在我们日常的工作中,处理 MySQL 数据库相关问题时,我相信绝大多数 DBA 处理最棘手的问题就是数据库主从数据不一致的问题。
处理过关于 MySQL 数据库主从数据不一致的朋友一定印象非常深刻,因为稍有不慎就会将造成原有数据的丢失,并且这种丢失是持久性的,也就是说如果我们没有相关备份的话,该数据将会永久丢失,这对于一家互联网公司来说将是非常致命的错误。
那么,我们该如何保证 MySQL 数据库主从数据一致呢?
在介绍这个问题之前,我首先跟大家介绍一下 MySQL 数据库主从复制的原理。
注意:在开启主从复制之前,需要在 Worker 节点上关联 Master 节点,不知道的朋友可以上网查询一下,这里不再赘述。
通常,我们在从库上执行 start slave;,开启主从复制。我们确认是否成功开启主从复制最简单的办法是通过 show slave status; 查看 IO 线程 和 SQL 线程 是否开启。
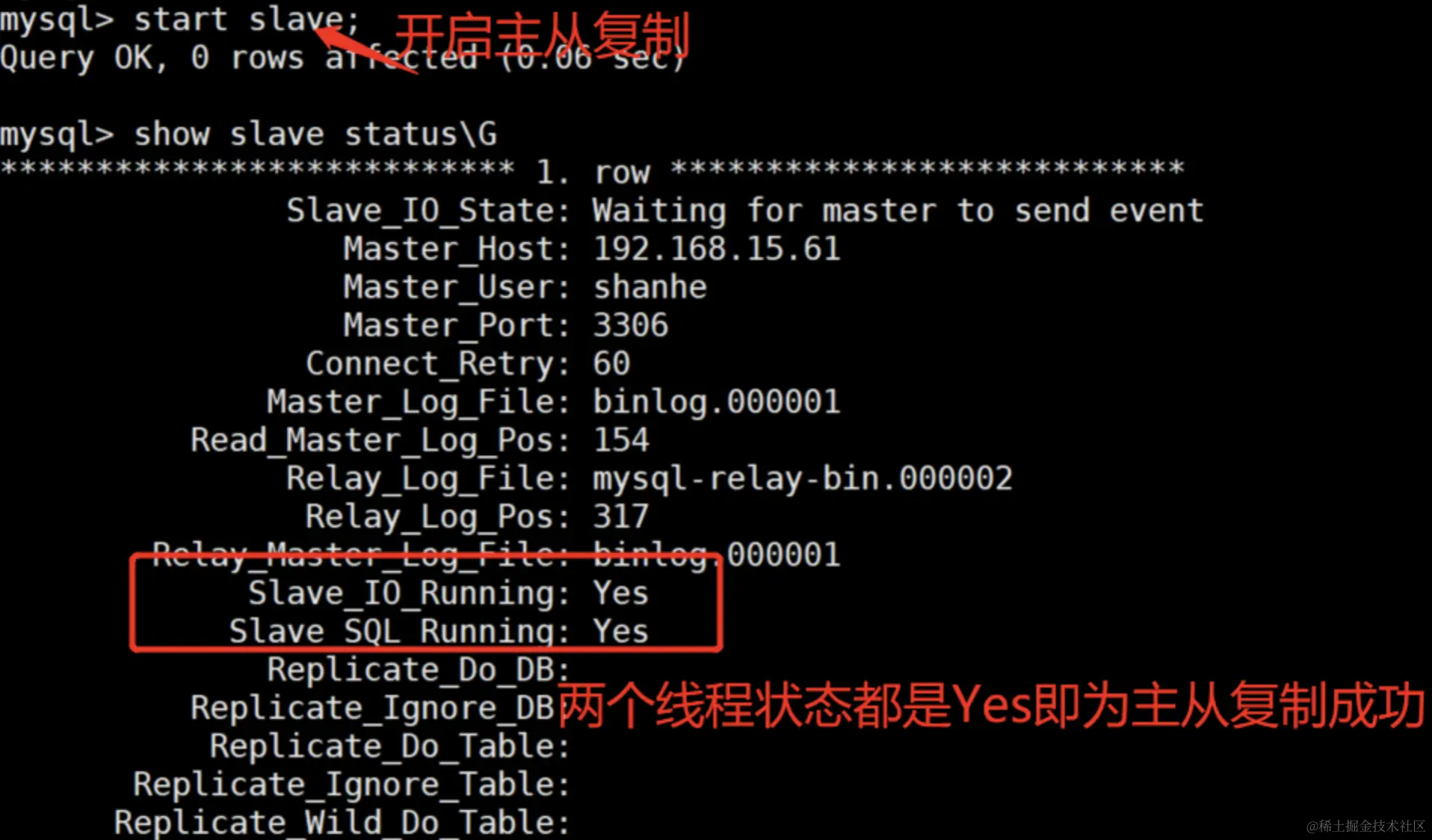
下面我们来介绍一下这两个线程背后的逻辑。
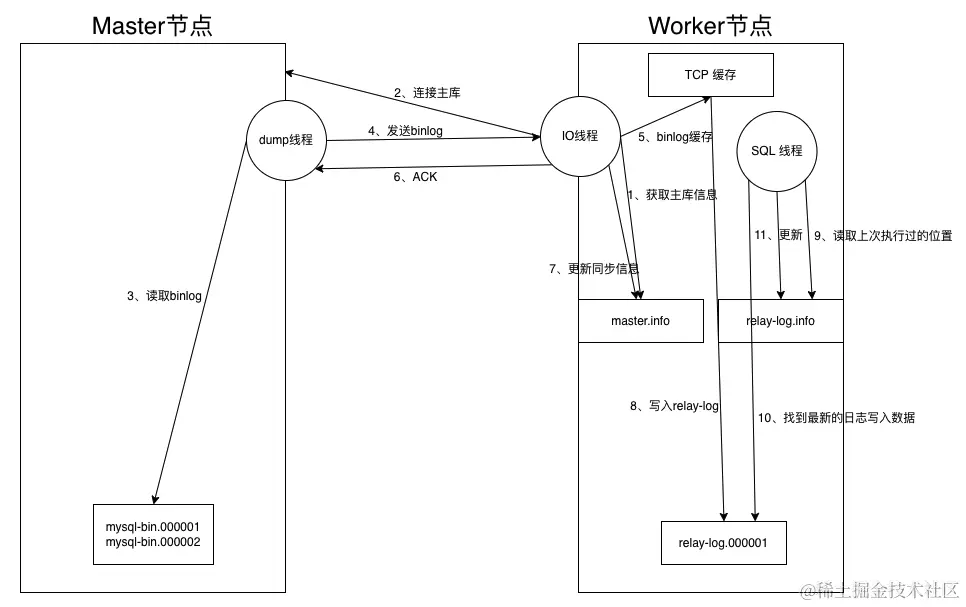
- 在从库上执行
start slave;,开启主从复制。 - 从库的
IO线程开始在读取Master节点信息,该信息保存在master.info中。 - 主库在接收到从库的主从同步请求时,会开启一个
