第12章、连接查询
标签: MySQL是怎样使用的新版
再次认识关系表
我们之前一直使用student_info和student_score两个表来分别存储学生的基本信息和学生的成绩信息,其实合并成一张表也不是不可以,假设将两张表合并后的新表名称为student_merge,那它应该长这样:
student_merge表
| number | name | sex | id_number | department | major | enrollment_time | subject | score |
|---|---|---|---|---|---|---|---|---|
| 20180101 | 杜子腾 | 男 | 158177199901044792 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 母猪的产后护理 | 78 |
| 20180101 | 杜子腾 | 男 | 158177199901044792 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 论萨达姆的战争准备 | 88 |
| 20180102 | 杜琦燕 | 女 | 151008199801178529 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 母猪的产后护理 | 100 |
| 20180102 | 杜琦燕 | 女 | 151008199801178529 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 论萨达姆的战争准备 | 98 |
| 20180103 | 范统 | 男 | 17156319980116959X | 计算机学院 | 软件工程 | 2018-09-01 | 母猪的产后护理 | 59 |
| 20180103 | 范统 | 男 | 17156319980116959X | 计算机学院 | 软件工程 | 2018-09-01 | 论萨达姆的战争准备 | 61 |
| 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 | 母猪的产后护理 | 55 |
| 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 | 论萨达姆的战争准备 | 46 |
| 20180105 | 范剑 | 男 | 181048200008156368 | 航天学院 | 飞行器设计 | 2018-09-01 | NULL | NULL |
| 20180106 | 朱逸群 | 男 | 197995199801078445 | 航天学院 | 电子信息 | 2018-09-01 | NULL | NULL |
有了这个合并后的表,我们就可以在一个查询语句中既查询到学生的基本信息,也查询到学生的成绩信息,比如这个查询语句:
SELECT number, name, major, subject, score FROM student_merge;
其中查询列表处的name和major属于学生的基本信息,subject和score属于学生的成绩信息,而number既属于成绩信息也属于基本信息,我们可以在一个对student_merge表的查询语句中很轻松的把这些信息都查询出来。但是别忘了一个学生可能会有很多门学科的成绩信息,也就是说每当我们想为一个学生增加一门学科的成绩信息时,我们必须把他的基本信息再抄一遍,这种同一个学生的基本信息被冗余存储会带来下边的问题:
问题一:浪费存储空间。
问题二:当修改某个学生的基本信息时必须修改多处,很容易造成信息的不一致,增大维护的困难。
所以为了尽可能少的存储冗余信息,一开始我们就把这个所谓的student_merge表拆分成了student_info和student_score表,但是这两张表之间有某种关系作为纽带,这里的某种关系指的就是两个表都拥有的number列。
连接的概念
拆分之后的表的确解决了数据冗余问题,但是查询数据却成了一个问题。截至目前为止,在我们介绍的查询方式中,查询结果集只能是一个表中的一个列或者多个列,也就是说到目前为止还没有一种可以在一条查询语句中把某个学生的number、name、major、subject、score这几个信息都查询出来的方式。
小贴士: 虽然我们前边介绍的子查询可以在一个查询语句中涉及到多个表,但是整个查询语句最终产生的结果集还是用来展示外层查询的结果,子查询的结果只是被当作中间结果来使用。
时代在召唤一种可以在一个查询语句结果集中展示多个表的信息的方式,连接查询承担了这个艰巨的历史使命。当然,为了故事的顺利发展,我们先建立两个简单的表并给它们填充一点数据:
mysql> CREATE TABLE t1 (m1 int, n1 char(1));Query OK, 0 rows affected (0.02 sec)mysql> CREATE TABLE t2 (m2 int, n2 char(1));Query OK, 0 rows affected (0.02 sec)mysql> INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c');Query OK, 3 rows affected (0.00 sec)Records: 3 Duplicates: 0 Warnings: 0mysql> INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd');Query OK, 3 rows affected (0.00 sec)Records: 3 Duplicates: 0 Warnings: 0mysql>
我们成功建立了t1、t2两个表,这两个表都有两个列,一个是INT类型的,一个是CHAR(1)类型的,填充好数据的两个表长这样:
