通常,我们使用数据库的时候,需要两个或多个表互联才能得到我们想要的结果。但是,当数据库的数据到达一定的规模之后,DBA通常会建议我们不要使用 join 或者不建议三个表以上使用 join。
这是为什么呢?今天我们就来聊聊这个话题。
如果我们要来讨论为什么不建议使用join,首先我们需要一起了解一下join的底层原理。说起join的底层,我们就不得不介绍实现它的三个算法,分别是:Index Nested-Loop Join、Simple Nested-Loop Join和Block Nested-Loop Join。
为了方便测试,我创建如下数据表:
-- 创建数据表CREATE TABLE test_joinv1(id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,m INT(11) NOT NULL,n INT(11) NOT NULL,KEY `index_1` (`m`))ENGINE=InnoDB AUTO_INCREMENT=10000 DEFAULT CHARSET=utf8;-- 复制test_joinv2数据表CREATE TABLE test_joinv2 LIKE test_joinv1;-- 通过存储过程造部分数据给 test_joinv2drop procedure create_data;delimiter ;;create procedure create_data()begindeclare i int;set i=1;while(i<=10000)doinsert into test_joinv1 values(i, i, i);set i=i+1;end while;end;;delimiter ;call create_data();-- 复制部分 test_joinv1 的数据给 test_joinv2insert into test_joinv2 (select * from test_joinv1 where id >= 1000 and id < 2000);
Index Nested-Loop Join
Index Nested-Loop Join 翻译过来的意思是:索引循环嵌套链接,简称 INLJ。它是基于索引的链接算法。我们采用如下 SQL 进行解释:
SELECT * FROM test_joinv1 STRAIGHT_JOIN test_joinv2 ON (test_joinv1.m = test_joinv2.m)
注意:这里不使用join的原因是join已经经过优化了,会自动选择最优的驱动表,这里选择使用STRAIGHT_JOIN的原因是它既跟join的功能相同,同时只会选择它左边的表作为驱动表。
我们通过explain可以查看到数据表test_joinv2(被驱动表)上有一个索引被命中。具体如下:

这种状态下该条 SQL 的执行流程如下:
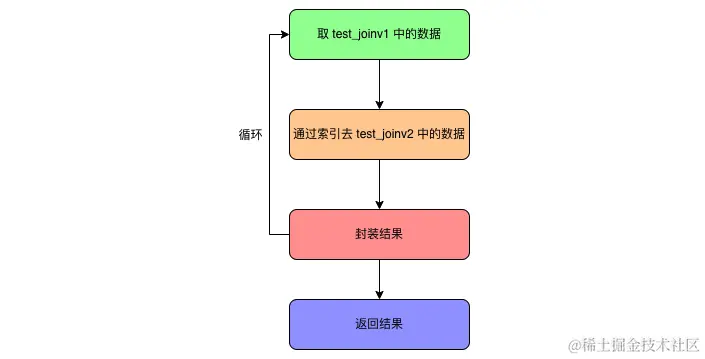
- 第一步:会在
test_joinv1数据表中获取一条数据。 - 第二步:通过第一步中获取的
m数据去test_joinv2数据表中进行匹配。 - 第三步:将
test_joinv2数据表中匹配到的数据与test_joinv1获取的数据合并,并重复前三步。 - 第四步:匹配完所有的结果之后,返回所有符合要求的数据。
在这个连表查询的过程中,首先会扫描 test_joinv1 数据表,总共需要读取 10000 行。当在第三步中拿第二步中获取的数据 m 到 test_joinv2 数据表中进行查询判断,但是由上图可知该条 SQL 命中了 test_joinv2 中 m 字段上的索引,所以根据索引的特性在数据表 test_joinv2 中按照树形算法查询相匹配的数据,所以查询的结果是 1000 行。由此可知,上述的 SQL 在使用 join 连表查询的结果是 10000 + 1000 = 11000次。
在使用 INLJ 时候我们还有一种情况,就是使用 test_joinv2 作为驱动表时,情况会如何呢?具体如下:
SELECT * FROM test_joinv2 STRAIGHT_JOIN test_joinv1 ON (test_joinv1.m = test_joinv2.m)
这时我们通过 explain 可以查看到数据表test_joinv1(被驱动表)上有一个索引被命中。具体如下:

这时查询的步骤具体分析如下:
- 第一步:首先会在
test_joinv2数据表中获取一条数据。 - 第二步:通过第一步中获取的
m数据去test_joinv1数据表中进行匹配。 - 第三步:将
test_joinv1数据表中匹配到的数据与test_joinv2获取的数据合并,并重复前三步。 - 第四步:匹配完所有的结果之后,返回所有符合要求的数据。
由此,我们可以得出,首先会扫描 test_joinv2 中的所有数据,也就是 1000 条;但是因为命中了 test_joinv1 数据表中的索引,所以在数据表 test_joinv1 中只需要查询 1000 条数据,最终的结果总共查询出 1000 + 1000 = 2000次。
通过对比,我们可以得出:当需要基于索引连表查询时,我们采用较为小的数据表(业内称之为:小表)作为驱动表,有利于提高查询的效率。
这里我们再来分析一下在不使用连表的情况下,数据库查询的流程。按照我们写代码的逻辑,首先会在 test_joinv1 数据表中查询所有的数据,也就是 10000 行;然后再去数据表 test_joinv2 中匹配查询,最终在 testjoinv2 表中查询的数据也是 1000 行。于是我们可以得出查询在分开查询的情况下,查询的次数依然是 10000 + 1000 = 11000 次。
于是我们可以得出:在使用索引的情况下,join 连表查询要比拆分开来的方式的性能要好。
下面,我们再来讨论一下在不使用索引的情况下,连表查询的性能又该是如何?
Simple Nested-Loop Join
Simple Nested-Loop Join 翻译过来的意思是:简单嵌套循环链接,简称 SNLJ。这个算法没有做任何优化,每一次查询都会扫描链接的所有表,性能低下。我们采用如下的 SQL 来进行解释:
SELECT * FROM test_joinv1 STRAIGHT_JOIN test_joinv2 ON (test_joinv1.m = test_joinv2.n)
简单嵌套循环链接其实就是简单粗暴地进行链接查询,具体分析如下。
首先,该条 SQL 会直接扫描数据表 test_joinv1 ,也就是说会查询 10000 次,然后拿在 test_joinv1 中查询出来的的数据全表扫描数据表 test_joinv2,最终查询的总次数为 10000 * 1000 = 1千万次。
所以,在使用 SNLJ 时,MySQL 数据库连表查询的性能是极差的。我不建议你使用,并且 MySQL 数据库也没有使用这种算法。
那么,在没有使用索引的情况下,MySQL 的连表查询情况到底该是如何呢?我们一起往下看。
Block Nested-Loop Join
Block Nested-Loop Join 翻译过来的意思是:缓存块嵌套循环链接,简称 BNLJ。这种算法是使用缓存块将所有的数据在内存中进行比较(主要是内存的速度非常快),其核心是利用内存的空间换取时间。具体分析如下。
我们仍然借助于上述 SNLJ 的 SQL 来分析。通过 explain 来查看这条 SQL 的具体情况:

我们可以看到 Extra 字段中有 Using join buffer (Block Nested Loop) ,也就说明该SQL将使用 BNLJ,下面我们来详细分析一下这个过程中经历的内容。
首先,我们来一起看一下该条 SQL 执行的过程。
- 第一步:首先会将数据表
test_joinv1中的数据查询出来,存放在join_buffer之中。 - 第二步:将数据表
test_joinv2中的数据查询出来,与join_buffer中的数据,按照test_joinv1.m = test_joinv2.n进行对比(对比的过程发生在内存之中)。 - 第三步:将符合条件的数据组装并返回。
由此,我们可以得出的是:
- 第一条:该过程需要扫描
test_joinv1数据表10000行;扫描test_joinv2数据表1000行。 - 第二条:通过条件
test_joinv1.m = test_joinv2.n需要在join_buffer中判断10000 * 1000 = 1千万次
这个时候不免有些朋友会想,如果 join_buffer 的空间不足以承载数据表 test_joinv1 中查询出来的所有的数据怎么办呢?
下面我们就来分析这一过程:
- 第一步:扫描数据表
test_joinv1中的数据,直至join_buffer没有剩余空间,进行下一步。 - 第二步:扫描数据表
test_joinv2中的数据,将取出来的数据与join_buffer中保存的数据进行比较,然后将符合条件的数据进行封装、返回。 - 第三步:清空
join_buffer中的所有内容,然后重复第一步和第二步,直至完成所有。
注意:MySQL 数据库中控制 join_buffer 空间大小的参数是 join_buffer_size。
总结一下,就是:BNLJ 算法相比较 SNLJ 来说是以空间换时间。SNLJ 的判断发生在数据磁盘之上,而 BNLJ 是发生在内存之中,相比较而言,内存的速度要远快于磁盘。所以,BNLJ 算法的性能要高于 SNLJ 算法。
在这个过程中,驱动表(这里是test_joinv1)跟join_buffer的比值直接影响SNLJ的性能。比值越小,join_buffer 所承载驱动表中的数据的比例就越大,扫描驱动表的次数就越少,性能就越高。
说到了这里,我们对比了实现 join 底层的三种算法之后,我们回到文章开头的问题:大厂/DBA 为什么不建议使用 join 呢?
其实,如果使用 Index Nested-Loop Join 算法的话,通过被驱动表索引的树结构去查询这个过程,从各个方面来讲都是可以使用的;但是如果使用 Block Nested-Loop Join 算法的话,性能就不是很理想了,特别是遇见数据量很大的数据表的时候,就会多次扫描数据表,进而导致性能低下,这个时候不建议使用;如果单纯地提高内存空间是可以提高性能的,但是这种办法对系统的性能的消耗又要增加不少。
总结
本文主要介绍了MySQL数据库实现连表查询join的三种算法。
INLJ主要是利用被驱动表的索引进行查询,避免了全表扫描,从而提高性能,推荐使用这种算法;SNLJ算法完全是嵌套查询,需要扫描每一个表,性能和复杂度非常地不理想,我不建议使用过这种算法;BNLJ是在SNLJ的基础上进行改编而来的,它是利用内存空间来换的时间,利用join_buffer内存空间作为载体,在内存中进行匹配,数据量较大时对系统的性能消耗会很大。
在实际应用场景中,不建议join超过三个表,应该join的数据表越多,扫描的数据表就越多,性能也就越差;能使用索引的就使用索引,如果不使用索引并且驱动表跟join_buffer的比值比较大的情况下,建议拆分查询,因为这样可以减少扫描数据表的次数,从侧面提高性能。