dump线程,主要用于将Master节点的binlog日志发送给Worker节点。 Worker节点中的IO线程接收Master节点发送过来的binlog日志的内容。IO线程接收到的binlog日志内容并不是直接写入到 Worker 节点,而是先保存在缓存之中,这个步骤最主要的原因是为了防止大量数据同时写入中继日志时导致的数据库异常。Worker节点在接收完Master发送过来的数据时,会回复 Master 节点一个 ACK 信号,这个步骤的目的是告诉 Master 节点数据已接收完毕。IO线程更新本节点中的master.info,这个步骤主要是记录当前复制数据的留痕,以便下一次追加复制数据。IO线程将TCP缓存中的数据分批写入中继日志中,做持久化管理。此时IO线程的数据到此结束。SQL线程读取relay-log.info获取上次同步数据的位置。SQL线程根据上一个步骤中获取的位置开始读取中继日志中的数据SQL线程将读取出来的数据分批写入本节点中,并更新relay-log.info文件。- 中继日志自动清理同步过的数据。 此时,一次主从复制的过程完成。
注意:上面步骤中的 ACK 表示回应的意思。一次基于 TCP 协议的通信中,请求方会发送一个 SYNC 信号请求连接,连接完成之后被请求方会返回一个 ACK 信号以示回应。
我们通过上述的主从复制的步骤中可以看到,一次主从复制是比较复杂的。那么在这些复杂的过程中,有哪些地方可能造成数据丢失,进而导致数据不一致呢?