mysql> SELECT * FROM t1;+------+------+| m1 | n1 |+------+------+| 1 | a || 2 | b || 3 | c |+------+------+3 rows in set (0.00 sec)mysql> SELECT * FROM t2;+------+------+| m2 | n2 |+------+------+| 2 | b || 3 | c || 4 | d |+------+------+3 rows in set (0.00 sec)mysql>
连接的本质就是把各个表中的记录都取出来依次匹配的组合加入结果集并返回给用户。我们把t1和t2两个表连接起来的过程如下图所示:
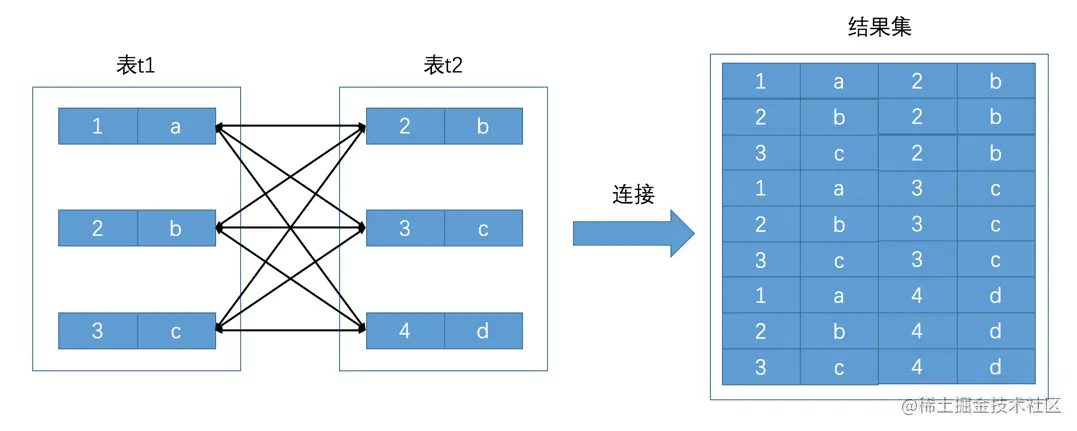
这个过程看起来就是把t1表的记录和t2表的记录连起来组成新的更大的记录,所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就可以称之为笛卡尔积。因为表t1中有3条记录,表t2中也有3条记录,所以这两个表连接之后的笛卡尔积就有3×3=9行记录。在MySQL中,连接查询的语法也很随意,只要在FROM语句后边跟多个用逗号,隔开的表名就好了,比如我们把t1表和t2表连接起来的查询语句可以写成这样:
mysql> SELECT * FROM t1, t2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 1 | a | 2 | b || 2 | b | 2 | b || 3 | c | 2 | b || 1 | a | 3 | c || 2 | b | 3 | c || 3 | c | 3 | c || 1 | a | 4 | d || 2 | b | 4 | d || 3 | c | 4 | d |+------+------+------+------+9 rows in set (0.00 sec)
查询列表处的*代表从FROM语句后列出的表中选取每个列,上边的查询语句其实和下边这几种写法都是等价的:
写法一:
SELECT t1.m1, t1.n1, t2.m2, t2.n2 FROM t1, t2;
这种写法是将`t1`、`t2`表中的列名都显式的写出来,也就是使用了列的全限定名。
写法二:
SELECT m1, n1, m2, n2 FROM t1, t2;
由于`t1`、`t2`表中的列名并不重复,所以没有可能让服务器懵逼的二义性,在查询列表上直接使用列名也是可以的。
写法三:
SELECT t1.*, t2.* FROM t1, t2;
这种写法意思就是查询`t1`表的全部的列,`t2`表的全部的列。
连接过程简介
如果我们乐意,我们可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接起来产生的笛卡尔积可能是非常巨大的。比方说3个100行记录的表连接起来产生的笛卡尔积就有100×100×100=1000000行数据!所以在连接的时候过滤掉特定记录组合是有必要的,在连接查询中的过滤条件可以分成两种:
涉及单表的条件
这种只涉及单表的过滤条件我们之前都提到过一万遍了,我们之前也一直称为
搜索条件,比如t1.m1 > 1是只针对t1表的过滤条件,t2.n2 < 'd'是只针对t2表的过滤条件。涉及两表的条件
这种过滤条件我们之前没见过,比如
t1.m1 = t2.m2、t1.n1 > t2.n2等,这些条件中涉及到了两个表,我们稍后会仔细分析这种过滤条件是如何使用的哈。
下边我们就要看一下携带过滤条件的连接查询的大致执行过程了,比方说下边这个查询语句:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
在这个查询中我们指明了这三个过滤条件:
t1.m1 > 1t1.m1 = t2.m2t2.n2 < 'd'
那么这个连接查询的大致执行过程如下:
首先确定第一个需要查询的表,这个表称之为
驱动表。此处假设使用t1作为驱动表,那么就需要到t1表中找满足t1.m1 > 1的记录,符合这个条件的t1表记录如下所示:+------+------+| m1 | n1 |+------+------+| 2 | b || 3 | c |+------+------+2 rows in set (0.01 sec)
我们可以看到,`t1`表中符合`t1.m1 > 1`的记录有两条。
上一步骤中从驱动表每获取到一条记录,都需要到
t2表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。因为是根据t1表中的记录去找t2表中的记录,所以t2表也可以被称之为被驱动表。上一步骤从驱动表中得到了2条记录,也就意味着需要查询2次t2表。此时涉及两个表的列的过滤条件t1.m1 = t2.m2就派上用场了:对于从
t1表种查询得到的第一条记录,也就是当t1.m1 = 2, t1.n1 = 'b'时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 2,所以此时t2表相当于有了t2.m2 = 2、t2.n2 < 'd'这两个过滤条件,然后到t2表中执行单表查询,将得到的记录和从t1表中查询得到的第一条记录相组合得到下边的结果:+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b |+------+------+------+------+
* 对于从`t1`表种查询得到的第二条记录,也就是当`t1.m1 = 3, t1.n1 = 'c'`时,过滤条件`t1.m1 = t2.m2`就相当于`t2.m2 = 3`,所以此时`t2`表相当于有了`t2.m2 = 3`、`t2.n2 < 'd'`这两个过滤条件,然后到`t2`表中执行单表查询,将得到的记录和从`t1`表中查询得到的第二条记录相组合得到下边的结果:+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 3 | c | 3 | c |+------+------+------+------+所以整个连接查询的执行最后得到的结果集就是这样:+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c |+------+------+------+------+2 rows in set (0.00 sec)
