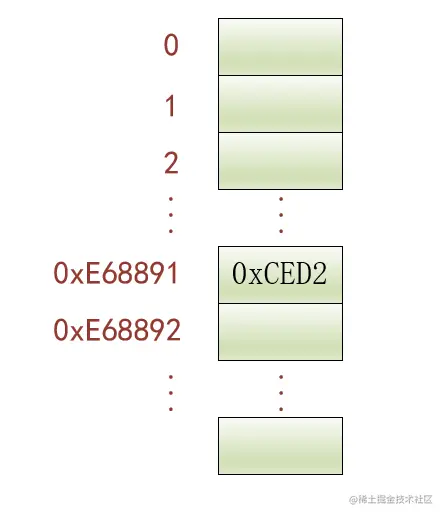
也就是说对于某个字符来说,数组下标就是源编码方案的编码值,数组元素值就是目标编码方案的编码值。这样就可以很轻松的完成某个字符的编码方案转换功能。
这个方案是有很大缺点的,因为UTF-8中包含的字符数量是远超GBK的,这就导致我们申请的数组的存储空间有绝大部分是被浪费掉的。其实数组里只需要把GBK编码方案中的字符编码都存储上即可,这样可以显著减小数组大小,但是由于我们又要要求根据字符的UTF-8编码值作为下标找到对应的GBK编码值,这时候就有点儿犯难。。。
其实GBK编码方案中包含的字符只会被包含在UTF-8编码方案的几部分中:

如上图所示,画圈部分的UTF-8编码值对应的字符就已经可以覆盖GBK编码方案中的字符了。当然,画圈部分的UTF-8编码值对应的某些字符也可能GBK编码方案并不包含,但这并不会有什么大问题,只是在申请数组的存储空间的时候浪费掉一些而已。
这样针对每一个圈,我们都可以建立一个数组,数组大小就是圈中UTF-8编码值的数量,每个圈对应数组的下标0都对应该圈包含的第1个UTF-8编码值,数组元素值就是相应下标对应的UTF-8编码值对应字符的GBK编码值。这样就可以极大程度减少数组占用的存储空间大小了。
那如果是UTF-16转GBK呢?
简单,再仿造上述步骤建立从UTF-16的编码值映射到GBK编码值的数组呗!
那如果是BIG5转GBK呢?
简单,再仿造上述步骤建立从BIG5的编码值映射到GBK编码值的数组呗!
那如果是UTF-16转BIG5呢?
还得建立相应的数组…
好像很烦噢,字符编码方案多种多样,想实现任意两个编码方案都可以相互转换的话,那我们得建立多少数组呀!如下图所示:
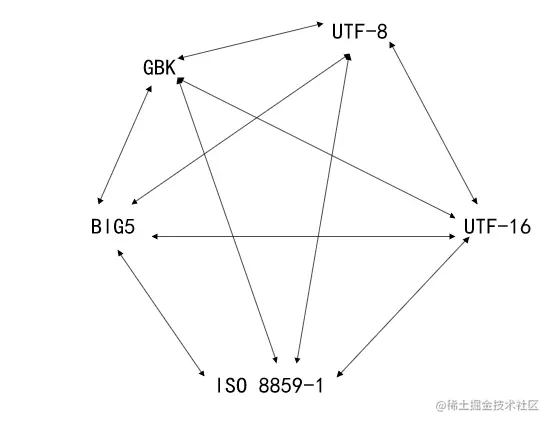
而且编码方案也可以随时增加,没新增一种编码方案都要考虑到与其他编码方案如何相互转换的问题实在太繁琐了。有没有什么好的方案呢?
有!比方有5个人分别会说汉语、英语、法语、俄语、阿拉伯语,如果想让他们之间任意两个人可以相互沟通,其实也没必要让每个人都学会其他4种语言,只需要规定大家都会同一门语言,比方说汉语!这样大家只需要学习一门外语即可相互沟通(会汉语的甚至都不用再学一遍外语了)!
