听说有一个最左原则?这回终于讲清楚了
标签: MySQL是怎样运行的
准备工作
为了故事的顺利发展,我们需要先建立一个表:
CREATE TABLE single_table (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1),UNIQUE KEY uk_key2 (key2),KEY idx_key3 (key3),KEY idx_key_part(key_part1, key_part2, key_part3)) Engine=InnoDB CHARSET=utf8;
我们为这个single_table表建立了1个聚簇索引和4个二级索引,分别是:
为id列建立的聚簇索引。
为key1列建立的idx_key1二级索引。
为key2列建立的uk_key2二级索引,而且该索引是唯一二级索引。
为key3列建立的idx_key3二级索引。
为key_part1、key_part2、key_part3列建立的idx_key_part二级索引,这也是一个联合索引。
然后我们需要为这个表插入10000行记录,除id列外其余的列都插入随机值就好了,具体的插入语句我就不写了,自己写个程序插入吧(id列是自增主键列,不需要我们手动插入)。
我们画一下single_table表的聚簇索引的示意图:
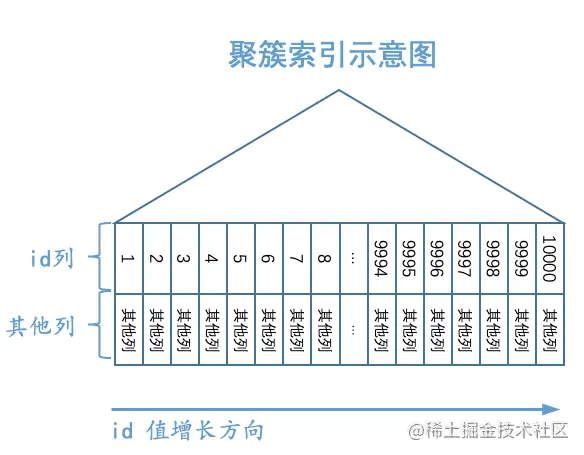
如图所示,我们把聚簇索引对应的复杂的B+树结构搞了一个极度精简版。可以看到,我们忽略掉了页的结构,直接把所有的叶子节点中的记录都放在一起展示,为了方便,我们之后就把聚簇索引叶子节点中的记录称为聚簇索引记录。虽然这个图很简陋,但是我们还是突出了聚簇索引一个非常重要的特点:聚簇索引记录是按照主键值由小到大的顺序排序的。当然,追求视觉上极致简洁的我们觉得图中的“其他列”也可以被略去,只需要保留id列即可,再次简化的B+树示意图就如下所示:
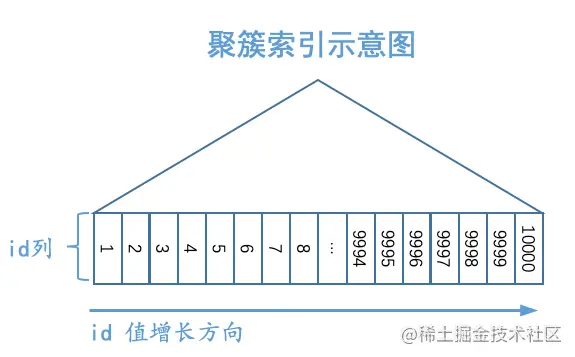
好了,再不能简化了,再简化就要把id列也删去了,就剩一个三角形了,那就真尴尬了。
通过聚簇索引对应的B+树,我们可以很容易的定位到主键值等于某个值的聚簇索引记录,比方说我们想通过这个B+树定位到id值为1438的记录,那么示意图就如下所示:
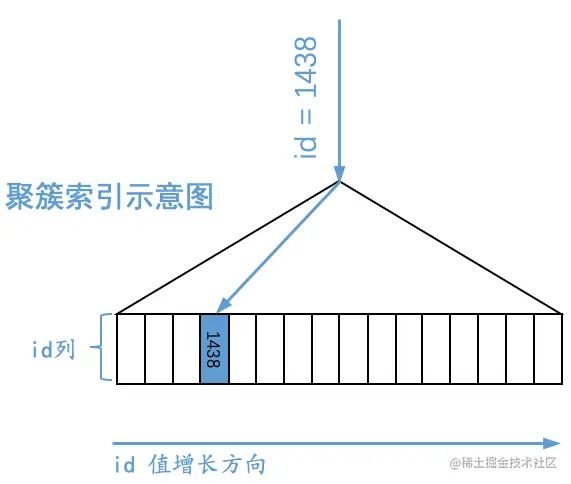
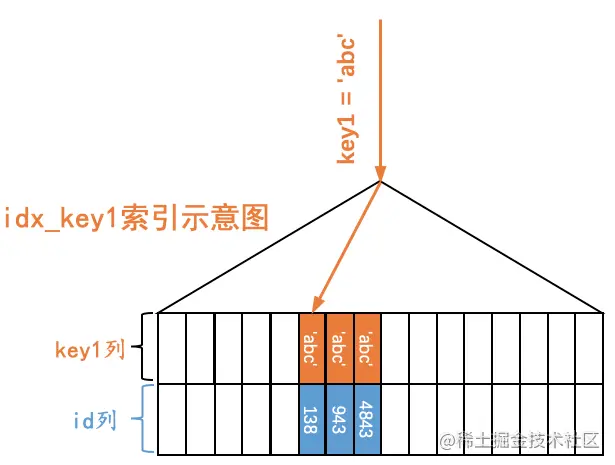
下边以二级索引idx_key1为例,画一下二级索引简化后的B+树示意图:
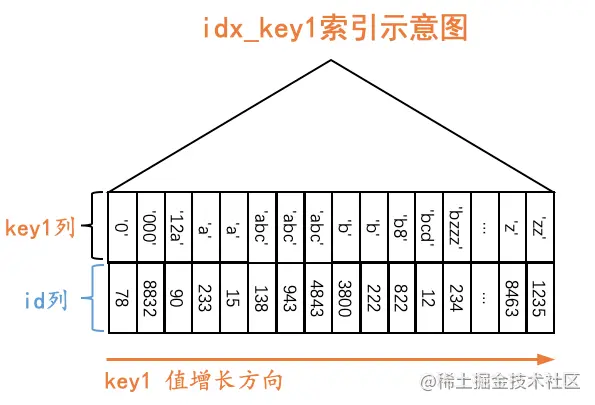
如图所示,我们在二级索引idx_key1对应的B+树中保留了叶子节点的记录,这些记录包括key1列以及id列,这些记录是按照key1列的值由小到大的顺序排序的,如果key1列的值相同,则按照id列的值进行排序。为了方便,我们之后就把二级索引叶子节点中的记录称为二级索引记录。
