在开始讲解今天的内容之前,你可以先想象这样一个场景。
情人节这天,你给你媳妇发了一个 50 块钱的红包,那么你的银行卡中必定会先扣除 50 块钱,然后你媳妇的银行卡中必定是增加 50 块钱。但是,假设你在发红包的时候,刚刚输完密码,啪,手机没电关机啦,这个时候你的银行卡扣了 50 块钱,但你就那么确定你发的红包你媳妇铁定能收到吗?你真的了解发红包背后的逻辑吗?那怎么保证绝对不会出现“收不到”的这种情况呢?
好,那么下面我们就来好好地讨论一下这个问题以及相关的逻辑、知识点。
如果说,我们用数据库来存放所有的数据,特别是存放关于金钱的数据时,每次对数据的更改都必须慎之又慎,一定要保证所有的操作都必须全部修改成功,要么全部不修改。就像你发的红包,要么成功,你的银行卡中扣除 50 块钱,你媳妇的银行卡中增加 50 块钱,要么都不扣除和增加,这样就能够保证数据的绝对安全。
这也是我们接下来要讨论的 MySQL 数据库中的一大特性:事务。
什么是 MySQL 数据库中的事务呢?
用一句话来说,MySQL 中事务的主要作用是利用 MySQL 数据库内部的数据结构来保证 MySQL 中的一系列修改数据的操作要么全部修改成功、要么全部不修改。
对于 MySQL 数据库来讲,它的事务主要有四个特性,分别是原子性、一致性、隔离性和持久性。
举个例子(还拿给媳妇发红包这个事来说),在发红包这个过程中,你和你媳妇的银行卡同时加减 50 块钱,这个过程是发生在一个事务之内的。对于这个事务来说,这个过程是没有办法进行拆分的,像这种无法拆分的特性属于 MySQL 数据库事务的原子性。
下面我们用一个案例证明:
-- 创建一个inof表,用来做案例mysql> CREATE TABLE info(-> id INT PRIMARY KEY AUTO_INCREMENT,-> name VARCHAR(20),-> money INT-> );Query OK, 0 rows affected (0.01 sec)
准备两条实验数据,分别自己和媳妇各 1000 块钱。
mysql> INSERT INTO info (name, money) VALUES ('自己',1000),('媳妇',1000);Query OK, 2 rows affected (0.00 sec)Records: 2 Duplicates: 0 Warnings: 0mysql> select * from info;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 自己 | 1000 || 2 | 媳妇 | 1000 |+----+--------+-------+2 rows in set (0.00 sec)
接下来就开始模拟自己情人节给媳妇发 50 块钱红包时数据库的全过程。
首先,在不使用事务的情况下:
-- 自己的money减去50mysql> update info set money=money - 50 where id = 1;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 媳妇的money加上50mysql> update info set money=money + 50 where id = 2;Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 最后结果mysql> select * from info;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 自己 | 950 || 2 | 媳妇 | 1050 |+----+--------+-------+2 rows in set (0.00 sec)
但是,假设恰好在你自己发红包的过程中数据库出现故障,就可能导致红包发送失败,进而导致你自己的 money 减少了50,而媳妇的 money 却没有加 50。请看案例演示:
-- 自己的money减去50mysql> update info set money=money - 50 where id = 1;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 出现了故障。。。--最终查询出来的数据很可能如下mysql> select * from info;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 自己 | 950 || 2 | 媳妇 | 1000 |+----+--------+-------+2 rows in set (0.00 sec)