注意:在了解下文之前,建议先读一下 第十五篇文章:MySQL 中的日志类型这么多,它们都有哪些作用?
最主要的就是 binlog 日志中的数据丢失。下面我们来详细介绍一下 binlog 日志为什么会丢失数据。
在介绍 binlog 日志相关问题之前,先创建一个测试数据表:
CREATE TABLE `t1` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `index_1` (`a`),KEY `index_2` (`b`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO t1 VALUES (10,60,10);INSERT INTO t1 VALUES (20,50,20);INSERT INTO t1 VALUES (30,40,30);INSERT INTO t1 VALUES (40,30,40);INSERT INTO t1 VALUES (50,20,50);INSERT INTO t1 VALUES (60,10,60);
首先,我们简要说明一下 binlog 日志的三种类型,分别是 statement、row 以及 mixed。下面我们不详细介绍这三个类型的,如若不清楚可以参考 第十五篇文章:MySQL 中的日志类型这么多,它们都有哪些作用?。在这里我们只介绍在三个类型可能导致的问题。
当 binlog 日志的类型设置成 statement 时,binlog 日志中记录的是我们执行的 SQL 的原文。具体如下:
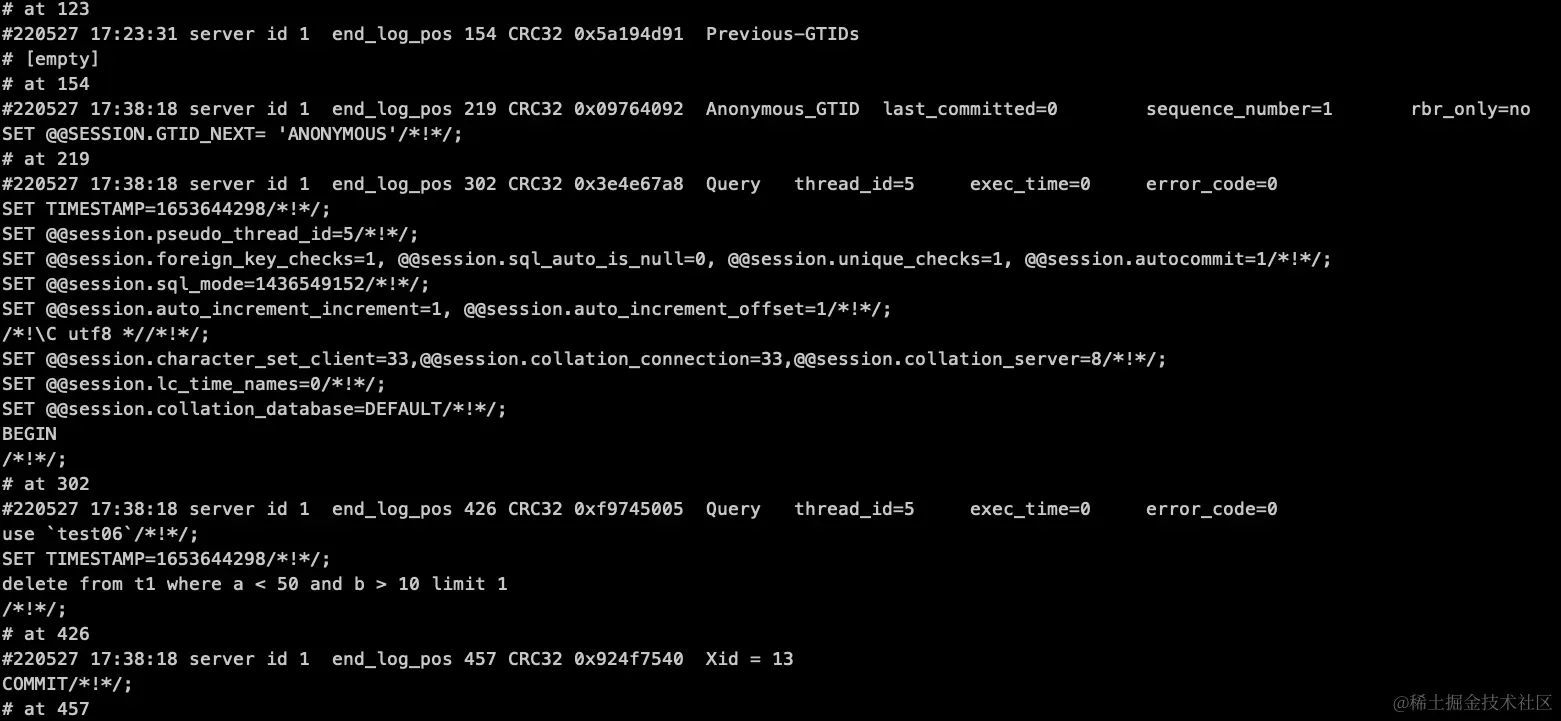
mysql> delete from t1 where a < 50 and b > 10 limit 1;Query OK, 1 row affected, 1 warning (0.01 sec)mysql> show binlog events in 'mybinlog.000001';+-----------------+-----+----------------+-----------+-------------+--------------------------------------------------------------+| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |+-----------------+-----+----------------+-----------+-------------+--------------------------------------------------------------+| mybinlog.000001 | 154 | Anonymous_Gtid | 1 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' || mybinlog.000001 | 219 | Query | 1 | 