如果我们想查找key1值等于某个值的二级索引记录,那么可以通过idx_key1对应的B+树,很容易的定位到第一条key1列的值等于某个值的二级索引记录,然后沿着记录所在单向链表向后扫描即可。比方说我们想通过这个B+树定位到第一条key1值为’abc’的记录,那么示意图就如下所示:
扫描区间和边界条件
对于某个查询来说,最粗暴的执行方案就是扫描表中的所有记录,针对每一条记录都判断一下该记录是否符合搜索条件,如果符合的话就将其发送到客户端,否则就跳过该记录。这种执行方案也被称为全表扫描。对于使用InnoDB存储引擎的表来说,全表扫描意味着从聚簇索引第一个叶子节点的第一条记录开始,沿着记录所在的单向链表向后扫描,直到最后一个叶子节点的最后一条记录为止。虽然全表扫描是一种很笨的执行方案,但却是一种万能的执行方案,所有的查询都可以使用这种方案来执行。
我们之前介绍了利用B+树查找索引列值等于某个值的记录,这样可以明显减少需要扫描的记录数量。其实由于B+树的叶子节点中的记录是按照索引列值由小到大的顺序排序的,所以我们只扫描在某个区间或者某些区间中的记录也可以明显减少需要扫描的记录数量。比方说对于下边这个查询语句来说:
SELECT * FROM single_table WHERE id >= 2 AND id <= 100;
这个语句其实是想查找所有id值在[2, 100]这个区间中的聚簇索引记录,那么我们就可以通过聚簇索引对应的B+树快速地定位到id值为2的那条聚簇索引记录,然后沿着记录所在的单向链表向后扫描,直到某条聚簇索引记录的id值不在[2, 100]这个区间中为止(其实也就是直到id值不符合id<=100这个条件为止)。与扫描全部的聚簇索引记录相比,扫描id值在[2, 100]这个区间中的记录已经很大程度的减少了需要扫描的记录数量,所以提升了查询效率。为简便起见,我们把这个例子中需要扫描的记录的id值所在的区间称为扫描区间,把形成这个扫描区间的查询条件,也就是id >= 2 AND id <= 100称为形成这个扫描区间的边界条件。
小贴士:
其实对于全表扫描来说,相当于我们需要扫描id值在(-∞, +∞)这个区间中的记录,也就是说全表扫描对应的扫描区间就是(-∞, +∞)。
对于下边这个查询:
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
我们当然可以直接使用全表扫描的方式执行该查询,但是观察到该查询的搜索条件涉及到了key2列,而我们又正好为key2列建立了uk_key2索引,如果我们使用uk_key2索引执行这个查询的话,那么相当于从下边的三个扫描区间中获取二级索引记录:
- [1438, 1438],对应的边界条件就是key2 IN (1438)
- [6328, 6328],对应的边界条件就是key2 IN (6328)
- [38, 79],对应的边界条件就是key2 >= 38 AND key2 <= 79
这些扫描区间对应到数轴上的示意图就如下图所示:
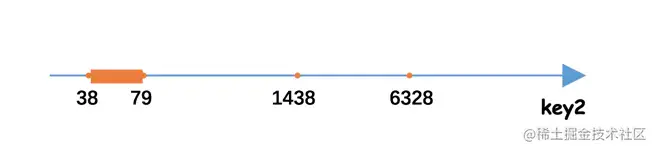
为方便起见,我们把像[1438, 1438]、[6328, 6328]这样只包含一个值的扫描区间称为单点扫描区间,把[38, 79]这样包含多个值的扫描区间称为范围扫描区间。另外,由于我们的查询列表是*,也就是需要读取完整的用户记录,所以从上述的扫描区间中每获取一条二级索引记录时,就需要根据该二级索引记录的id列的值执行回表操作,也就是到聚簇索引中找到相应的聚簇索引记录。
小贴士:
其实我们不仅仅可以使用uk_key2执行上述查询,使用idx_key1、idx_key3、idx_keypart都可以执行上述查询。以idx_key1为例,很显然我们无法通过搜索条件形成合适的扫描区间来减少需要扫描的idx_key二级索引记录数量,只能扫描idx_key1的全部二级索引记录。针对获取到的每一条二级索引记录,都需要执行回表操作来获取完整的用户记录。我们也可以说此时使用idx_key1执行查询时对应的扫描区间就是(-∞, +∞)。
这样子虽然行得通,但我们图啥呢?最粗暴的全表扫描方式已经要扫描全部的聚簇索引记录了,你这里除了要访问全部的聚簇索引记录,还要扫描全部的idx_key1二级索引记录,这不是费力不讨好么。在这个过程中没有减少需要扫描的记录数量,反而效率比全表扫描更差,所以如果我们想使用某个索引来执行查询,但是又无法通过搜索条件形成合适的扫描区间来减少需要扫描的记录数量时,那么我们是不考虑使用这个索引执行查询的。
并不是所有的搜索条件都可以成为边界条件,比方说下边这个查询:
SELECT * FROM single_table WHERE key1 < 'a' AND key3 > 'z' AND common_field = 'abc';
那么:
如果我们使用idx_key1执行查询的话,那么相应的扫描区间就是(-∞, ‘a’),形成该扫描区间的边界条件就是key1 < ‘a’,而key3 > ‘z’ AND common_field = ‘abc’就是普通的搜索条件,这些普通的搜索条件需要在获取到idx_key1的二级索引记录后,再执行回表操作,获取到完整的用户记录后才能去判断它们是否成立。
如果我们使用idx_key3执行查询的话,那么相应的扫描区间就是(‘z’, +∞),形成该扫描区间的边界条件就是key3 > ‘z’,而key1 < ‘a’ AND common_field = ‘abc’就是普通的搜索条件,这些普通的搜索条件需要在获取到idx_key3的二级索引记录后,再执行回表操作,获取到完整的用户记录后才能去判断它们是否成立。
使用联合索引执行查询时对应的扫描区间
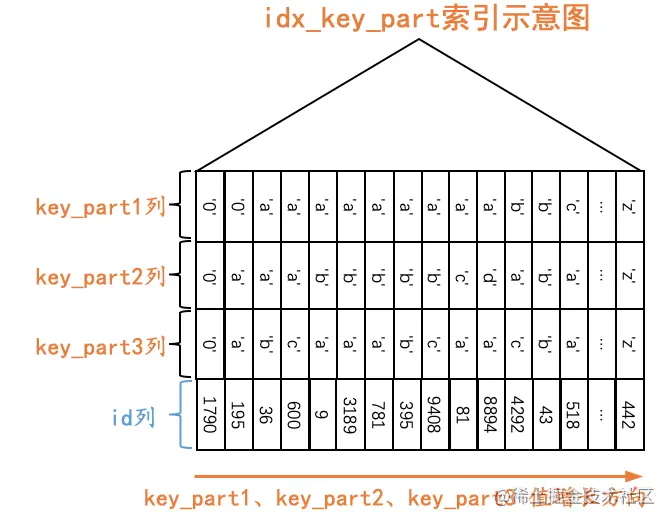
联合索引的索引列包含多个列,B+树每一层页面以及每个页面中的记录采用的排序规则较为复杂,以single_table表的idx_key_part联合索引为例,它采用的排序规则如下所示:
- 先按照key_part1列的值进行排序。
