在上一篇文章中我们就讲过在访问量比较大的情况下,MySQL 数据库最好的方式是利用横向扩容的方式将流量分配到不同的 MySQL 数据库服务器上。
这样做的好处是既能够提高 MySQL 数据库集群整体的性能,又能够摆脱服务器硬件性能的限制。
这里我要简单说明一下,MySQL 数据库集群主要有两部分组成,分别是 Master 节点和 Worker 节点。其中,Master 节点主要负责写的工作,Worker 节点主要负责读的工作。
这时我们很容易就能想象到,如果某个 Worker 节点宕机也就意味着少了一个读节点,对于整个 MySQL 数据库集群来讲影响有限;但是如果是一个 Master 节点宕机的话,对于整个 MySQL 集群来讲是毁灭性的,因为此时的 MySQL 整个集群完全处于可读状态。
那么今天我们就来聊一聊,如果 MySQL 集群的主节点出现问题时,那么整个 MySQL 集群该如何调整。
MySQL 主从复制中的问题
在 MySQL 5.6 之前,MySQL 主从复制主要是通过 binlog 日志的偏移量来实现的主从复制。
假设现在有 A、B 和 C 三台 MySQL 数据库,A 为 B 和 C 的主库的话,一般需要在 B 和 C 节点上执行如下命令:
[root@slave1 ~]# mysql -uroot -p123456 # 登录然后执行change master tomaster_host='A服务器的IP', -- 库服务器的IPmaster_port=3306, -- 主库端口master_user='用户名', -- 主库用于复制的用户master_password='密码', -- 密码master_log_file='二进制日志文件名称', -- 主库日志名master_log_pos='偏移量'; -- 主库日志偏移量,即从何处开始复制
执行上面命令的主要目的是让 B 和 C 节点能够顺利地连接到 A 节点上。
此时,B 和 C 节点就可以开始开启主从复制了,具体如下:
mysql> start slave;
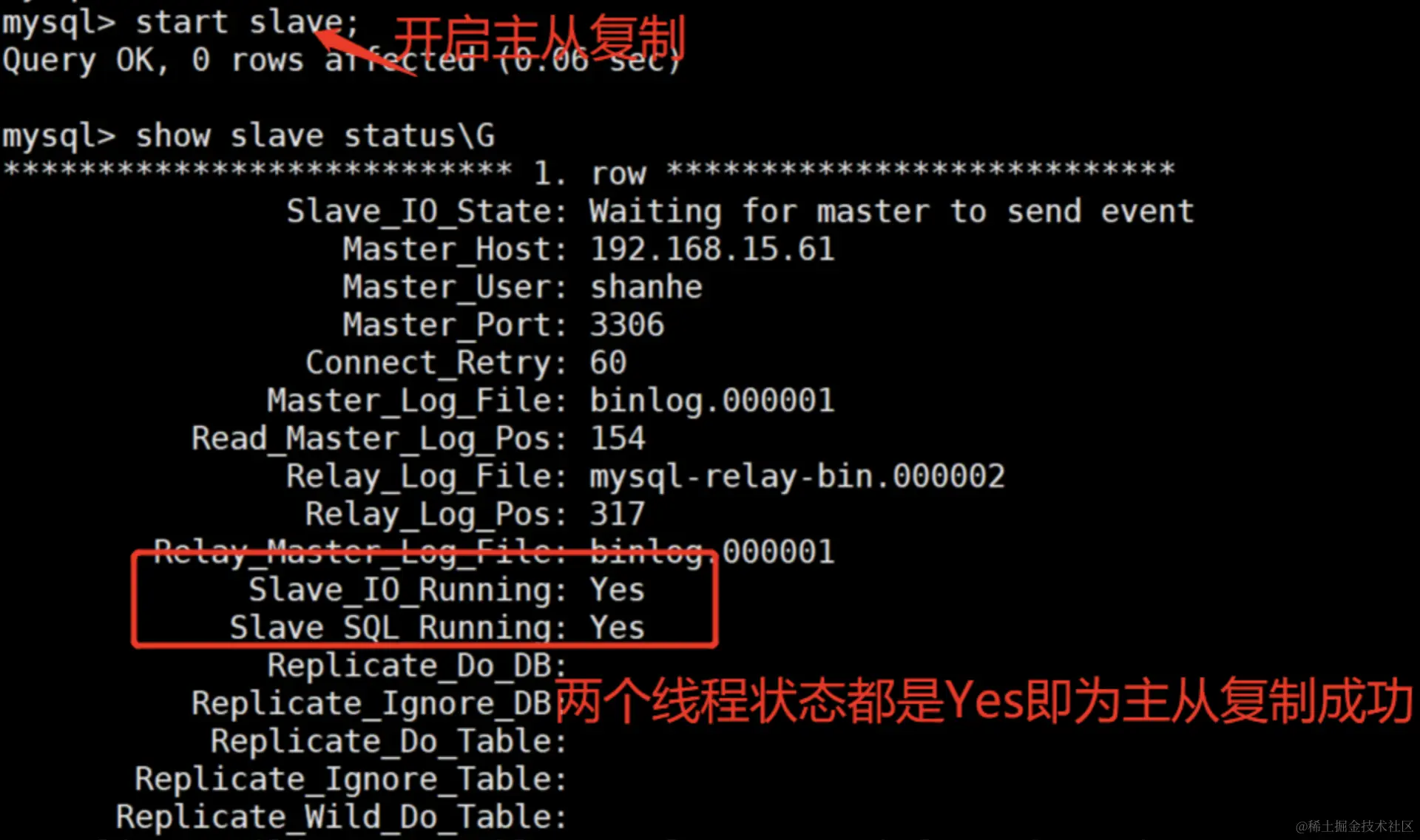
此时,我们的主从复制就算搭建成功了。
那如果某一时刻 A 节点突然宕机,B 和 C 节点该如何调整呢?