从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次t1表,2次t2表。当然这是在特定的过滤条件下的结果,如果我们把t1.m1 > 1这个条件去掉,那么从t1表中查出的记录就有3条,就需要查询3次t2表了。也就是说在两表连接查询中,驱动表只需要查询一次,被驱动表可能会被查询多次。
内连接和外连接
了解了连接查询的执行过程之后,视角再回到我们的student_info表和student_score表。现在我们想在一个查询语句中既查询到学生的基本信息,也查询到学生的成绩信息,就需要进行两表连接了。连接过程就是从student_info表中取出记录,在student_score表中查找number值相同的成绩记录,所以过滤条件就是student_info.number = student_score.number,整个查询语句就是这样:
mysql> SELECT student_info.number, name, major, subject, score FROM student_info, student_score WHERE student_info.number = student_score.number;+----------+-----------+--------------------------+-----------------------------+-------+| number | name | major | subject | score |+----------+-----------+--------------------------+-----------------------------+-------+| 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 || 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 || 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 || 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 || 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 || 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 || 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 |+----------+-----------+--------------------------+-----------------------------+-------+8 rows in set (0.00 sec)mysql>
小贴士: student_info表和student_score表都有number列,不过我们在上述查询语句的查询列表中只放置了student_info表的number列,这是因为我们的过滤条件是student_info.number = student_score.number,从两个表中取出的记录的number列都相同,所以只需要放置一个表中的number列到查询列表即可,也就是说我们把student_score.number放到查询列表处也是可以滴~
从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可是有个问题,范剑和朱逸群同学,也就是学号为20180105和20180106的同学因为某些原因没有参加考试,所以在studnet_score表中没有对应的成绩记录。那如果老师想查看所有同学的考试成绩,即使是缺考的同学也应该展示出来,但是到目前为止我们介绍的连接查询是无法完成这样的需求的。我们稍微思考一下这个需求,其本质是想:驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。为了解决这个问题,就有了内连接和外连接的概念:
对于
内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。对于
外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。在
MySQL中,根据选取驱动表的不同,外连接仍然可以细分为2种:左外连接
选取左侧的表为驱动表。
右外连接
选取右侧的表为驱动表。
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,这咋办,有点儿愁啊。。。噫,把过滤条件分为两种不就解决了这个问题了么,所以放在不同地方的过滤条件是有不同语义的:
WHERE子句中的过滤条件WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。ON子句中的过滤条件对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配
ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。需要注意的是,这个
ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把ON子句放到内连接中,MySQL会把它和WHERE子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到WHERE子句中,把涉及两表的过滤条件都放到ON子句中,我们也一般把放到ON子句中的过滤条件也称之为连接条件。
小贴士: 左外连接和右外连接简称左连接和右连接,所以下边提到的左外连接和右外连接中的`外`字都用括号扩起来,以表示这个字儿可有可无。
左(外)连接的语法
左(外)连接的语法还是挺简单的,比如我们要把t1表和t2表进行左外连接查询可以这么写:
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
