第18章、游标的使用
标签: MySQL是怎样使用的新版
游标简介
截止到现在为止,我们只能使用SELECT ... INTO ...语句将一条记录的各个列值赋值到多个变量里,比如在前边的get_score_data存储过程里有这样的语句:
SELECT MAX(score), MIN(score), AVG(score) FROM student_score WHERE subject = s INTO max_score, min_score, avg_score;
但是如果某个查询语句的结果集中有多条记录的话,我们就无法把它们赋值给某些变量了~ 所以为了方便我们去访问这些有多条记录的结果集,MySQL中引入了游标的概念。
我们下边以对t1表的查询为例来介绍一下游标,比如我们有这样一个查询:
mysql> SELECT m1, n1 FROM t1;+------+------+| m1 | n1 |+------+------+| 1 | a || 2 | b || 3 | c || 4 | d |+------+------+4 rows in set (0.00 sec)mysql>
这个SELECT m1, n1 FROM t1查询语句对应的结果集有4条记录,游标其实就是用来标记结果集中我们正在访问的某一条记录。初始状态下它标记结果集中的第一条记录,就像这样:
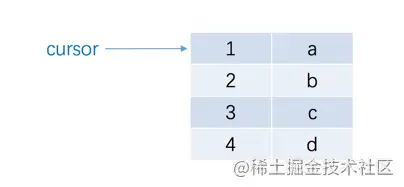
我们可以根据这个游标取出它对应记录的信息,随后再移动游标,让它执向下一条记录。游标既可以用在存储函数中,也可以用在存储过程中,我们下边以存储过程为例来说明游标的使用方式,它的使用大致分成这么四个步骤:
- 创建游标
- 打开游标
- 通过游标访问记录
- 关闭游标
下边来详细介绍这几个步骤的详细情况。
创建游标
在创建游标的时候,需要指定一下与游标关联的查询语句,语法如下:
DECLARE 游标名称 CURSOR FOR 查询语句;
我们定义一个存储过程试一试:
CREATE PROCEDURE cursor_demo()BEGINDECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;END
这样名叫t1_record_cursor的游标就创建成功了。
小贴士: 如果存储程序中也有声明局部变量的语句,创建游标的语句一定要放在局部变量声明后头。
打开和关闭游标
在创建完游标之后,我们需要手动打开和关闭游标,语法也简单:
OPEN 游标名称;CLOSE 游标名称;
打开游标意味着执行查询语句,创建一个该查询语句得到的结果集关联起来的游标,关闭游标意味着会释放该游标相关的资源,所以一旦我们使用完了游标,就要把它关闭掉。当然如果我们不显式的使用CLOSE语句关闭游标的话,在该存储过程的END语句执行完之后会自动关闭的。
我们再来修改一下上边的cursor_demo存储过程:
CREATE PROCEDURE cursor_demo()BEGINDECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;OPEN t1_record_cursor;CLOSE t1_record_cursor;END
使用游标获取记录
在知道怎么打开和关闭游标之后,我们正式来唠叨一下如何使用游标来获取结果集中的记录,获取记录的语句长这样:
FETCH 游标名 INTO 变量1, 变量2, ... 变量n
这个语句的意思就是把指定游标对应记录的各列的值依次赋值给INTO后边的各个变量。我们来继续改写一下cursor_demo存储过程:
CREATE PROCEDURE cursor_demo()BEGINDECLARE m_value INT;DECLARE n_value CHAR(1);DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;OPEN t1_record_cursor;FETCH t1_record_cursor INTO m_value, n_value;SELECT m_value, n_value;CLOSE t1_record_cursor;END $
我们来调用一下这个存储过程:
mysql> CALL cursor_demo();+---------+---------+| m_value | n_value |+---------+---------+| 1 | a |+---------+---------+1 row in set (0.00 sec)Query OK, 0 rows affected (0.00 sec)mysql>
额,奇怪,t1表里有4条记录,我们这里只取出了第一条?是的,如果想获取多条记录,那需要把 FETCH 语句放到循环语句中,我们再来修改一下cursor_demo存储过程:
CREATE PROCEDURE cursor_demo()BEGINDECLARE m_value INT;DECLARE n_value CHAR(1);DECLARE record_count INT;DECLARE i INT DEFAULT 0;DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;SELECT COUNT(*) FROM t1 INTO record_count;OPEN t1_record_cursor;WHILE i < record_count DOFETCH t1_record_cursor INTO m_value, n_value;SELECT m_value, n_value;SET i = i + 1;END WHILE;CLOSE t1_record_cursor;END