这个时候,一个完美的情人节很可能会草草收场,怎么办呢?下面请看使用 MySQL 事务的案例。
在使用事务的情况下:
-- 还原一下数据mysql> select * from info;+----+------+-------+| id | name | money |+----+------+-------+| 3 | 自己 | 1000 || 4 | 媳妇 | 1000 |+----+------+-------+2 rows in set (0.00 sec)-- 给媳妇发50块钱红包,此次首先开启事务(start transaction;的作用是开启事务)mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> update info set money=money - 50 where id = 1;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0
恰巧此时数据库出现故障,当数据恢复之后再次查询数据,结果如下:
mysql> select * from info;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 自己 | 1000 || 2 | 媳妇 | 1000 |+----+--------+-------+2 rows in set (0.00 sec)
也就是说,如果使用 MySQL 事务来操作的话,只要所有的数据修改动作没有全部完成,这时出现故障会自动将所有的数据还原成原来的数据。
由此可见,MySQL 事务的作用就是利用 MySQL 数据库内部的某种机制来保证数据的修改操作要么全部执行完毕,要么全部都不执行,从而保证了不会出现只修改某一部分数据的情况。
同时我们知道咱们跟媳妇的银行卡是同时加减 50 块钱的,那么这个过程是同时进行的,要么全部提交,要么全部不提交,也就是我们说的 MySQL 数据库事务具有一致性。
同样的,咱们跟身边的亲人单独发红包,别人是没有办法收到这个红包的,那么 MySQL 事务与事务之间也是不会相互影响的(哪怕是修改同一个数据也是互不影响的),这个就是我们上面说的 MySQL 数据库的隔离性。
一旦红包被抢到,那么将无法撤回,MySQL 事务也是一样,一旦提交,将会永久修改数据,无法撤回,这一点体现了 MySQL 数据库事务的持久性。
MySQL 事务的使用
上面说了那么多,你一定很想了解,MySQL 数据库的事务这么强大,那么它到底是怎么使用的呢?底层又是通过哪种机制来保证数据安全的呢?下面我们来讨论一下。
MySQL 事务具备两个基本功能,一个是回滚(rollback) ,另一个是提交(commit) 。事务一旦回滚就相当于什么都没有修改,那么相反地一旦提交就相当于把本次事务中的所有语句全部生效。下面我们还是通过案例来说明:
-- 准备数据mysql> select * from user;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 宋江 | 1000 || 2 | 吴用 | 900 || 3 | 李逵 | 800 |+----+--------+-------+3 rows in set (0.00 sec)
案例 1:宋江给李逵发送 50 块钱恋爱红包,考虑到他比自己还黑,想了想还是算了。
-- 开始转账mysql> START TRANSACTION;Query OK, 0 rows affected (0.00 sec)mysql> UPDATE user SET money = money - 50 WHERE name = "宋江";Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> UPDATE user SET money = money + 50 WHERE name = "李逵";Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0--- 密码都输入了,但是想想还是算了,于是就放弃了(ROLLBACK)转账mysql> ROLLBACK;Query OK, 0 rows affected (0.00 sec)-- 查看一下,发现钱一分没动mysql> SELECT * FROM user;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 宋江 | 1000 || 2 | 吴用 | 900 || 3 | 李逵 | 800 |+----+--------+-------+3 rows in set (0.00 sec)
上面案例完美地说明了事务回滚的特性,下面我们再用一个案例说明事务提交的特性。