其中中括号里的OUTER单词是可以省略的。对于LEFT JOIN类型的连接来说,我们把放在左边的表称之为外表或者驱动表,右边的表称之为内表或者被驱动表。所以上述例子中t1就是外表或者驱动表,t2就是内表或者被驱动表。需要注意的是,对于左(外)连接和右(外)连接来说,必须使用ON子句来指出连接条件。了解了左(外)连接的基本语法之后,再次回到我们上边那个现实问题中来,看看怎样写查询语句才能把所有的学生的成绩信息都查询出来,即使是缺考的考生也应该被放到结果集中:
mysql> SELECT student_info.number, name, major, subject, score FROM student_info LEFT JOIN student_score ON student_info.number = student_score.number;+----------+-----------+--------------------------+-----------------------------+-------+| number | name | major | subject | score |+----------+-----------+--------------------------+-----------------------------+-------+| 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 || 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 || 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 || 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 || 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 || 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 || 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 || 20180105 | 范剑 | 飞行器设计 | NULL | NULL || 20180106 | 朱逸群 | 电子信息 | NULL | NULL |+----------+-----------+--------------------------+-----------------------------+-------+10 rows in set (0.00 sec)mysql>
从结果集中可以看出来,虽然范剑和朱逸群并没有对应的成绩记录,但是由于采用的是连接类型为左(外)连接,所以仍然把它放到了结果集中,只不过在对应的成绩记录的各列使用NULL值填充而已。
右(外)连接的语法
右(外)连接和左(外)连接的原理是一样一样的,语法也只是把LEFT换成RIGHT而已:
SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
只不过驱动表是右边的表,被驱动表是左边的表,具体就不唠叨了。
内连接的语法
内连接和外连接的根本区别就是在驱动表中的记录不符合ON子句中的连接条件时不会把该记录加入到最后的结果集,我们最开始唠叨的那些连接查询的类型都是内连接。不过之前仅仅提到了一种最简单的内连接语法,就是直接把需要连接的多个表都放到FROM子句后边。其实针对内连接,MySQL提供了好多不同的语法,我们以t1和t2表为例瞅瞅:
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];
也就是说在MySQL中,下边这几种内连接的写法都是等价的:
SELECT * FROM t1 JOIN t2;
SELECT * FROM t1 INNER JOIN t2;
SELECT * FROM t1 CROSS JOIN t2;
上边的这些写法和直接把需要连接的表名放到FROM语句之后,用逗号,分隔开的写法是等价的:
SELECT * FROM t1, t2;
现在我们虽然介绍了很多种内连接的书写方式,不过熟悉一种就好了,这里我们推荐INNER JOIN的形式书写内连接(因为INNER JOIN语义很明确嘛,可以和LEFT JOIN和RIGHT JOIN很轻松的区分开)。这里需要注意的是,由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。
我们前边说过,连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合ON子句或WHERE子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合ON子句连接条件的记录也会被加入结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
小结
上边说了很多,给大家的感觉不是很直观,我们直接把表t1和t2的三种连接方式写在一起,这样大家理解起来就很easy了:
mysql> SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c |+------+------+------+------+2 rows in set (0.00 sec)mysql> SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c || 1 | a | NULL | NULL |+------+------+------+------+3 rows in set (0.00 sec)mysql> SELECT * FROM t1 RIGHT JOIN t2 ON t1.m1 = t2.m2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c || NULL | NULL | 4 | d |+------+------+------+------+3 rows in set (0.00 sec)
