提示:本节课最终代码为:feature/s25。
在 Go 应用上线之前,我们需要知道 API 接口的性能,以便知道 API 服务器所能承载的最大请求量、性能瓶颈,再根据业务的需求量来对 API 进行性能调优或者扩缩容。通过这些可以使 API 稳定地对外提供服务,并且请求在合理的时间内返回。
API 性能测试指标
API 性能测试,大的方面包括 API 框架的性能和指定 API 的性能,因为指定 API 的性能跟该 API 具体的实现有关,比如有无数据库连接,有无复杂的逻辑处理等,脱离了具体实现来探讨单个 API 的性能是毫无意义的,所以本小节只探讨 API 框架的性能。
衡量 API 性能的指标主要有 3 个:
- 并发数(Concurrent)
并发数是指某个时间范围内,同时正在使用系统的用户个数。广义上的并发数是指同时使用系统的用户个数,这些用户可能调用不同的 API。严格意义上的并发数是指同时请求同一个 API 的用户个数。本小节所讨论的并发数是严格意义上的并发数。
- 每秒查询数(QPS)
每秒查询数 QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。QPS = 并发数 / 平均请求响应时间。
- 请求响应时间(TTLB)
请求响应时间指的是从客户端发出请求到得到响应的整个时间。这个过程从客户端发起的一个请求开始,到客户端收到服务器端的响应结束。在一些工具中,请求响应时间通常会被称为 TTLB(Time to last byte,意思是从发送一个请求开始,到客户端收到最后一个字节的响应为止所消费的时间)。请求响应时间的单位一般为”秒”或“毫秒”。
衡量 API 性能的最主要指标是 QPS,但是在说明 QPS 时,需要指明是多少并发数下的 QPS,否则毫无意义,因为不同并发数下的 QPS 是不同的。比如单用户 100 QPS 和 100 用户 100 QPS 是两个不同的概念,前者说明 API 可以在一秒内串行执行 100 个请求,而后者说明在并发数为 100 的情况下,API 可以在一秒内处理 100 个请求。当 QPS 相同时,并发数越大,说明 API 性能越好,并发处理能力越强。
在并发数设置过大时,API 同时要处理很多请求,会频繁切换进程,而真正用于处理请求的时间变少,使得 QPS 反而会降低。并发数设置过大时,请求响应时间也会变大。API 会有一个合适的并发数,在该并发数下,API 的 QPS 可以达到最大,但该并发数不一定是最佳并发数,还要参考该并发数下的平均请求响应时间。
API 性能测试方法
Linux 下有很多 Web 性能测试工具,常用的有 Jmeter、AB、Webbench 和 Wrk。每个工具都有自己的特点,本小节用 Wrk 来对 API 进行性能测试。Wrk 非常简单,安装方便,测试结果也相对专业些,并且可以支持 Lua 脚本来创建更复杂的测试场景。
Wrk 安装
安装命令如下(需要切换到 root 用户):
$ git clone https://github.com/wg/wrk$ cd wrk/$ make$ sudo cp ./wrk /usr/bin
Wrk 使用简介
Wrk 使用方法
Wrk 使用起来不复杂,执行 wrk --help 可以看到 wrk 的所有运行参数:
$ wrk --helpUsage: wrk <options> <url>Options:-c, --connections <N> Connections to keep open-d, --duration <T> Duration of test-t, --threads <N> Number of threads to use-s, --script <S> Load Lua script file-H, --header <H> Add header to request--latency Print latency statistics--timeout <T> Socket/request timeout-v, --version Print version detailsNumeric arguments may include a SI unit (1k, 1M, 1G)Time arguments may include a time unit (2s, 2m, 2h)
常用的参数为:
-t: 线程数(线程数不要太多,是核数的 2 到 4 倍即可,多了反而会因为线程切换过多造成效率降低);-c: 并发数;-d: 测试的持续时间,默认为 10s;-T: 请求超时时间;-H: 指定请求的 HTTP Header,有些 API 需要传入一些 Header,可通过 Wrk 的-H参数来传入;--latency: 打印响应时间分布;-s: 指定 Lua 脚本,Lua 脚本可以实现更复杂的请求。
Wrk 结果解析
一个简单的测试如下:
- 启动
miniblog服务。
$ make build$ _output/miniblog -c configs/miniblog.yaml &>/dev/null # 需要将日志输出定位到 /dev/null,打印到标准输出会严重影响接口性能
打开一个新的 Linux 终端执行 wrk 进行 API 接口压力测试,命令如下:
$ wrk -t32 -c1000 -d30s -T30s --latency http://127.0.0.1:8080/healthzRunning 30s test @ http://127.0.0.1:8080/healthz32 threads and 1000 connectionsThread Stats Avg Stdev Max +/- StdevLatency 12.49ms 12.47ms 180.14ms 88.44%Req/Sec 2.89k 417.30 13.21k 88.66%Latency Distribution50% 13.14ms75% 20.27ms90% 26.40ms99% 47.91ms2766240 requests in 30.10s, 1.20GB readSocket errors: connect 3, read 0, write 0, timeout 0Requests/sec: 91904.09Transfer/sec: 40.93MB