- 在key_part1列的值相同的情况下,再按照key_part2列的值进行排序。
- 在key_part1和key_part2列的值都相同的情况下,再按照key_part3列的值进行排序。
我们画一下idx_key_part索引的示意图:
对于下边这个查询Q1来说:
Q1:SELECT * FROM single_table WHERE key_part1 = 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以所有符合key_part1 = ‘a’条件的记录肯定是相邻的,我们可以定位到第一条符合key_part1 = ‘a’条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 = ‘a’条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
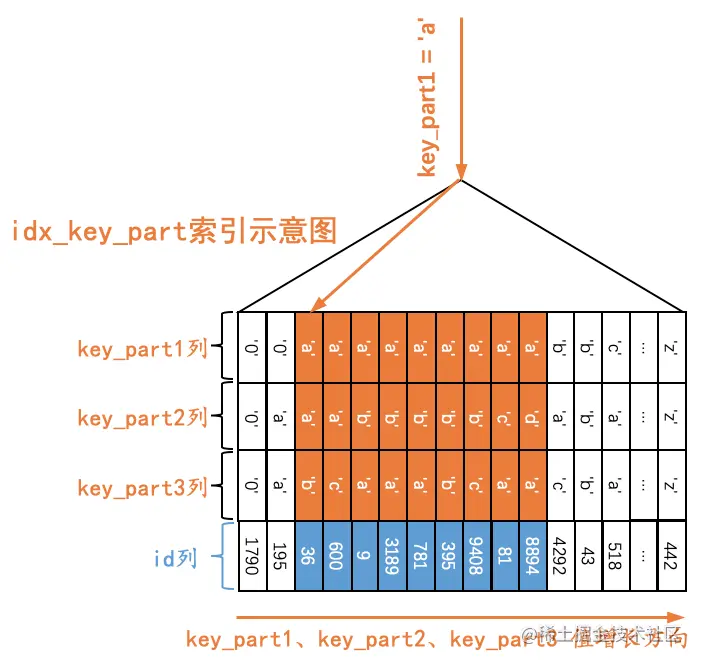
也就是说,如果我们使用idx_key_part索引执行查询Q1时,对应的扫描区间就是[‘a’, ‘a’],形成这个扫描区间的条件就是key_part1 = ‘a’。
对于下边这个查询Q2来说:
Q2:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 = 'b';
由于二级索引记录是先按照key_part1列的值进行排序的;在key_part1列的值相等的情况下,再按照key_part2列进行排序。所以符合key_part1 = ‘a’ AND key_part2 = ‘b’条件的二级索引记录肯定是相邻的,我们可以定位到第一条符合key_part1=’a’ AND key_part2=’b’条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1=’a’条件或者key_part2=’b’条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。

也就是说,如果我们使用idx_key_part索引执行查询Q2时,可以形成扫描区间[(‘a’, ‘b’), (‘a’, ‘b’)],形成这个扫描区间的条件就是key_part1 = ‘a’ AND key_part2 = ‘b’。
对于下边这个查询Q3来说:
Q3:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c';
由于二级索引记录是先按照key_part1列的值进行排序的;在keypart1列的值相等的情况下,再按照key_part2列进行排序;在key_part1和key_part2列的值都相等的情况下,再按照key_part3列进行排序。