连接查询产生的结果集就好像把散布到两个表中的信息被重新粘贴到了一个表,这个粘贴后的结果集可以方便我们分析数据,就不用老是两个表对照的看了。
多表连接
上边说过,如果我们乐意的话可以连接任意数量的表,我们再来创建一个简单的t3表:
mysql> CREATE TABLE t3 (m3 int, n3 char(1));ERROR 1050 (42S01): Table 't3' already existsmysql> INSERT INTO t3 VALUES(3, 'c'), (4, 'd'), (5, 'e');Query OK, 3 rows affected (0.01 sec)Records: 3 Duplicates: 0 Warnings: 0mysql>
与t1和t2表的结构一样,也是一个INT列,一个CHAR(1)列,现在我们看一下把这3个表连起来的样子:
mysql> SELECT * FROM t1 INNER JOIN t2 INNER JOIN t3 WHERE t1.m1 = t2.m2 AND t1.m1 = t3.m3;+------+------+------+------+------+------+| m1 | n1 | m2 | n2 | m3 | n3 |+------+------+------+------+------+------+| 3 | c | 3 | c | 3 | c |+------+------+------+------+------+------+1 row in set (0.00 sec)mysql>
其实上边的查询语句也可以写成这样,用哪个取决于你的心情:
SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2 INNER JOIN t3 ON t1.m1 = t3.m3;
这个查询的执行过程用伪代码表示一下就是这样:
for each row in t1 {for each row in t2 which satisfies t1.m1 = t2.m2 {for each row in t3 which satisfies t1.m1 = t3.m3 {send to client;}}}
其实不管是多少个表的连接,本质上就是各个表的记录在符合过滤条件下的自由组合。
表的别名
我们前边曾经为列命名过别名,比如说这样:
mysql> SELECT number AS xuehao FROM student_info;+----------+| xuehao |+----------+| 20180104 || 20180102 || 20180101 || 20180103 || 20180105 || 20180106 |+----------+6 rows in set (0.00 sec)mysql>
我们可以把列的别名用在ORDER BY、GROUP BY等子句上,比如这样:
mysql> SELECT number AS xuehao FROM student_info ORDER BY xuehao DESC;+----------+| xuehao |+----------+| 20180106 || 20180105 || 20180104 || 20180103 || 20180102 || 20180101 |+----------+6 rows in set (0.00 sec)mysql>
与列的别名类似,我们也可以为表来定义别名,格式与定义列的别名一致,都是用空白字符或者AS隔开,这个在表名特别长的情况下可以让语句表达更清晰一些,比如这样:
mysql> SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number;+----------+-----------+--------------------------+-----------------------------+-------+| number | name | major | subject | score |+----------+-----------+--------------------------+-----------------------------+-------+| 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 || 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 || 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 || 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 || 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 || 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 || 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 |+----------+-----------+--------------------------+-----------------------------+-------+8 rows in set (0.00 sec)mysql>
这个例子中,我们在FROM子句中给student_info定义了一个别名s1,student_score定义了一个别名s2,那么在整个查询语句的其他地方就可以引用这个别名来替代该表本身的名字了。
自连接
我们上边说的都是多个不同的表之间的连接,其实同一个表也可以进行连接。比方说我们可以对两个t1表来生成笛卡尔积,就像这样:
mysql> SELECT * FROM t1, t1;ERROR 1066 (42000): Not unique table/alias: 't1'mysql>