测试输出解读如下。
32 threads and 1000 connections: 用 32 个线程模拟 1000 个连接,分别对应-t和-c参数。Thread Stats: 线程统计。Latency: 响应时间,有平均值、标准偏差、最大值、正负一个标准差占比;Req/Sec: 每个线程每秒完成的请求数, 同样有平均值、标准偏差、最大值、正负一个标准差占比。
Latency Distribution: 响应时间分布。50%: 50% 的响应时间为:13.14ms;75%: 75% 的响应时间为:20.27ms;90%: 90% 的响应时间为:26.40ms;99%: 99% 的响应时间为:47.91ms。
2766240 requests in 30.10s, 1.20GB read: 30s 完成的总请求数(2766240)和数据读取量(1.20GB);Socket errors: connect 3, read 0, write 0, timeout 0: 错误统计;Requests/sec: QPS;Transfer/sec: TPS。
miniblog 接口性能测试
因为服务器的配置,例如:CPU、内存等都会影响服务的性能。对于 API 接口,如果接口没有对磁盘、网络的资源消耗,可以不考虑磁盘和网络对接口带来的影响。通常,CPU 和 内存都会影响接口的性能。所以,在接口性能测试前,需要先明确机器的配置。本课程的机器配置为:16 核 32G。
miniblog 有很多接口,我们可以根据需要选择要测试性能的 API 接口。一般来说读类接口,尤其是 List 类接口,调用频繁、返回的数据量大,对用户体验影响较大。所以这里我们选择测试 GET /v1/users 接口的性能。
这里,我们基于 feature/s24 的代码来进行性能测试。为了能够在性能测试时同步进行性能分析,我们需要引用 github.com/gin-contrib/pprof 包,来注册 pprof 相关路由,访问这些路由可以提供 profile 性能数据。
在 internal/miniblog/router.go 文件中添加以下 3 行代码:
$ git diff internal/miniblog/router.godiff --git a/internal/miniblog/router.go b/internal/miniblog/router.goindex 57e62ec..2afb287 100644--- a/internal/miniblog/router.go+++ b/internal/miniblog/router.go@@ -6,6 +6,7 @@package miniblogimport (+ "github.com/gin-contrib/pprof""github.com/gin-gonic/gin""github.com/marmotedu/miniblog/internal/miniblog/controller/v1/post"@@ -32,6 +33,9 @@ func installRouters(g *gin.Engine) error {core.WriteResponse(c, nil, map[string]string{"status": "ok"})})+ // 注册 pprof 路由+ pprof.Register(g)+authz, err := auth.NewAuthz(store.S.DB())if err != nil {return err
为了能够自动化地对 API 接口进行测试,我还编写了 scripts/wrktest.sh 脚本,用来进行自动化测试。wrktest.sh 脚本比较复杂,这里不做介绍,如果你感兴趣,可以阅读此脚本进行学习。
因为性能测试会产生大量的日志,如果将日志写入日志文件,可能会导致服务器磁盘空间被占满,导致性能测试失败,所以需要先修改配置文件 configs/miniblog.yaml,将日志只输出到标准输出:
# 日志配置log:disable-caller: false # 是否开启 caller,如果开启会在日志中显示调用日志所在的文件和行号disable-stacktrace: false # 是否禁止在 panic 及以上级别打印堆栈信息level: debug # 指定日志级别,可选值:debug, info, warn, error, dpanic, panic, fatalformat: console # 指定日志显示格式,可选值:console, jsonoutput-paths: [stdout] # 指定日志输出位置,多个输出,用 `逗号 + 空格` 分开。stdout:标准输出,
修改后的完整代码见:feature/s24-1。
在测试前,需要修改 Linux 系统支持的最大打开文件数,否则可能会遇到 unable to create thread 6: Too many open files 错误。以 root 权限编辑 /etc/security/limits.conf 文件,在文件最后追加以下 4 行,即可修改最大打开的文件数:
* soft nofile 204800* hard nofile 204800* soft nproc 204800* hard nproc 204800