案例 2:由上可知,宋江发现李逵太黑于是去找了小白脸吴用,作为告白的诚意,宋江给吴用转了十块钱红包。
-- 咱们的梁山泊主,宋江宋押司开始转账mysql> START TRANSACTION;Query OK, 0 rows affected (0.00 sec)-- 发送了红包mysql> UPDATE user SET money = money - 10 WHERE name = "宋江";Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 咱们的白面小生,用他粉嫩的芊芊细手收了红包,并答应跟咱们伟大的宋押司好一个晚上mysql> UPDATE user SET money = money + 10 WHERE name = "吴用";Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 双方谈好价格之后,开始进入了春宵。mysql> COMMIT;Query OK, 0 rows affected (0.00 sec)-- 第二天,李逵仔细查看了一下各自的账单。。。mysql> SELECT * FROM user;+----+--------+-------+| id | name | money |+----+--------+-------+| 1 | 宋江 | 990 || 2 | 吴用 | 910 || 3 | 李逵 | 800 |+----+--------+-------+3 rows in set (0.00 sec)
上面的案例充分地说明了数据库事务提交的特性。所有的事务一旦提交就会同时修改了此次事务包含的所有的事务,李逵都撤回不了(事务的持久性)。
MySQL 事务的原理
基于上面之所学,我们知道了宋押司给小白脸吴用发了十块钱红包,那么你知道这个发红包的过程中提交和回滚是怎么做到的吗?下面跟我一起来剖析一下。
在我们使用 MySQL 事务的过程中,包含两个日志,分别是:redo log 和 undo log。
如果需要修改数据,则 MySQL 数据库首先会把硬盘中的数据读取到内存(Buffer Pool)中以及 redo log 和 undo log 中,然后执行修改操作,具体过程可参考如下示意图:
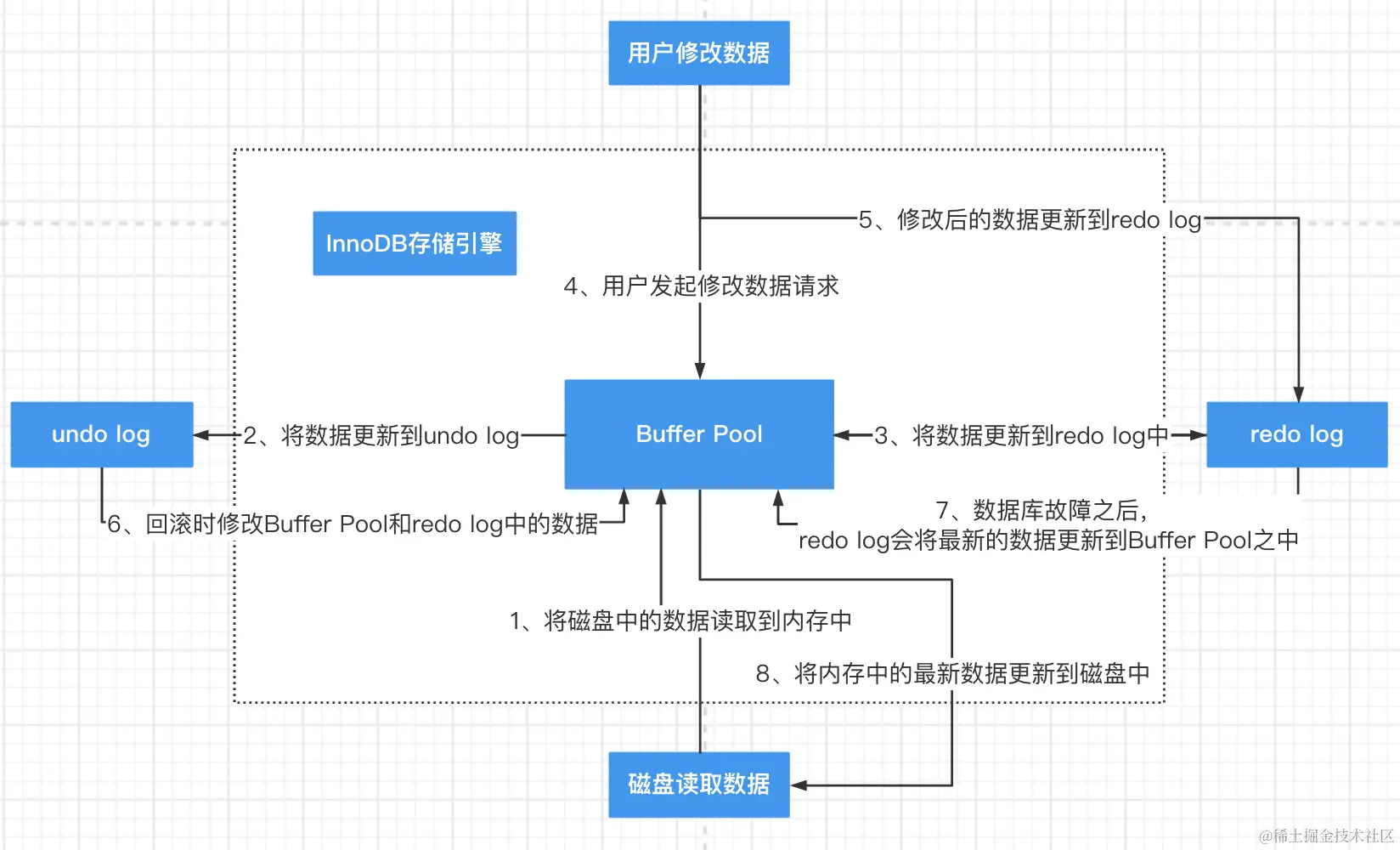
通过该示意图,我们可以看到整个过程可总结为如下。
- 第一步:将磁盘中的数据读取到 Buffer Pool。
- 第二步:将 Buffer Pool 中的数据读取到
undo log之中。 - 第三步:将 Buffer Pool 中的数据读取到
redo log之中。 - 第四步:用户发起修改数据请求,MySQL 数据库首先修改内存(Buffer Pool)中的数据。
- 第五步:接着修改
redo log中的数据。 - 第六步:进行数据处理。这里需要着重强调一下,因为有 3 种可能的情况。
- 第 1 种可能:如果事务提交(对应图中第 8 步),则把 Buffer Pool 中的数据刷新到硬盘之中,然后再修改 undo log,进而保证了数据库中各个模块的数据一致性。
- 第 2 种可能:如果事务出现故障(对应图中第 7 步),则使用 redo log 中保存的最新数据还原到 Buffer Pool 中(注意:此时 undo log 和硬盘中的数据并没有修改),此时如果事务提交,则执行第 1 种可能。
- 第 3 种可能:如果事务回滚(对应图中第 6 步),则使用 undo log 中保存的数据修改 Buffer Pool、redo log。
redo log 是一个物理日志,保存在硬盘中,不会因为数据库的故障造成数据丢失;undo log 是一个逻辑日志,保存在内存之中。当数据库故障重启之后,数据库会重新读取磁盘中的数据到 Buffer Pool 和 undo log 之中(注意:此时唯有 redo log 中保存的数据为最新的数据)。
可以看出来,redo log 和 undo log 很是关键,所以下面我们就来详细地说明一下这两个日志文件。
1. redo log 日志
redo log日志是 MySQL 数据中的重要日志之一,其本质是物理日志,存放于 数据库的数据目录中 ,名称为: ib_logfile 。它的功能主要是用于存放脏数据的日志(注:脏数据是数据库中刚产生的还没来得及写入磁盘的新数据),当数据发生故障时保证数据不丢失。 需要说明的是:事务提交时修改磁盘的数据仍然是 Buffer Pool 中的数据,redo log 只是为了保证 Buffer Pool 中新修改的数据不丢失,进而保证事务提交时的数据完整性,不能笼统地认为 redo log 是保存提交的数据的。