在将某个字符从一种编码方案转换成另一种编码方案时,我们不必单独维护从源编码方案到目标编码方案的转换数组,只需要先将源编码方案转换成一种中间编码方案,再将中间编码方案转换成目标编码方案。这样对于任何一种编码方案来说,仅需维护它与中间编码方案的转换数组即可。这个中间编码方案指的就是Unicode!如下图所示:
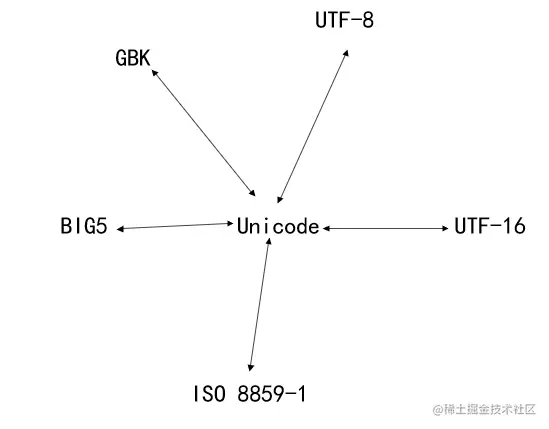
这样在将UTF-8编码值转换为GBK编码值时,需完成两步:
- 先将UTF-8编码值转换为Unicode值
- 再将Unicode值转换为GBK编码值
MySQL的实现
不像我们应用程序员直接调用某个库的进行字符编码转换的函数,MySQL为了尽量减少依赖,自己实现了各种字符编码方案以及它们之间的转换。我们下边以'我'字为例,看一下它是怎么实现从UTF-8编码方案转换成GBK编码方案的。