302 | BEGIN || mybinlog.000001 | 302 | Query | 1 | 426 | use `test06`; delete from t1 where a < 50 and b > 10 limit 1 || mybinlog.000001 | 426 | Xid | 1 | 457 | COMMIT /* xid=9 */ |+-----------------+-----+----------------+-----------+-------------+--------------------------------------------------------------+6 rows in set (0.00 sec)
从上方的执行结果来看,似乎是没有什么问题的,但实际它是有问题的,具体的问题如下:
-- 查询当前数据库的警告信息mysql> show warnings;+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Note | 1592 | Unsafe statement written to the binary log using statement format since BINLOG_FORMAT = STATEMENT. The statement is unsafe because it uses a LIMIT clause. This is unsafe because the set of rows included cannot be predicted. |+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
通过上面的 SQL 语句我们可以看出,当我们采用 BINLOG_FORMAT = STATEMENT 的时候,执行 delete from t1 where a < 50 and b > 10 limit 1; 这条 SQL 时,会报一个警告错误,这个错误的原因是什么呢?
在介绍这个问题的原因之前,我们先将 binlog 日志的类型更换成 row 类型,看一下 binlog 日志在 row 类型下是否会发生这一问题。具体如下:
mysql> SHOW GLOBAL VARIABLES LIKE '%BINLOG_FORMAT%';+---------------+-------+| Variable_name | Value |+---------------+-------+| binlog_format | ROW |+---------------+-------+1 row in set (0.01 sec)mysql> delete from t1 where a < 50 and b > 10 limit 1;Query OK, 1 row affected (0.01 sec)mysql> show warnings;Empty set (0.00 sec)