所以符合key_part1 = ‘a’ AND key_part2 = ‘b’ AND key_part3 = ‘c’条件的二级索引记录肯定是相邻的,我们可以定位到第一条符合key_part1=’a’ AND key_part2=’b’ AND key_part3=’c’条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1=’a’条件或者key_part2=’b’条件或者key_part3=’c’条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作),我们就不画示意图了。如果我们使用idx_key_part索引执行查询Q3时,可以形成扫描区间[(‘a’, ‘b’, ‘c’), (‘a’, ‘b’, ‘c’)],形成这个扫描区间的条件就是key_part1 = ‘a’ AND key_part2 = ‘b’ AND key_part3 = ‘c’。
对于下边这个查询Q4来说:
Q4:SELECT * FROM single_table WHERE key_part1 < 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以所有符合key_part1 < ‘a’条件的记录肯定是相邻的,我们可以定位到第一条符合key_part1 < ‘a’条件的记录(其实就是idx_key_part索引第一个叶子节点的第一条记录),然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 < ‘a’为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
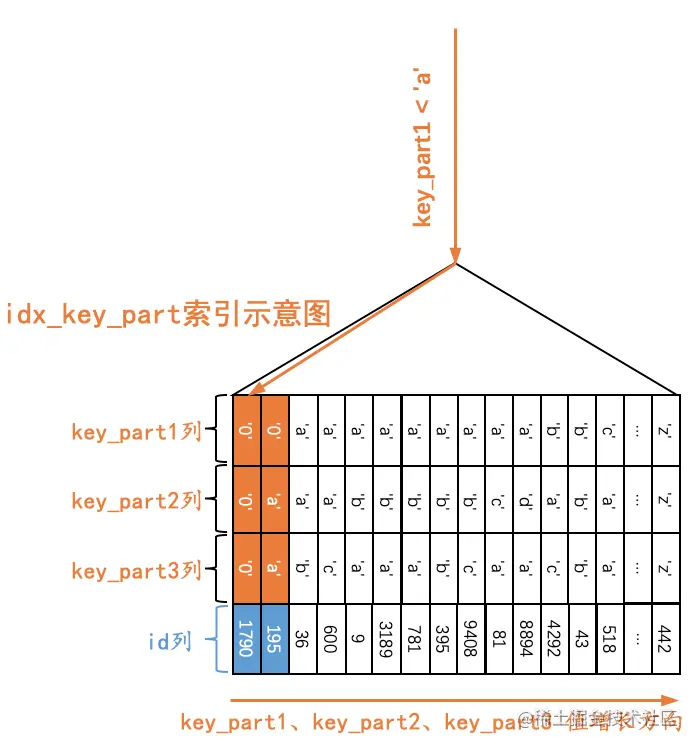
也就是说,如果我们使用idx_key_part索引执行查询Q4时,可以形成扫描区间(-∞, ‘a’),形成这个扫描区间的条件就是key_part1 < ‘a’。
对于下边这个查询Q5来说:
Q5:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 > 'a' AND key_part2 < 'd';
由于二级索引记录是先按照key_part1列的值进行排序的;在key_part1列的值相等的情况下,再按照key_part2列进行排序。也就是说在符合key_part1 = ‘a’条件的二级索引记录中,是按照key_part2列的值进行排序的,那么此时符合key_part1 = ‘a’ AND key_part2 > ‘a’ AND key_part2 < ‘d’条件的二级索引记录肯定是相邻的。我们可以定位到第一条符合key_part1=’a’ AND key_part2 > ‘a’ AND key_part2 < ‘c’条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1=’a’条件或者key_part2 > ‘a’条件或者key_part2 < ‘d’条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