从UTF-8编码值获取对应的Unicode值
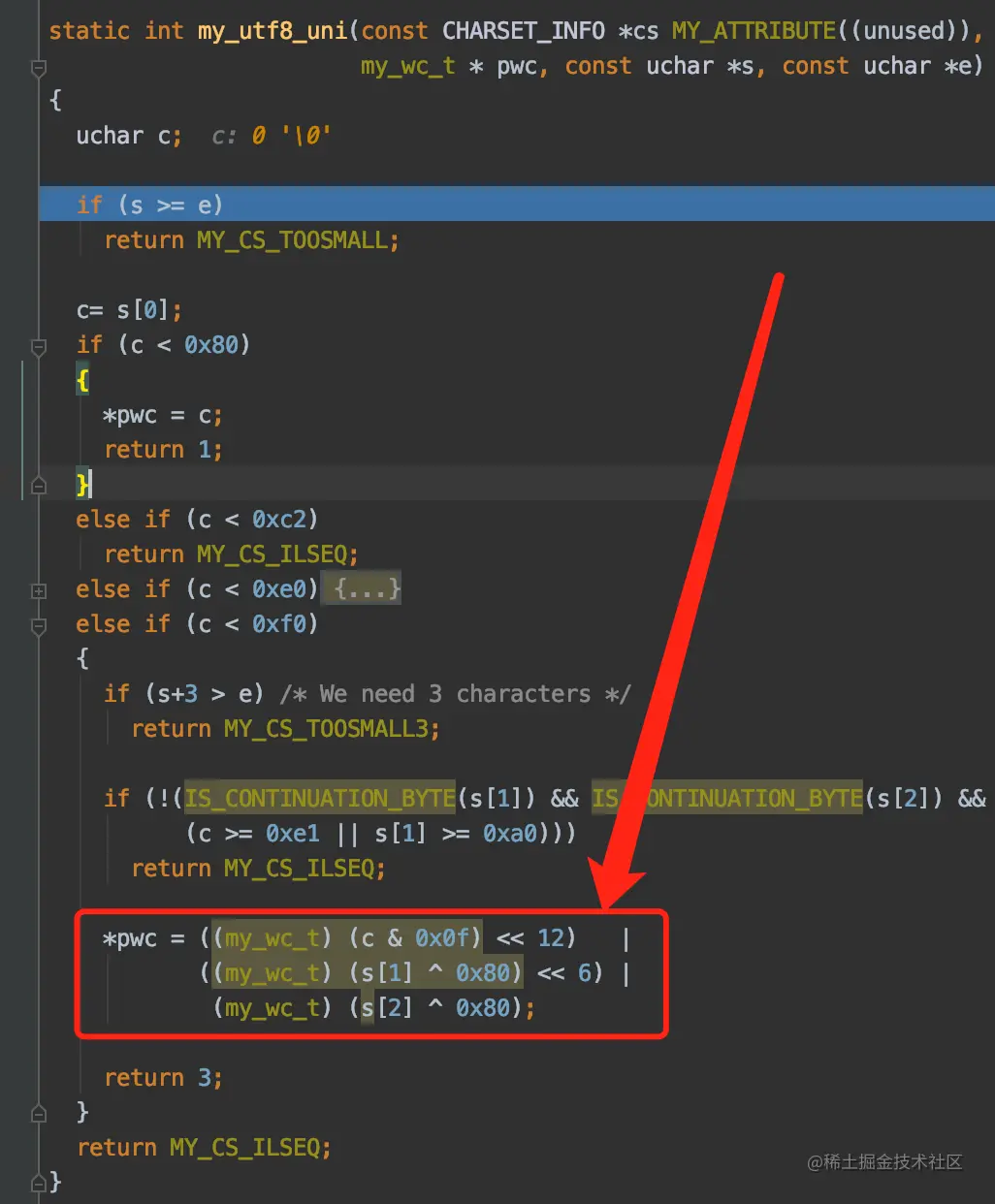
my_utf8_uni是用于获取UTF-8编码字符对应的Unicode值的函数,红色箭头指向的是实际操作过程。比方说字符'我'的UTF-8编码值是0xE68891,那就需要做如下操作:
((0xE6 & 0x0f) << 12) |((0x88 ^ 0x80) << 6) |(0x91 ^ 0x80)
得到的结果是十进制的25105,这个25105就是字符'我'对应的Unicode值
从Unicode值获取对应GBK编码值
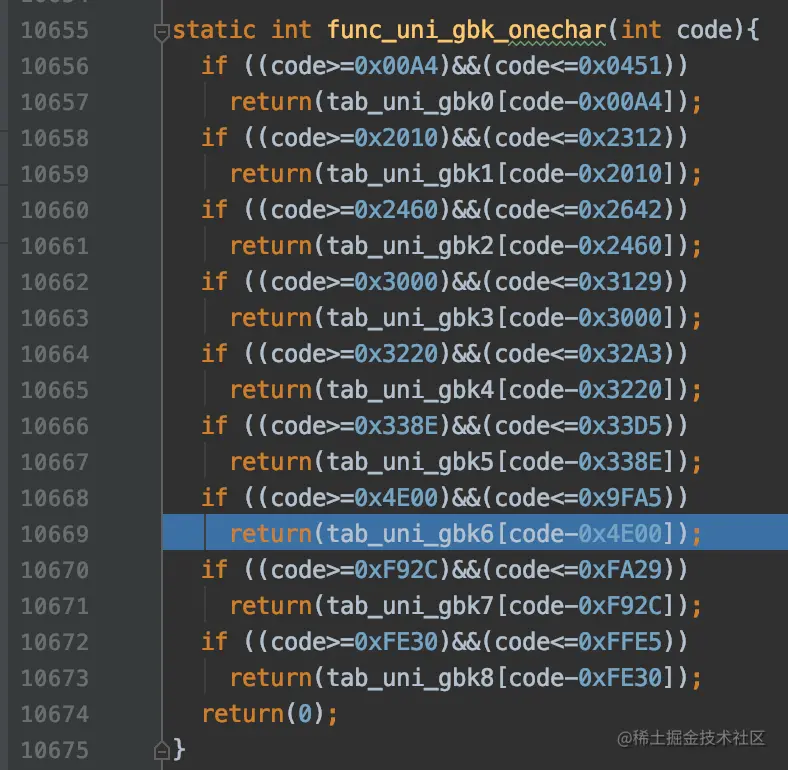
func_uni_gbk_onechar是根据Unicode值获取对应的GBK编码值的函数。