另外还需要确保 Linux 系统安装了 gnuplot 绘图工具:
$ sudo yum -y install gnuplot
最后,编译并运行 miniblog 服务:
$ make build$ _output/miniblog -c configs/miniblog.yaml &>/dev/null
打开一个新的 Linux 终端,并执行 wrk 测试 API 接口的性能,命令如下:
$ export TOKEN=`curl -s -XPOST -H"Content-Type: application/json" -d'{"username":"root","password":"miniblog1234"}' http://127.0.0.1:8080/login | jq -r .token`$ ./scripts/wrktest.sh http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 200 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 500 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 1000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 3000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 5000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 10000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 15000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 20000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 25000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 50000 http://127.0.0.1:8080/v1/usersNow plot according to /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog.datQPS graphic file is: /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog_qps_ttlb.pngSuccess rate graphic file is: /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog_successrate.png
wrktest.sh 测试脚本会依次测试并发数分别为 200、500、1000、3000、5000、10000、15000、20000、25000、50000 时的接口性能,并根据数据绘制性能图。wrktest.sh 执行完成后会输出以下 3 个文件:
_output/wrk/miniblog.dat:性能测试数据,具体内容如下:
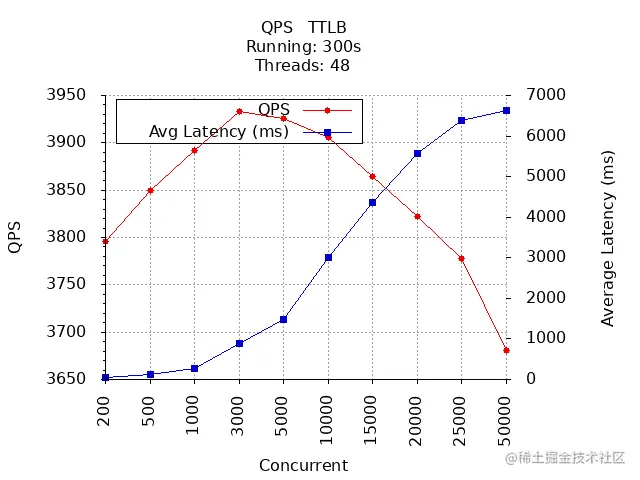
# 并发数 QPS 延时 成功率200 3795.29 50.59 100.00500 3849.26 127.63 100.001000 3892.16 262.09 100.003000 3932.92 881.70 100.005000 3925.93 1480 100.0010000 3905.28 3000 99.9715000 3864.01 4370 99.8120000 3821.99 5560 99.3625000 3778.33 6380 98.7450000 3680.78 6630 96.26
_output/wrk/miniblog_qps_ttlb.png:QPS & 平均响应时间图;_output/wrk/miniblog_successrate.png:成功率图。
QPS & 平均响应时间:
成功率:
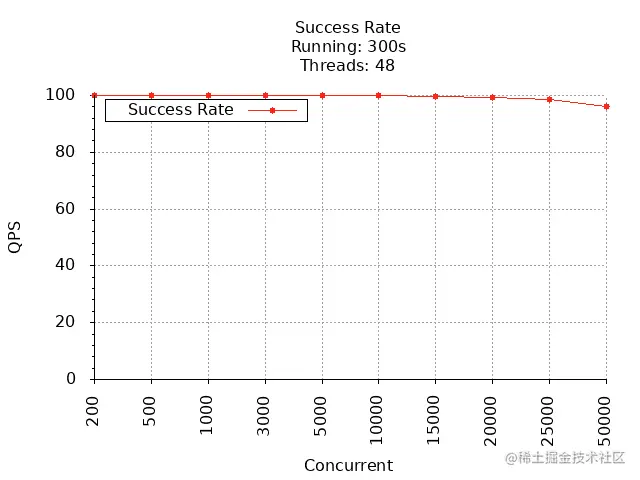
通过上面 2 张图可以看到,GET /v1/users 接口在并发数为 3000 时,QPS 最大,为 3934,平均响应时间为 881 ms,在并发数达到 10000 时,成功率开始下降。
GET /v1/users 接口性能分析
提示:API 接口性能分析涉及的范围比较广,本课程不是专门教你如何进行详细的性能分析的教程,这里仅仅展示性能分析的步骤和基本思路。
在执行性能测试的过程中,运行 go tool pprof ``http://127.0.0.1:8080/debug/pprof/profile,采集 30s 的性能数据并查看耗时比较久的 20 个函数:
$ go tool pprof http://127.0.0.1:8080/debug/pprof/profileFetching profile over HTTP from http://127.0.0.1:8080/debug/pprof/profileSaved profile in /home/colin/pprof/pprof.miniblog.samples.cpu.001.pb.gzFile: miniblogType: cpuTime: Jan 31, 2023 at 11:01am (CST)Duration: 30.16s, Total samples = 201.83s (669.23%)Entering interactive mode (type "help" for commands, "o" for options)(pprof) top20Showing nodes accounting for 105.81s, 52.43% of 201.83s totalDropped 1121 nodes (cum <= 1.01s)Showing top 20 nodes out of 266flat flat% sum% cum cum%53.79s 26.65% 26.65% 53.79s 26.65% runtime/internal/syscall.Syscall66.86s 3.40% 30.05% 31.90s 15.81% runtime.mallocgc5.41s 2.68% 32.73% 6.39s 3.17% runtime.heapBitsSetType5.20s 2.58% 35.31% 14.35s 7.11% runtime.pcvalue5.13s 2.54% 37.85% 6.50s 3.22% runtime.step3.10s 1.54% 39.38% 16.07s 7.96% runtime.gentraceback2.92s 1.45% 40.83% 2.92s 1.45% runtime.nextFreeFast (inline)2.89s 1.43% 42.26% 8.80s 4.36% runtime.scanobject2.66s 1.32% 43.58% 2.66s 1.32% runtime.epollwait2.59s 1.28% 44.86% 3.53s 1.75% runtime.findObject2.10s 1.04% 45.90% 2.10s 1.04% runtime.memmove1.94s 0.96% 46.87% 1.97s 0.98% runtime.pageIndexOf (inline)1.85s 0.92% 47.78% 1.85s 0.92% runtime.(*moduledata).textAddr1.76s 0.87% 48.65% 1.76s 0.87% runtime.memclrNoHeapPointers1.37s 0.68% 49.33% 1.37s 0.68% runtime.readvarint (inline)1.32s 0.65% 49.99% 1.38s 0.68% runtime.(*itabTableType).find1.31s 0.65% 50.64% 1.44s 0.71% runtime.casgstatus1.27s 0.63% 51.27% 1.27s 0.63% runtime.markBits.isMarked (inline)1.20s 0.59% 51.86% 1.31s 0.65% runtime.findfunc1.14s 0.56% 52.43% 1.14s 0.56% runtime.futex(pprof)
在 go tool pprof 文章中,我们知道,在默认情况下,top 命令输出的列表中只包含本地取样计数最大的前十个函数,统计的是这些函数本身运行的执行时间,实际上我们还需要知道,该函数中有没有调用其它耗时的函数以及执行其它函数所耗费的时间,这种情况下我们需要按累积取样计数来排序,这在 pprof 中需要加上 -cum 参数:
(pprof) top100 -cumShowing nodes accounting for 98.85s, 48.98% of 201.83s totalDropped 1121 nodes (cum <= 1.01s)Showing top 100 nodes out of 266flat flat% sum% cum cum%0.03s 0.015% 0.015% 183.34s 90.84% net/http.(*conn).serve0.03s 0.015% 0.03% 176.67s 87.53% net/http.serverHandler.ServeHTTP0.01s 0.005% 0.035% 176.64s 87.52% github.com/gin-gonic/gin.(*Engine).ServeHTTP0.04s 0.02% 0.055% 176.56s 87.48% github.com/gin-gonic/gin.(*Engine).handleHTTPRequest0.15s 0.074% 0.13% 176.50s 87.45% github.com/gin-gonic/gin.(*Context).Next (inline)0.02s 0.0099% 0.14% 176.45s 87.43% github.com/gin-gonic/gin.CustomRecoveryWithWriter.func10 0% 0.14% 176.43s 87.42% github.com/marmotedu/miniblog/internal/pkg/middleware.NoCache0 0% 0.14% 176.02s 87.21% github.com/marmotedu/miniblog/internal/pkg/middleware.Cors0.01s 0.005% 0.14% 175.87s 87.14% github.com/marmotedu/miniblog/internal/pkg/middleware.RequestID.func10 0% 0.14% 175.27s 86.84% github.com/marmotedu/miniblog/internal/pkg/middleware.Authn.func10.03s 0.015% 0.16% 163.33s 80.92% github.com/marmotedu/miniblog/internal/miniblog/controller/v1/user.