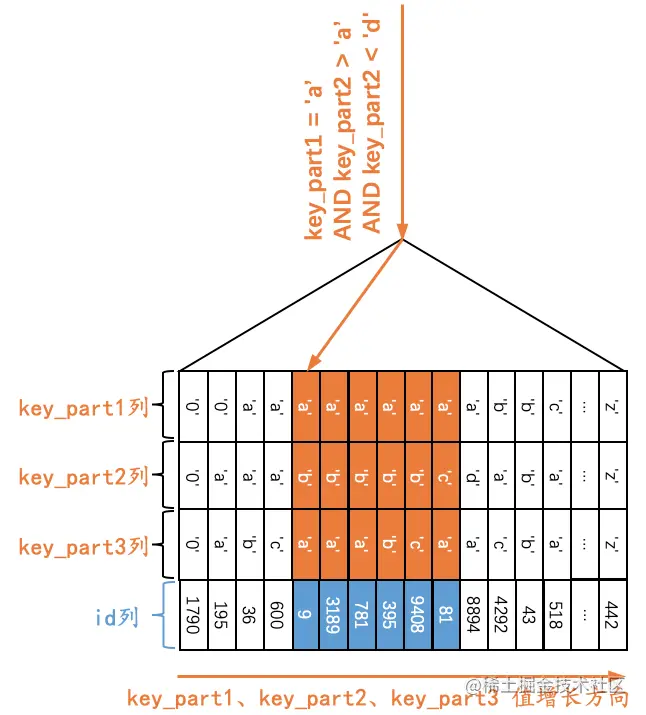
也就是说,如果我们使用idx_key_part索引执行查询Q5时,可以形成扫描区间((‘a’, ‘a’), (‘a’, ‘d’)),形成这个扫描区间的条件就是key_part1 = ‘a’ AND key_part2 > ‘a’ AND key_part2 < ‘d’。
对于下边这个查询Q6来说:
Q6:SELECT * FROM single_table WHERE key_part2 = 'a';
由于二级索引记录不是直接按照key_part2列的值排序的,所以符合key_part2 = ‘a’的二级索引记录可能并不相邻,也就意味着我们不能通过这个key_part2 = ‘a’搜索条件来减少需要扫描的记录数量。在这种情况下,我们是不会使用idx_key_part索引执行查询的。
对于下边这个查询Q7来说:
Q7:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part3 = 'c';
由于二级索引记录是先按照key_part1列的值进行排序的,所以符合key_part1 = ‘a’条件的二级索引记录肯定是相邻的,但是对于符合key_part1 = ‘a’条件的二级索引记录来说,并不是直接按照key_part3列进行排序的,也就是说我们不能根据搜索条件key_part3 = ‘c’来进一步减少需要扫描的记录数量。那么如果我们使用idx_key_part索引执行查询的话,可以定位到第一条符合key_part1=’a’条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 = ‘a’条件为止。所以在使用idx_key_part索引执行查询Q7的过程中,对应的扫描区间其实是[‘a’, ‘a’],形成该扫描区间的搜索条件是key_part1 = ‘a’,与key_part3 = ‘c’无关。
小贴士:
针对获取到的每一条二级索引记录,如果没有开启索引条件下推特性的话,则必须先进行回表操作,获取到完整的用户记录后再判断key_part3 = ‘c’这个条件是否成立;如果开启了索引条件下推特性的话,可以立即判断该二级索引记录是否符合key_part3 = ‘c’这个条件,如果符合则再进行回表操作,如果不符合则不进行回表操作,直接跳到下一条二级索引记录。索引条件下推特性是在MySQL 5.6中引入的,默认是开启的。
对于下边这个查询Q8来说:
Q8:SELECT * FROM single_table WHERE key_part1 < 'b' AND key_part2 = 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以符合key_part1 < ‘b’条件的二级索引记录肯定是相邻的,但是对于符合key_part1 < ‘b’条件的二级索引记录来说,并不是直接按照key_part2列进行排序的,也就是说我们不能根据搜索条件key_part2 = ‘a’来进一步减少需要扫描的记录数量。