从该函数的实现中可以看到,设计MySQL的大叔把包含在GBK编码方案中的字符对应的Unicode值分成了9个组,分别是tab_uni_gbk0~tab_uni_gbk8,当然,这些组中也包含了一些不属于GBK编码方案的字符对应的Unicode值,比方说第一个组tab_uni_gbk0:
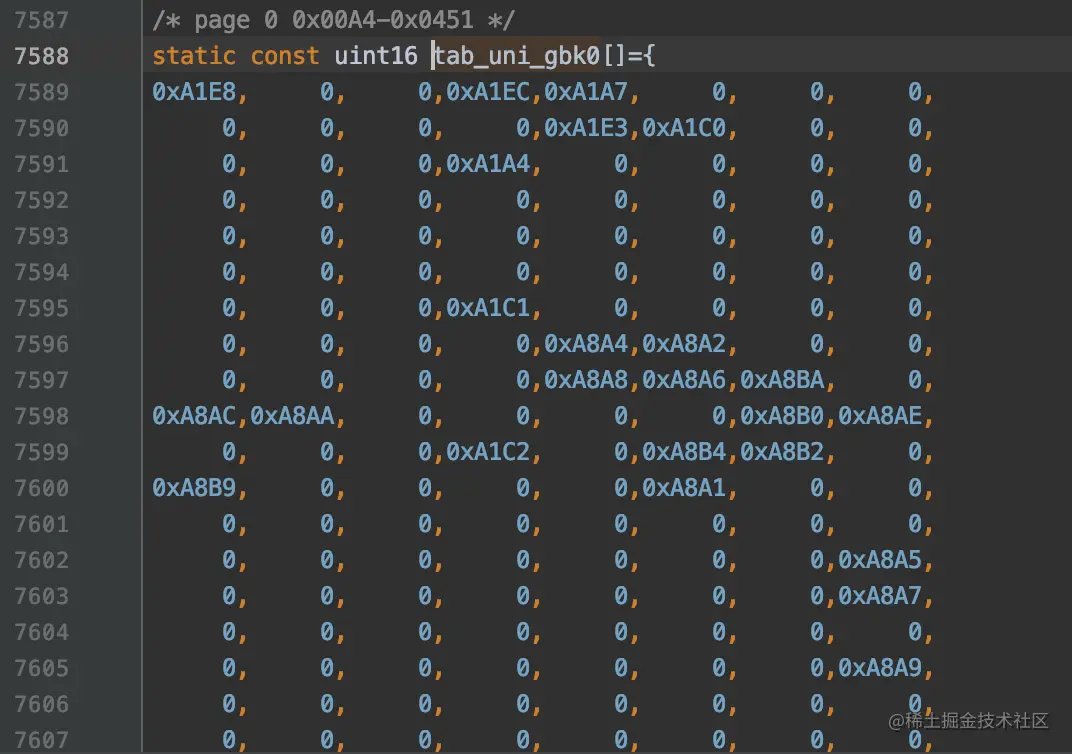
其中值为0的元素对应的字符就是不包含在GBK编码方案中的。
如果让每一个组中仅包含GBK字符的话,这会导致组划分的过多。出于在组的数量和浪费的存储空间方面做出取舍,就形成了现在这种划分了9个组的方案。
由于字符'我'对应的Unicode值25105其实是在tab_uni_gbk6中的,我们看一下数组tab_uni_gbk6的下标为25105-0x4E00,也就是5137的元素的值是什么:
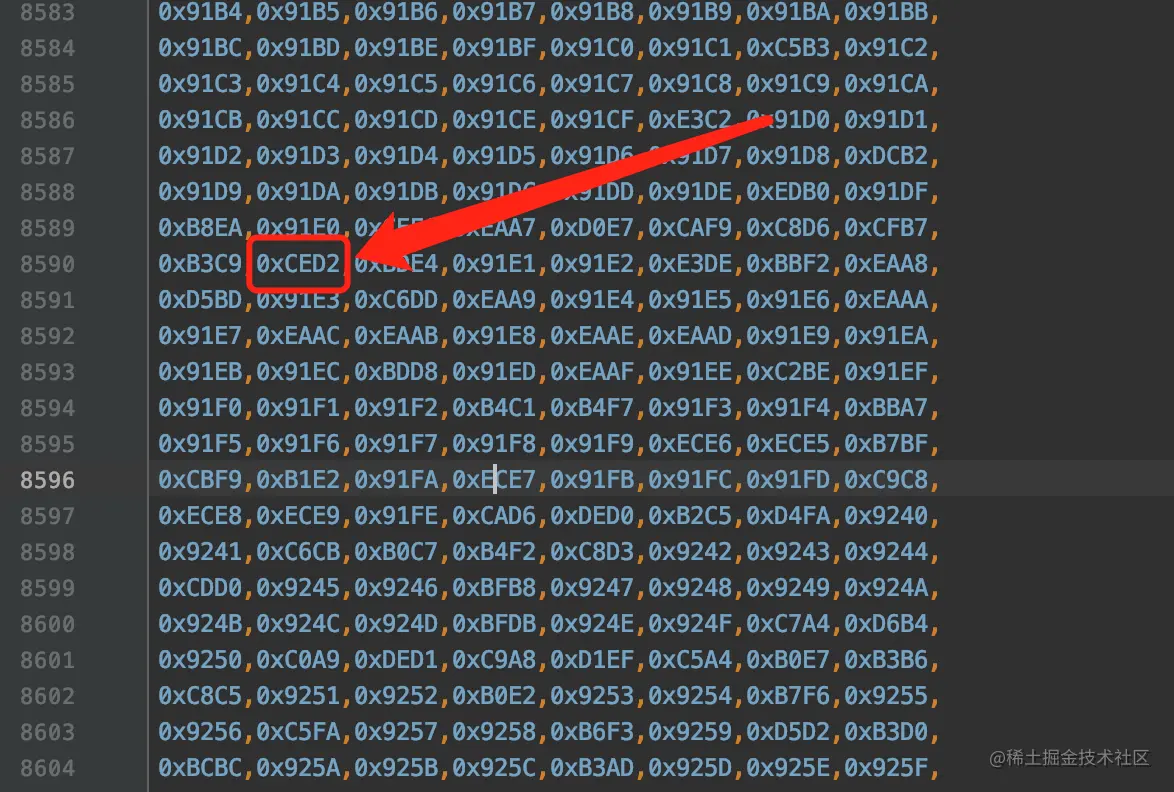
是他!是他!就是他!就是我们的0xCED2!