(*UserController).List0.36s 0.18% 0.34% 157.70s 78.14% github.com/marmotedu/miniblog/internal/miniblog/biz/user.(*userBiz).List0.68s 0.34% 0.67% 143.02s 70.86% gorm.io/gorm.(*processor).Execute0.11s 0.055% 0.73% 132.82s 65.81% github.com/marmotedu/miniblog/internal/miniblog/store.(*posts).List0.27s 0.13% 0.86% 107.63s 53.33% gorm.io/gorm/callbacks.Query0.02s 0.0099% 0.87% 79.31s 39.30% gorm.io/gorm.(*DB).Find0.19s 0.094% 0.97% 65.69s 32.55% gorm.io/gorm.(*DB).Count0.07s 0.035% 1.00% 64.27s 31.84% database/sql.(*DB).QueryContext0.13s 0.064% 1.07% 64.08s 31.75% database/sql.(*DB).query0.23s 0.11% 1.18% 56.36s 27.92% syscall.Syscall......
为了能够查看到所有函数的耗时排名,你需要列出更多的函数,上面我列出了 TOP 100 的函数。
如果你能读懂 top 命令的输出,你应该会从以下几行数据中发现可能存在的性能瓶颈:
(pprof) top100 -cumShowing nodes accounting for 98.85s, 48.98% of 201.83s totalDropped 1121 nodes (cum <= 1.01s)Showing top 100 nodes out of 266flat flat% sum% cum cum%0.03s 0.015% 0.015% 183.34s 90.84% net/http.(*conn).serve0.03s 0.015% 0.03% 176.67s 87.53% net/http.serverHandler.ServeHTTP0.01s 0.005% 0.035% 176.64s 87.52% github.com/gin-gonic/gin.(*Engine).ServeHTTP0.04s 0.02% 0.055% 176.56s 87.48% github.com/gin-gonic/gin.(*Engine).handleHTTPRequest0.15s 0.074% 0.13% 176.50s 87.45% github.com/gin-gonic/gin.(*Context).Next (inline)0.02s 0.0099% 0.14% 176.45s 87.43% github.com/gin-gonic/gin.CustomRecoveryWithWriter.func10 0% 0.14% 176.43s 87.42% github.com/marmotedu/miniblog/internal/pkg/middleware.NoCache0 0% 0.14% 176.02s 87.21% github.com/marmotedu/miniblog/internal/pkg/middleware.Cors0.01s 0.005% 0.14% 175.87s 87.14% github.com/marmotedu/miniblog/internal/pkg/middleware.RequestID.func10 0% 0.14% 175.27s 86.84% github.com/marmotedu/miniblog/internal/pkg/middleware.Authn.func10.03s 0.015% 0.16% 163.33s 80.92% github.com/marmotedu/miniblog/internal/miniblog/controller/v1/user.(*UserController).List0.36s 0.18% 0.34% 157.70s 78.14% github.com/marmotedu/miniblog/internal/miniblog/biz/user.(*userBiz).List0.68s 0.34% 0.67% 143.02s 70.86% gorm.io/gorm.(*processor).Execute0.11s 0.055% 0.73% 132.82s 65.81% github.com/marmotedu/miniblog/internal/miniblog/store.(*posts).List0.27s 0.13% 0.86% 107.63s 53.33% gorm.io/gorm/callbacks.Query0.02s 0.0099% 0.87% 79.31s 39.30% gorm.io/gorm.(*DB).Find0.19s 0.094% 0.97% 65.69s 32.55% gorm.io/gorm.(*DB).Count0.07s 0.035% 1.00% 64.27s 31.84% database/sql.(*DB).QueryContext0.13s 0.064% 1.07% 64.08s 31.75% database/sql.(*DB).query0.23s 0.11% 1.18% 56.36s 27.92% syscall.Syscall......
