Hello,非常非常地感慨,这段时间过得实在是太快了,眼看就要说再见啦!
我相信在这段短暂的时光里,咱们都有很多的收获,那么我在这里也感觉到了非常浓郁的学习氛围。
这种氛围是我在其他地方所感受不到的,这也归根于咱们都有一颗爱学习的心和掘金为我们提供的这个学习平台。
聊聊 MySQL 的高性能
说起从底层上造就我们的高性能 MySQL,我们无外乎是从硬件、内存和索引这三个方面来展开讨论的,如果非要从底层上来讲的话,也无外乎是用 MySQL 本身的配置让我们的 MySQL 更有效地利用硬件的性能来增强 MySQL 自身的容量和承载能力。
在前面的文章中,我们介绍了很多优化 MySQL 的方法和案例,例如我们很多计数的时候都很担心查出的字段太多会不会导致 MySQL 变得很慢。
其实,如果我们读了第 4 篇《你真的了解 count(*) 的底层原理吗?》这篇文章,就应该已经知道不会变慢,因为 MySQL 数据库对 count(*) 在底层上已经有过优化啦。
再例如,我们看完了第 7 篇《InnoDB 存储引擎的底层逻辑架构》这篇文章之后,我们应该已经了解到 InnoDB 存储引擎中是分为很多个块的(buffer pool、change buffer、redo buffer 等),并且每一个块都有自己独特的功能。如果我们在实际工作中,遇到了相关的问题时,我们就应该知道该如何去优化了,而不是单纯地增加服务器内存的容量。
虽然,这本小册咱们讲述了很多在使用 MySQL 过程中性能调优的相关内容。但是 MySQL 性能调优部分仍然还有很多很多的地方我们没有讲到,这个是需要大家去经历和拓展的。
在这里,我提出几个小册中没有涉及到的关于 MySQL 性能调优的相关内容,这些内容通常是因为讲完怎么解决它还不需要一篇完整的文章,所以我就在这里简要地跟大家讨论一下这几个问题。
问题一:如果 MySQL 数据库中某一个数据表有一亿条数据,该如何分页呢?
我深刻地记得,那天是周四(我们公司规定,每周四进行代码发布),处理完公司事情之后,我就愉快下班了,正想着该如何去找女朋友玩耍的时候,突然,群里艾特我的信息过来啦!
如果不出意外的话肯定会出意外,果然刚上线的项目出问题啦!
好吧!赶快回家,打开电脑,着手解决吧!
经过沟通,有一个线上的接口不断在刷着 MySQL。执行的 SQL 如下:
select * from info where name='xxx' order by id limit 200000000,25;
当前这个数据表中数据很多,查询起来也就很慢。不过这个数据表中总共才 2 千万条数据,不应该查询到 200000000 ,这说明有人在刷我们的数据。
不管怎么说,数据库查询中遇到这种情况我们是需要解决的。
那么,这里我们就不得不讨论一下 limit 这个关键字啦!
对于 limit 而言,它是将偏移量之前所有的数据全部查询出来,然后再将分页之前的数据丢弃,只保留分页的那几条数据。
了解完 limit 这个关键字之后,我们再回头看一下上面的 SQL ,我们就会明白,每一次查询都需要查询将近所有的数据,所以才导致了数据库变慢。
了解完这个问题之后,我们再来想一下该如何解决。
首先,我们造一千万条数据,用来测试:
#1. 准备表create table s1(id int,name varchar(20),gender char(6),email varchar(50));#2. 创建存储过程,实现批量插入记录delimiter $$ #声明存储过程的结束符号为$$create procedure auto_insert1()BEGINdeclare i int default 1;while(i<10000000)doinsert into s1 values(i,'shanhe','male',concat('shanhe',i,'@helloworld'));set i=i+1;select concat('shanhe',i,'_ok');end while;END$$ #$$结束delimiter ;#3. 查看存储过程show create procedure auto_insert1\G#4. 调用存储过程call auto_insert1()
添加完数据之后,再添加一下索引。这里需要说明一下,如果之前添加索引的话,很容易就会导致跑数据的时候变慢,跑完数据之后添加索引会好一点。
测试一下:
select * from s1 limit 0,25;受影响的行: 0时间: 0.001sselect * from s1 limit 9999999,25;受影响的行: 0时间: 15.001s
通过上面查询出来的结果来看,同样的数据表,翻页越往后越慢。
那么这个时候很多朋友一定想问,这该怎么办呢?