这个时候,我们可以惊奇地发现,当我们将 binlog 日志的类型设置成 row 时,上面的错误居然消失了。这个时候我们一定很想问为什么。
在介绍具体原因之前,我们首先来看看 binlog 日志中记录的两种模式的不同。具体如下:
执行如下 SQL ,来解析 binlog 日志中的二进制日志。
[root@dxd ~]# mysqlbinlog -vv mybinlog.000001 --start-position=123;
- STATEMENT
- ROW
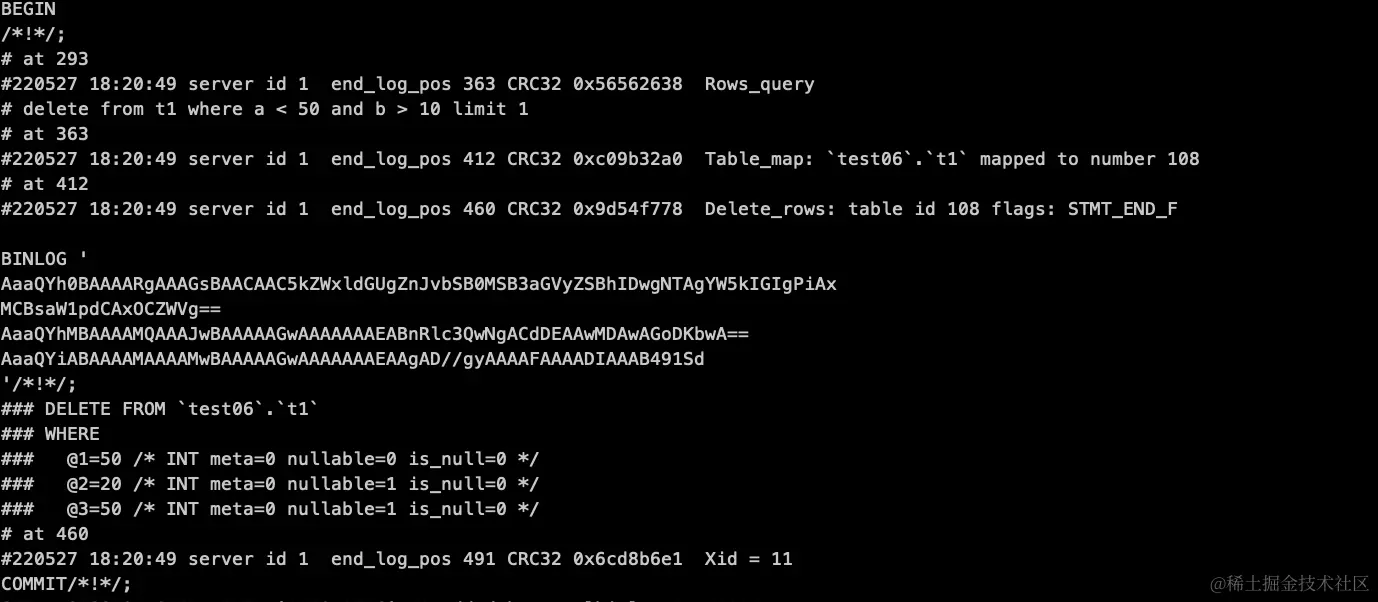
通过比较,我们可以明显看出,STATEMENT 类型中是直接保存 SQL 的,但 ROW 类型中并没有直接保存 SQL ,而是通过事件的方式保存需要处理的数据的。
就拿我们上面执行删除数据的这条语句来说,当 binlog 日志类型为 STATEMENT 时,在 binlog 日志中记录的是原生 SQL,那么如果我们直接拿这条 SQL 去数据库执行时,可能就会存在争议,具体如下:
如果我们按照索引 index_1 去执行该 SQL 时,我们删除的这一条数据可能是 id = 30;但是如果我们按照索引 index_2 去执行该 SQL 时,我们删除的数据却可能是 id = 20。此时如果我们按照这种方式去 Worker 节点执行该 SQL 时,我们是无法保证 Worker 节点和 Master 节点删除的数据是一致的,这也就是导致主从数据不一致的根源。
那么,如果我们使用 ROW 类型时,为什么没有这一问题呢?此时我们通过 ROW 类型的图可以看到的是在 ROW 类型下并不直接保存具体的 SQL,而是通过事件的方式(其实也就是利用主键),这种方式就有效地保证了 Worker 节点和 Master 节点之间数据一致性。
但是,我们可以看到,ROW 类型的日志中记录了很多其他的字符,这其实也是 ROW 类型的一个非常大的缺点,就是非常占用存储空间。
那么,我们总结一下: STATEMENT 类型可能会导致数据不一致,但是它的数据量比较小,节省存储空间;而 ROW 能够有效地处理数据不一致的问题,但是占用的空间非常大。
为了解决上面的问题, MySQL 为我们提供了一个中性的 binlog 日志类型,即:mixed。
mixed 类型最主要的就是结合了 STATEMENT 类型存储数据量比较小的优点,同时也结合了 ROW 类型解决数据不一致这一特点,也就是说通常在记录不会产生歧义的 SQL 中使用 STATEMENT 类型的记录方式,在有可能产生歧义的 SQL 中使用 ROW 类型的记录方式。
总结
今天,我们介绍了 MySQL 数据库主从复制过程中可能会遇到的一些问题。其中最主要的就是 binlog 日志在 STATEMENT 类型下有着存储数据量小的优点,但是也有导致数据不一致的情况;ROW 类型能够有效地解决数据不一致这种情况,但是也有存储数据量大这一缺点;MySQL 数据库结合前面两种类型的优点,又为我们提供了一个 mixed 类型。
在日常的生产环境中,常用的 binlog 日志类型就是 mixed 类型。