那么如果我们使用idx_key_part索引执行查询的话,可以定位到第一条符合key_part1<’b’条件的记录(其实就是idx_key_part索引第一个叶子节点的第一条记录),然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 < ‘b’条件为止,如下图所示。
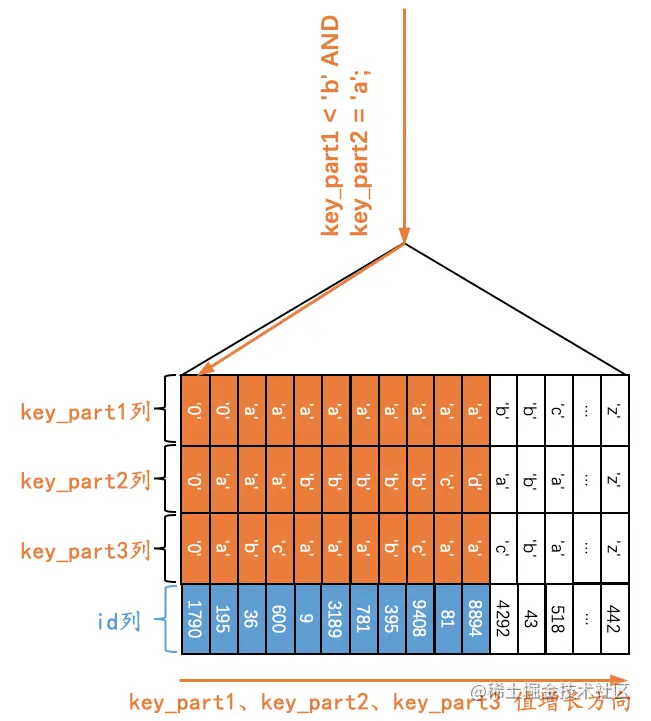
所以在使用idx_key_part索引执行查询Q8的过程中,对应的扫描区间其实是[-∞, ‘b’),形成该扫描区间的搜索条件是key_part1 < ‘b’,与key_part2 = ‘a’无关。
对于下边这个查询Q9来说:
Q9:SELECT * FROM single_table WHERE key_part1 <= 'b' AND key_part2 = 'a';
很显然Q8和Q9长得非常像,只不过在涉及key_part1的条件中,Q8中的条件是key_part1 < ‘b’,Q9中的条件是key_part1 <= ‘b’。很显然符合key_part1 <= ‘b’条件的二级索引记录是相邻的,但是对于符合key_part1 <= ‘b’条件的二级索引记录来说,并不是直接按照key_part2列进行排序的。但是,我这里说但是哈,对于符合key_part1 = ‘b’的二级索引记录来说,是按照key_part2列的值进行排序的。那么我们在确定需要扫描的二级索引记录的范围时,当二级索引记录的key_part1列值为’b’时,我们也可以通过key_part2 = ‘a’这个条件来减少需要扫描的二级索引记录范围,也就是说当我们扫描到第一条不符合 key_part1 = ‘b’ AND key_part2 = ‘a’条件的记录时,就可以结束扫描,而不需要将所有key_part1列值为’b’的记录扫描完,示意图如下:
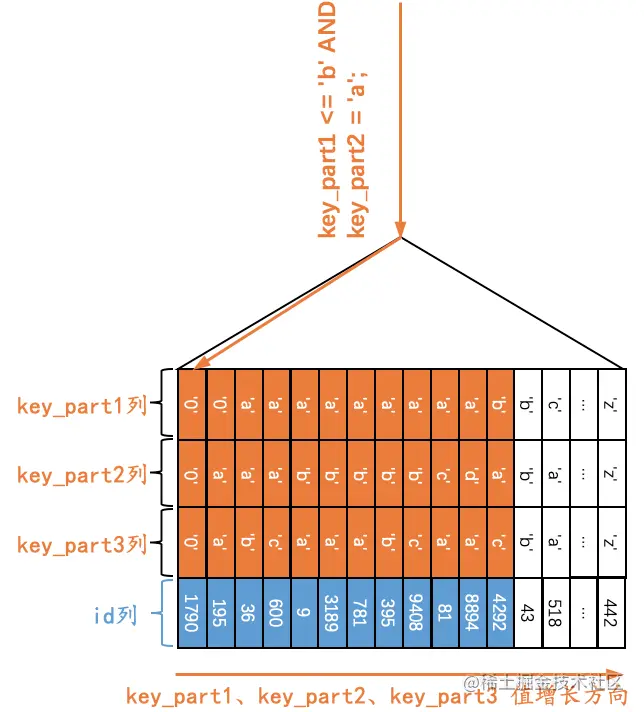
也就是说,如果我们使用idx_key_part索引执行查询Q9时,可以形成扫描区间((-∞, -∞), (‘b’, ‘a’)),形成这个扫描区间的条件就是key_part1 <= ‘b’ AND key_part2 = ‘a’。对比查询Q8,我们必须将所有符合key_part1 < ‘b’的记录都扫描完,key_part2 = ‘a’这个条件在查询Q8中并不能起到减少需要扫描的二级索引记录范围的作用。
可能将查询Q9转换为下边的这个形式后更容易理解使用idx_key_part索引执行它时对应的扫描区间以及形成扫描区间的条件:
SELECT * FROM single_table WHERE (key_part1 < 'b' AND key_part2 = 'a') OR (key_part1 = 'b' AND key_part2 = 'a');