首先,我们需要分析一下这个问题。
如果我们需要让查询变得快起来的话,一般是选择使用索引的;其次,我们知道 limit 会查询出来很多不必要的数据,也就是说要想查询变快,就得让 limit 少查询不必要的数据。这样我们就可以使用下面这种方式进行查询:
select * from s1 where id > (select id from s1 where id > 9999974 limit 1) limit 25;受影响的行: 0时间: 1.541s
由上面的结果,我们可以看出:虽然我们查询出来的数据花费的时间仍然需要 1.5 秒,但是相比较 15 秒来说,已经是非常非常优秀的啦!
问题二:什么是回表?原理是什么?
所谓的回表,用一句话解释就是:该 SQL 第一次查询并没有直接获取想要的数据,需要二次查询之后才能得到想要的数据,在 MySQL 中,我们把这种现象称之为回表。
这里我们举个例子。
首先,我们创建一个数据表:
CREATE TABLE test (
id INT(11) PRIMARY KEY AUTO_INCREMENT NOT NULL,name VARCHAR(20) NOT NULL,sex char(1) DEFAULT NULL,KEY index_1 (name)
);
— 添加两条数据 INSERT INTO test (name, sex) VALUES (‘小明’, ‘1’),(‘小花’, ‘2’);
- 测试回表
这里我们先按照索引的方式进行查询:
mysql> EXPLAIN SELECT name FROM test where name = '小明';+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+| 1 | SIMPLE | test | NULL | ref | index_1 | index_1 | 62 | const | 1 | 100.00 | Using index |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)
我们可以看到的是,Extra 字段中的结果是 Using index,因此说明 MySQL 本次查询时是直接使用索引的方式进行查询的,所以此次查询不需要回表,也就是说速度相对而言会快一些。
下面,我们再测试一个回表的 SQL:
mysql> EXPLAIN SELECT name,sex FROM test where name = '小明';+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | test | NULL | ref | index_1 | index_1 | 62 | const | 1 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.00 sec)
从上面的结果中,我们可以看出 Extra 字段中的值是 Null,也就是说此次查询没有命中任何索引。
其实不然,因为 where name = '小明' 肯定是命中了索引 index_1 的,那么为什么 Extra 仍然还显示 Null 呢?原因很简单,就是因为第一次命中索引之后并没查询出数据,本次查询时需要第二次回表查询的,所以此次查询才显示为 NULL,此次查询又需要二次消耗 MySQL 性能,并提高了查询延时,降低了数据库性能。
所以,MySQL 性能调优中需要注意的一个非常大的一点就是避免回表。
当然啦!MySQL 数据库中还有很多很多性能调优的相关知识点。在这里我们就先介绍到这。
展望 MySQL 的未来
MySQL 数据库现在仍然是世界上排名第二的关系型数据库,如下排行榜所示: !
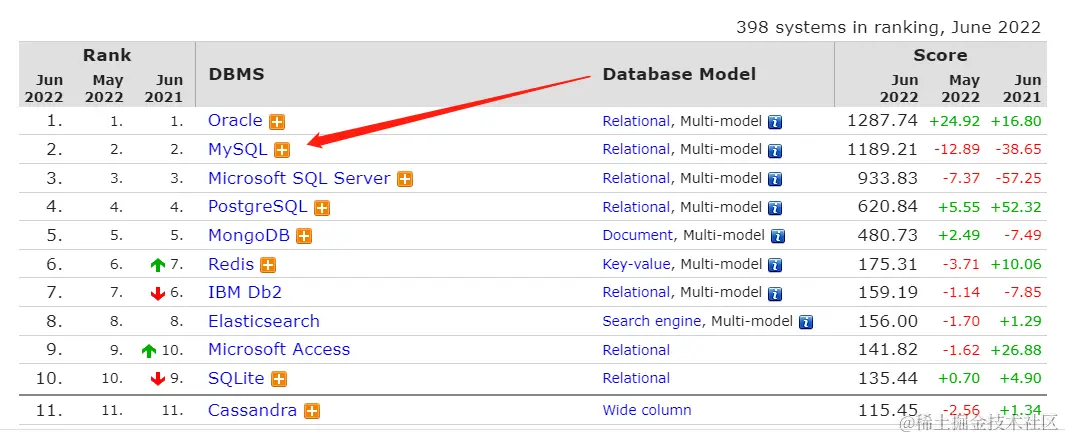
可以看到,它在国内的市场也仍然是占有率非常高的。
但是仍然有一些问题是 MySQL 目前还无法解决的。例如,MySQL 数据库中某一个数据表有上亿的数据,这个时候就像你在宇宙中遇见了黑洞一样,任何物理规则都失去了它原本的形式;也就是说,当 MySQL 数据库某一个数据表中有上亿的数据的时候,任何对于 MySQL 数据库的优化都是徒劳的。
这个时候,我们就需要借助一下其他工具了,那么我现在跟大家介绍一下我们国产很多优秀的数据库,具体如下:
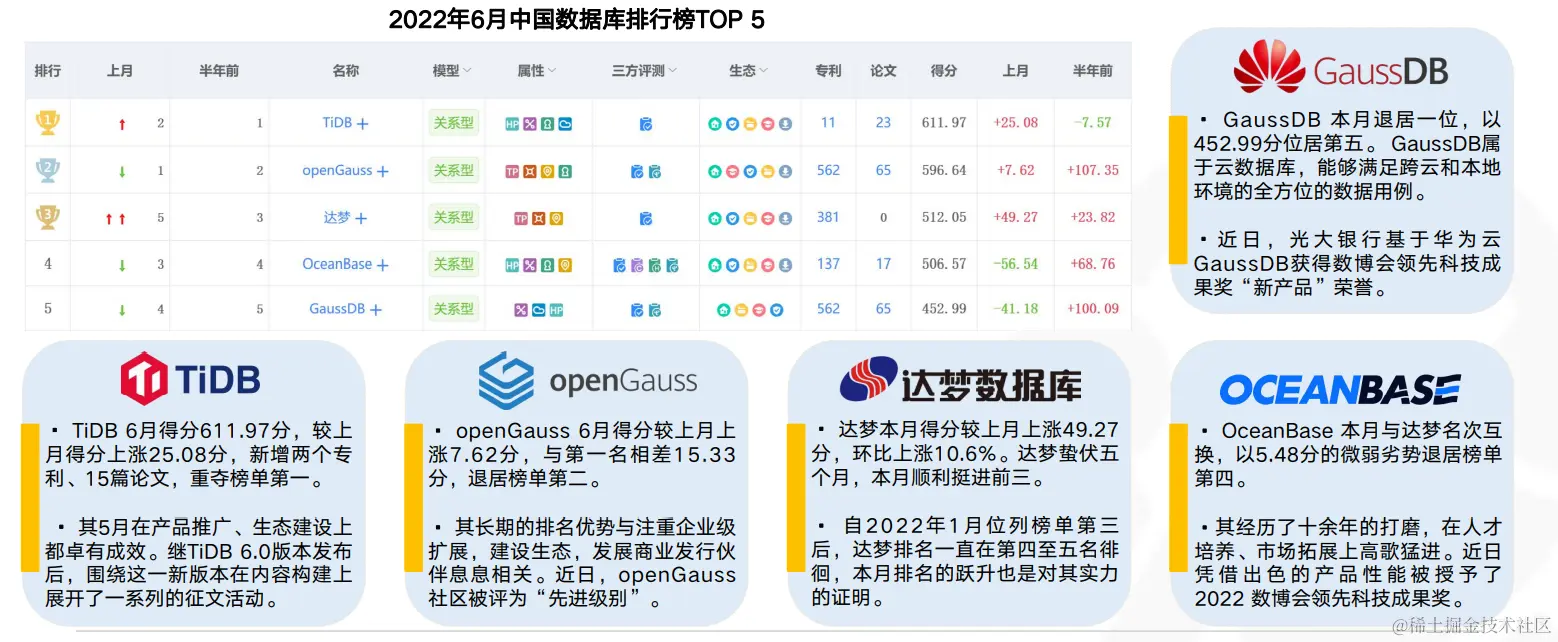
注:数据来源于墨天轮。
从上面的图中,可以看出,我们国产的数据库也正在蓬勃发展。
其中最为亮眼的就是 TiDB,这个数据库是一个关系型数据库,并且是完全兼容 MySQL 的数据库。
按照中国互联网发展这一情况来看,未来互联网将越来越偏向于分布式数据库。这是因为我们中国互联网逃不过去的一点就是大数据。
相比较 MySQL 数据库而言,TIDB 数据库更胜任一些处理大数据的场景;更有效地压缩数据,进而减少存储压力;更擅长对数据的二次处理。
所以,未来解决大数据这种情况,MySQL 就会显得越来越捉襟见肘。看来,我们还得为了未来职业发展继续卷呀!
留言