为了数据安全,MySQL 数据库在运行的过程中,时时刻刻都在产生 redo log。
新更新的数据会首先写入 Buffer Pool 和 redo log 之中,然后当事务提交时才会写入磁盘,也就是说各种数据修改首先统一写入 Buffer Pool 和 redo log 之中,然后再统一写入磁盘。Buffer Pool 中的数据写入磁盘文件是受innodb_flush_log_at_trx_commit控制的,其配置的值为:0、1 和 2。其详细情况如下:
- 当配置为 0 时,主要受 InnoDB 存储引擎中的 Master 线程的周期控制,一般是一秒或十秒刷新一次。
- 当配置为 1 时,一旦事务提交,Buffer Pool 和 redo log 中的数据将立即写入磁盘,此时即便数据库宕机数据也能恢复,比较安全,但是可能会造成一定程度上的延时。
- 当配置为 2 时,事务提交,数据不会立即写入磁盘,此时如果数据库宕机,则可能会丢失部分数据,优点就是性能比较高。但是每次修改数据,redo log 中的数据都会有一个标识,这个标识叫 checkpoint,当数据库发生宕机时,数据是从最近的 checkpoint 中恢复数据的,最大程度减少数据丢失。
数据库中的innodb_flush_log_at_trx_commit的值可以使用下方的方法查询:
mysql> show global variables like 'innodb_flush_log_at_trx_commit';+--------------------------------+-------+| Variable_name | Value |+--------------------------------+-------+| innodb_flush_log_at_trx_commit | 1 |+--------------------------------+-------+1 row in set (0.01 sec)
2. undo log 日志
undo log 是 MySQL 数据库中另一个重要的日志之一,其本质是一个逻辑日志,存放于 MySQL 数据库的表空间之中,也就是内存之中。它的主要作用是用于数据回滚。
当发了红包时,如果数据库恰巧发生故障,为了保证数据的安全(及修改的数据不会只修改一部分),就需要使用到数据的回滚,这时 undo log 日志就派上了用场。
那么你知道undo log是怎么回滚日志的吗?对于数据恢复来说,主要有两种方式,分别是:物理恢复和逻辑恢复,那么undo log就是通过逻辑恢复的方式恢复数据。例如:宋押司发给李逵的红包,发现心有不甘,于是撤回。那么这个过程之中先是INSERT或者UPDATE,将宋押司的 50 块钱INSERT或者UPDATE给李逵,撤回则是将INSERT或者UPDATE转换成DELETE和UPDATE的过程。
上文中我们说了,数据库的事务具有持久性等四个特性,所以一旦事务提交,undo log 中保存的数据也就随即不再需要。但是,此时 undo log 中保存的数据并不是立即删除,而是像垃圾一样丢弃到数据库中的 undo 链表之中,而后由 MySQL 之中的 purge 线程统一清理删除,这个做法避免了其他事务回滚造成数据错误,同时也提高了数据库的性能。
总结
好了,以上就是我们今天关于 MySQL 数据库事务的相关内容,这里我来一个简单的总结。
MySQL 数据库的事务主要是由redo log和undo log来实现的,这是我们理解 MySQL 事务原理的关键所在。
redo log是在事务执行之前才产生的,并且在事务执行过程中,redo log也是不断产生,当产生的脏数据全部都写入磁盘之后,redo log随即也就完成了它的使命。undo log是在事务执行之前产生的,事务回滚时使用undo log日志中的数据覆盖新修改的数据,进而达到事务回滚的效果。需要注意的是,undo log回滚数据之后并不是立即删除的,而是由purge线程去探测可还有其他的事务正在使用该undo log日志,如果有,则保留,给予其他的事务来使用;如果没有,才会清除该undo log,释放空间。
当我们在使用数据库的过程中,如果所有的修改操作都是用事务的话,会造成很大的资源浪费,降低数据库性能。例如,用户浏览日志等数据,这样的数据对于安全性要求并不高,也就是说丢失一两条对整体没有任何影响的,所以我个人不建议使用事务,避免资源浪费,降低 MySQL 数据库的性能。但是,在有金钱交易的场景中,为了保证数据的安全性,必须使用事务!!! 所以说,要结合我们使用的场景“对症下药”。
如果你有什么问题或者好的想法,欢迎你在留言区与我分享,我们一起交流和进步。