如果出现 Master 节点宕机的情况,通常我们将会在 B 和 C 两个 Worker 节点中选择一个数据同步较多的一个 Worker 节点作为主节点,然后将其他 Worker 节点的全部连接过来即可。
那么在这个过程中有没有可能会出现问题呢?答案是有的。
仔细分析上面连接 Master 节点的的语句我们就可以发现,其中 master_log_file 和 master_log_pos是需要重新指定的。
假设我们选择 B 节点作为新的 Master 节点的话,此时 B 节点的 master_log_file 和 master_log_pos 与 A 节点中的 master_log_file 和 master_log_pos 是存在偏差的,那么此时我们就不得不选择新的参数值,但是这个参数值是无法做到非常精确的。
试想一下,假设 A 节点刚执行完某一条 insert 语句的时候就发生了宕机,很有可能此时的 A 节点还没有将 binlog 日志同步出去,也就意味着 B 节点很有可能会发生数据丢失问题。
除此之外,假设 B 的偏移量比较小,也就意味着很多已经同步到 C 节点上的数据又会重新同步到 C 节点上,此时就很有可能在 C 节点同时插入两条相同的数据;那么此时很有可能会出现一个 Duplicate entry ‘id_of_R’ for key ‘PRIMARY’ 的错误,并且会立即停止数据同步。
这个问题怎么解决呢?有两个办法。
第一个办法是跳过这些错误,继续同步数据。在 MySQL 中提供了一个 sql_slave_skip_counter 的参数。这个参数的主要作用是指定主动跳过错误,如果我们想跳过上面的错误的时候,我们可以设置成 sql_slave_skip_counter=1,这样 Worker 节点不管出现什么错误都将会自动跳过。
如果觉得这个办法太过于宽泛,可以使用第二个办法,就是 MySQL 为我们提供的第二个参数 slave_skip_errors,这个参数最主要的功能就是指定忽略的错误码。假如我们要忽略主键冲突这个错误的时候,我们就可以配置成 slave_skip_errors = 1062(错误码可以自行百度)。
这个时候我们可能已经想到了,这种方法长时间使用,很容易就造成了主从数据不一致的情况。
那么这种问题,我们又该如何避免呢?
GTID
上面我们讲传统的 MySQL 主从架构时就介绍了当 Master 节点宕机或者无法使用时,会在 Worker 节点中选举出一个节点充当 Master 节点。但是传统的架构中这样做有一个缺点:由于无法精确地定位到某些事物是否执行,进而导致数据不一致的问题。
那么我们可不可以假设一下,如果我们给每一个事务都定义一个全局的(包括主从数据库中所有的事务)事务 ID,然后在每一台节点上执行相关事务时并记录该 ID。这样我们不就可以知道每一个节点是否执行某一个事务了嘛!
所以,为了防止上面介绍的传统架构可能导致数据不一致的情况发生,在 MySQL 5.6.2 版本之后,提供了一种 GTID 的方式来实现主从复制。
所谓的 GTID 就是全局事务 ID,也就是说给每一个事务都定义一个全局唯一的 ID。
它的格式是:GTID=source_id:transaction_id。
- source_id :一个实例第一次启动时生成的 UUID,全局唯一。
- transaction_id :是事务 ID,默认值为 1,每一次事务执行过后都会自增 1。
所以,GTID 具有全局唯一性和递增型。
如果要使用 GTID 的话,我们只需要在 MySQL 配置文件中增加 gtid_mode=on 和 enforce_gtid_consistency=on 两个参数即可。具体如下:
change master tomaster_host='IP',master_user='username',master_password='password',MASTER_AUTO_POSITION=1;
在上面就是使用 GTID 的方式实现主从复制,我们可以发现的是:跟传统的主从复制相比少了 master_log_file 和 master_log_pos 两个参数,并将其换成了 MASTER_AUTO_POSITION。
此时可以发现,我们从此可以避免查找 master_log_file 和 master_log_pos 两个参数的值了。
那么 GTID 又是如何实现的呢?下面我们就一起来梳理一下 GTID 主从复制的原理,具体如下。
第一步:master 节点更新数据时,会在该事务之前产生一个 GTID,同时记录到 binlog 日志文件中。
第二步:Worker 节点上的 i/o 线程将变更的 binlog 日志写入到本地的 relay log 中。
第三步:Worker 节点上的 sql 线程从 relay log 中获取该 GTID,然后对比Worker 节点上的 binlog 日志文件中是否有记录。
第四步:如果有该 GTID 的记录,说明该 GTID 的事务已经执行,Worker 节点就会忽略该事务。
第五步:如果没有该 GTID 的记录,Worker 节点就会从 relay log 中执行该GTID 的事务,并记录到本地上的 binlog 日志文件中。
第六步:在解析过程中会判断是否有主键,如果没有就用二级索引,如果二级索引没有就用全部扫描。
从上面的步骤我们就可以看出,GTID 完全规避了事务出现冲突的情况,进而保证了 MySQL 数据库在主从复制过程中的数据一致的问题。
总结
这篇文章我们主要介绍了在 MySQL 数据库中两种主从复制的方式。
首先我们解释了传统的 MySQL 主从复制的方式在主从切换的过程中很有可能会导致主从数据不一致的问题;为此,MySQL 5.6之后的版本又为我们提供了一个 GTID 的方式,通过判断 GTID 是否存在,进而判断是否执行该事务。
一般在生产环境中,强烈建议使用 GTID 的方式部署 MySQL 主从复制集群。