咦,报了个错,这是因为设计MySQL的大叔不允许FROM子句中出现相同的表名。我们这里需要的是两张一模一样的t1表进行连接,为了把两个一样的表区分一下,需要为表定义别名。比如这样:
mysql> SELECT * FROM t1 AS table1, t1 AS table2;+------+------+------+------+| m1 | n1 | m1 | n1 |+------+------+------+------+| 1 | a | 1 | a || 2 | b | 1 | a || 3 | c | 1 | a || 1 | a | 2 | b || 2 | b | 2 | b || 3 | c | 2 | b || 1 | a | 3 | c || 2 | b | 3 | c || 3 | c | 3 | c |+------+------+------+------+9 rows in set (0.00 sec)mysql>
这里相当于我们为t1表定义了两个副本,一个是table1,另一个是table2,这里的连接过程就不赘述了,大家把它们认为是不同的表就好了。由于被连接的表其实是源自同一个表,所以这种连接也称为自连接。我们看一下这个自连接的现实意义,比方说我们想查看与'史珍香'相同专业的学生有哪些,可以这么写:
mysql> SELECT s2.number, s2.name, s2.major FROM student_info AS s1 INNER JOIN student_info AS s2 WHERE s1.major = s2.major AND s1.name = '史珍香' ;+----------+-----------+--------------+| number | name | major |+----------+-----------+--------------+| 20180103 | 范统 | 软件工程 || 20180104 | 史珍香 | 软件工程 |+----------+-----------+--------------+2 rows in set (0.01 sec)mysql>
s1、s2都可以看作是student_info表的一份副本,我们可以这样理解这个查询:
根据
s1.name = '史珍香'搜索条件过滤s1表,可以得到该同学的基本信息:+----------+-----------+------+--------------------+-----------------+--------------+-----------------+| number | name | sex | id_number | department | major | enrollment_time |+----------+-----------+------+--------------------+-----------------+--------------+-----------------+| 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 |+----------+-----------+------+--------------------+-----------------+--------------+-----------------+
因为通过查询
s1表,得到了'史珍香'所在的专业其实是'软件工程',接下来就应该查询s2表了,查询s2表的时候的过滤条件s1.major = s2.major就相当于s2.major = '软件工程',于是查询到2条记录:+----------+-----------+------+--------------------+-----------------+--------------+-----------------+| number | name | sex | id_number | department | major | enrollment_time |+----------+-----------+------+--------------------+-----------------+--------------+-----------------+| 20180103 | 范统 | 男 | 17156319980116959X | 计算机学院 | 软件工程 | 2018-09-01 || 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 |+----------+-----------+------+--------------------+-----------------+--------------+-----------------+
而我们只需要`s2`表的`number`、`name`、`major`这3个列的数据,所以最终的结果就长这样:+----------+-----------+--------------+| number | name | major |+----------+-----------+--------------+| 20180103 | 范统 | 软件工程 || 20180104 | 史珍香 | 软件工程 |+----------+-----------+--------------+
连接查询与子查询的转换
有的查询需求既可以使用连接查询解决,也可以使用子查询解决,比如
SELECT * FROM student_score WHERE number IN (SELECT number FROM student_info WHERE major = '计算机科学与工程');
这个子查询就可以被替换:
SELECT s2.* FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number AND s1.major = '计算机科学与工程';
大家在实际使用时可以按照自己的习惯来书写查询语句。
小贴士: MySQL服务器在内部可能将子查询转换为连接查询来处理,当然也可能用别的方式来处理,不过对于我们刚入门的小白来说,这些都不重要,知道这个语句会把哪些信息查出来就好了!