首先 github.com/marmotedu/miniblog/internal/pkg/middleware.``xxx 这类函数耗时较久,通过这类函数的名字,我们发现都是我们所需要的中间件耗时。此类功能是必须的,暂时无需优化(当然,你也可以进一步优化这些中间件的性能)。
根据 flat% 和 sum% 的值,并结合函数代码,我们可以得出以下结论:
user.(*UserController).List函数自身耗时很小,耗时基本都是user.(*userBiz).List函数的耗时;user.(*userBiz).List函数自身耗时很小,耗时基本都是调用store.(*posts).List函数的耗时。user.(*userBiz).List串行调用store.(*posts).List函数。这时,我们应该能够发现一个优化点:可以将串行调用改成并行调用,以节省调用时间。
可以看到,我们在做性能分析时,需要结合性能数据、代码实现、业务逻辑进行综合判断,以确定影响性能的代码,并优化。
GET /v1/users 接口性能优化
通过上面的性能分析,我们可以考虑将 user.(*userBiz).List 函数的实现方式由同步查询改成并发查询,优化后的代码为:user.go#L129。接下来,我们重新编译 miniblog、运行 miniblog 服务,并再次测试 GET /v1/users 接口的性能。
编译并运行 miniblog 服务:
$ make build$ _output/miniblog -c configs/miniblog.yaml &>/dev/null
打开一个新的 Linux 终端,并执行 wrk 测试 API 接口的性能,命令如下:
$ export TOKEN=`curl -s -XPOST -H"Content-Type: application/json" -d'{"username":"root","password":"miniblog1234"}' http://127.0.0.1:8080/login | jq -r .token`$ ./scripts/wrktest.sh http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 200 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 500 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 1000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 3000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 5000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 10000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 15000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 20000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 25000 http://127.0.0.1:8080/v1/usersRunning wrk command: wrk -t48 -d300s -T30s --latency -H"Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJYLVVzZXJuYW1lIjoicm9vdCIsImV4cCI6MjAzNTEzMzgxMSwiaWF0IjoxNjc1MTMzODExLCJuYmYiOjE2NzUxMzM4MTF9.fBxnmuCcRgq4ZvihKdM8UxsOV7UDGR-EcTpU8EhHaBE" -c 50000 http://127.0.0.1:8080/v1/usersNow plot according to /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog.datQPS graphic file is: /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog_qps_ttlb.pngSuccess rate graphic file is: /home/colin/workspace/golang/src/github.com/marmotedu/miniblog/_output/wrk/miniblog_successrate.png
_output/wrk/miniblog.dat 性能测试数据内容如下:
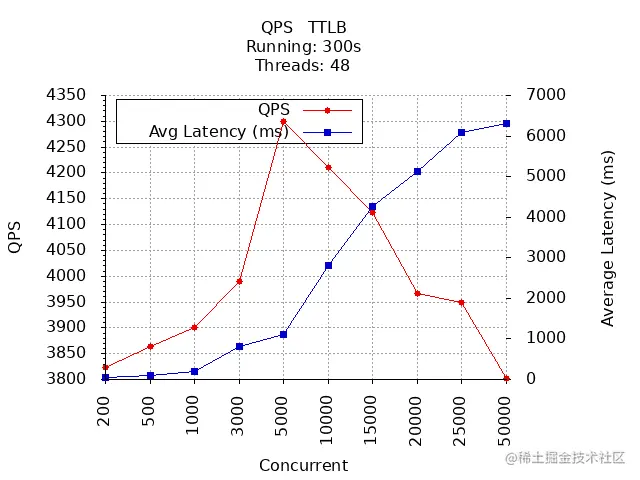
200 3822.96 45.97 100.00500 3864.57 100.19 100.001000 3900.94 201.02 100.003000 3989.79 810 100.005000 4300.35 1103 100.0010000 4210.48 2800 99.9915000 4123.42 4260 99.9520000 3965.69 5130 99.4225000 3948.72 6100 98.8350000 3801.27 6320 96.40
QPS & 平均响应时间:
成功率:
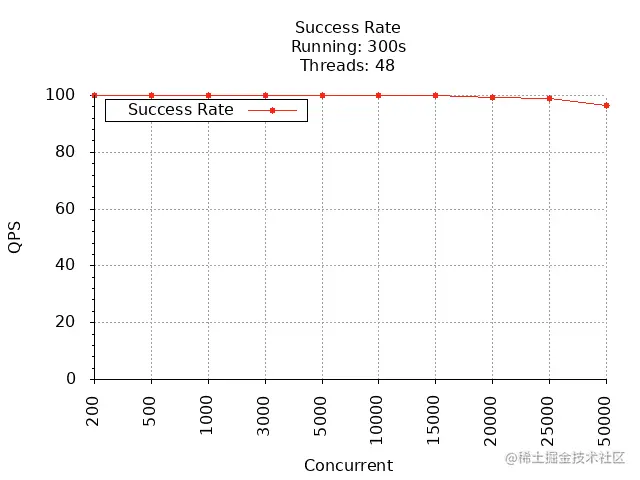
通过上面 2 张图可以看到,GET /v1/users 接口在并发数为 5000 时,QPS 最大,为 4300,平均响应时间为 1103 ms,在并发数达到 10000 时,成功率开始下降。
这里我们使用 wrktest.sh 脚本对优化前和优化后性能进行对比。
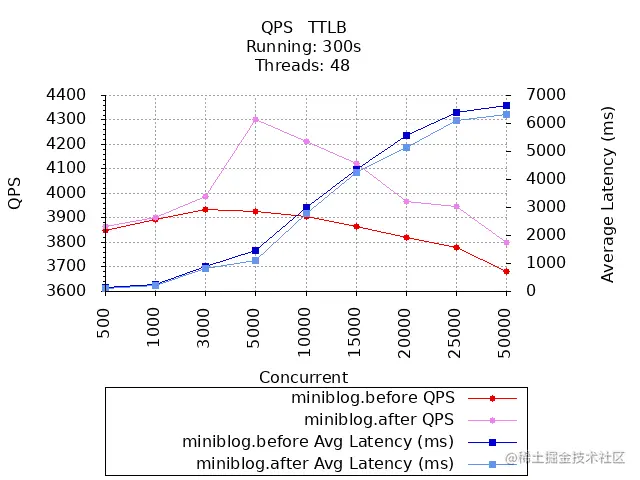
QPS & 平均响应时间对比:
成功率对比:
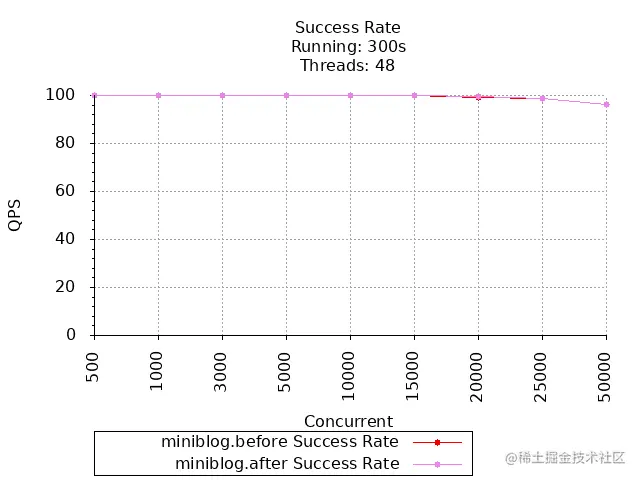
通过对比,可以看到,优化后 GET /v1/users 接口性能有了提升:
- 最大 QPS 相较于优化前提升了 9%;
- 最大并发数在 5000 时,成功率开始下降。支持的并发数也有所提升;
- 接口延时相较于优化前,也有降低。
最后,根据以上优化思路和步骤,你可以继续优化 GET /v1/users 接口的性能,直到自己满意为止。
小结
本节课介绍了如何进行 API 接口的性能测试,并给出了 miniblog 接口的性能数据。本节课介绍的是框架的性能,具体到某个接口的性能因为影响因素比较多,需要你自己去优化,这里给出 HTTP 接口性能要求,供读者在优化时参考:
| 指标名称 | 要求 | 优先级 |
|---|---|---|
| 响应时间 | <= 500 ms | 1 |
| 请求成功率 | >= 99% | 2 |
| QPS | 在满足预期要求的情况下服务器状态稳定,单台服务器 QPS 要求在 1000 | 3 |