这次我们又多使用了两个变量,record_count表示t1表中的记录行数,i表示当前游标对应的记录位置。每调用一次 FETCH 语句,游标就移动到下一条记录的位置。看一下调用效果:
mysql> CALL cursor_demo();+---------+---------+| m_value | n_value |+---------+---------+| 1 | a |+---------+---------+1 row in set (0.00 sec)+---------+---------+| m_value | n_value |+---------+---------+| 2 | b |+---------+---------+1 row in set (0.00 sec)+---------+---------+| m_value | n_value |+---------+---------+| 3 | c |+---------+---------+1 row in set (0.00 sec)+---------+---------+| m_value | n_value |+---------+---------+| 4 | d |+---------+---------+1 row in set (0.00 sec)Query OK, 0 rows affected (0.00 sec)mysql>
这回就把t1表中全部的记录就都遍历完了。
遍历结束时的执行策略
上边介绍的遍历方式需要我们首先获得查询语句结构集中记录的条数,也就是需要先执行下边这条语句:
SELECT COUNT(*) FROM t1 INTO record_count;
我们之所以要获取结果集中记录的条数,是因为我们需要一个结束循环的条件,当调用FETCH语句的次数与结果集中记录条数相等时就结束循环。
其实在FETCH语句获取不到记录的时候会触发一个事件,从而我们可以得知所有的记录都被获取过了,然后我们就可以去主动的停止循环。MySQL中响应这个事件的语句如下:
DECLARE CONTINUE HANDLER FOR NOT FOUND 处理语句;
只要我们在存储过程中写了这个语句,那么在FETCH语句获取不到记录的时候,服务器就会执行我们填写的处理语句。
!小贴士:处理语句可以是简单的一条语句,也可以是由BEGIN ... END 包裹的多条语句。
我们接下来再来改写一下cursor_demo存储过程:
CREATE PROCEDURE cursor_demo()BEGINDECLARE m_value INT;DECLARE n_value CHAR(1);DECLARE not_done INT DEFAULT 1;DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;DECLARE CONTINUE HANDLER FOR NOT FOUND SET not_done = 0;OPEN t1_record_cursor;flag: LOOPFETCH t1_record_cursor INTO m_value, n_value;IF not_done = 0 THENLEAVE flag;END IF;SELECT m_value, n_value, not_done;END LOOP flag;CLOSE t1_record_cursor;END
我们声明了一个默认值为1的not_done变量和一个这样的语句:
DECLARE CONTINUE HANDLER FOR NOT FOUND SET not_done = 0;
not_done变量的值为1时表明遍历结果集的过程还没有结束,当FETCH语句无法获取更多记录时,就会触发一个事件,从而导致MySQL服务器主动调用上边的这个语句将not_done变量的值改为0。另外,我们把原先的WHILE语句替换成了LOOP语句,直接在LOOP语句的循环体中判断not_done变量的值,当它的值为0时就主动跳出循环。
让我们调用一下这个存储过程看一下效果:
mysql> call cursor_demo;+---------+---------+----------+| m_value | n_value | not_done |+---------+---------+----------+| 1 | a | 1 |+---------+---------+----------+1 row in set (0.05 sec)+---------+---------+----------+| m_value | n_value | not_done |+---------+---------+----------+| 2 | b | 1 |+---------+---------+----------+1 row in set (0.05 sec)+---------+---------+----------+| m_value | n_value | not_done |+---------+---------+----------+| 3 | c | 1 |+---------+---------+----------+1 row in set (0.06 sec)+---------+---------+----------+| m_value | n_value | not_done |+---------+---------+----------+| 4 | d | 1 |+---------+---------+----------+1 row in set (0.06 sec)Query OK, 0 rows affected (0.07 sec)mysql>
